© 2004 Электронный журнал "Jahrbuch fur EcoAnalytic und EcoPatologic"
На главную страницу сайта
Сайт наш чаще посещай - будет выше урожай (Лозунг времен Н.С.Хрущева)
|
© 2004 Электронный журнал "Jahrbuch fur EcoAnalytic und EcoPatologic" |
|
Опубликовано в сборнике "Проблемы экологического эксперимента (планирование и анализ наблюдений)"
![]() Скачать полный текст сборника в формате PDF (3.5 Мбайт)
Скачать полный текст сборника в формате PDF (3.5 Мбайт)
УДК 577.1 : 519.7
ЭНТРОПИЙНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ (ЭДА) : МЕТОД СРАВНЕНИЯ НЕСКОЛЬКИХ ГРУПП С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИОННОГО ИНДЕКСА ШЕННОНА
С.С. Крамаренко
Николаевский государственный аграрный университет
e-mail: KSSNAIL@rambler.ru
В нашем первом сообщении (2005) была показана возможность использования энтропийно-информационного анализа (ЭИА) для оценки изменчивости количественных признаков (прежде всего, биологических объектов), имеющих нормальное или близкое к нему распределение (Крамаренко, 2005). Однако, при анализа многочисленных материалов очень часто возникает задача оценить достоверность различий полученных оценок энтропии (в экологических исследованиях - индекса Шеннона-Уивера) в двух или более выборках с последующим вычислением уровня значимости полученных различий.
Первая задача, т.е. сравнение оценок энтропии в двух выборках, была решена еще в 1969 г. в статье Баумена с соавторами (Bowman et al., 1969). В этой работе для проверки нулевой гипотезы предлагалось использовать следующий критерий:
|
|
(1) |
где H1 и H2 – выборочные оценки энтропии в двух сравниваемых совокупностях, а Var(H1) и Var(H2) – их вариансы. Оценку вариансы энтропии для соответствующей выборки можно получить по следующей формуле:
|
|
(2) |
где n – объем выборки; s – число альтернативных состояний системы или групп элементов в выборке.
Показано, что критерий (1) может быть аппроксимирован распределением t-критерия Стьюдента с числом степеней свободы:
|
|
(3) |
где n1 и n2 – объемы сравниваемых выборок.
Ниже предложен алгоритм сравнения более чем двух выборок одновременно в отношении оценок энтропии. Этот алгоритм подобен алгоритму дисперсионного анализа с разложением суммарной изменчивости комплекса на межгрупповую компоненту и остаточную, поэтому данная методика может быть названа “энтропийный дисперсионный анализ” (ЭДА).
Предложим, что имеется k групп (т.е. выборок) объектов с соответствующими объемами Ni, где 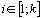 . В каждой группе (выборке) встречаются j типов объектов (т.е видов), где
. В каждой группе (выборке) встречаются j типов объектов (т.е видов), где 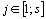 . Тогда исходные данные могут быть записаны в виде таблицы 1.
. Тогда исходные данные могут быть записаны в виде таблицы 1.
Для каждой включенной в анализ выборки, а также для суммарных данных рассчитываются соответствующие оценки энтропии:
|
|
(4) |
|
|
(5) |
Таблица 1
|
Типы объектов |
Выборки |
Суммы |
||||
|
1 |
2 |
3 |
… |
k |
||
|
1 |
m 11 |
m 21 |
m 31 |
… |
mk 1 |
n 1 |
|
2 |
m 12 |
m 22 |
m 32 |
… |
mk 2 |
n 2 |
|
3 |
m 13 |
m 23 |
m 33 |
… |
mk 3 |
n 3 |
|
… |
… |
… |
… |
… |
… |
… |
|
s |
m 1s |
m 2s |
m 3s |
… |
mks |
ns |
|
Суммы |
N 1 |
N 2 |
N 3 |
… |
Nk |
N |
Затем необходимо рассчитать следующие величины (в дисперсионном анализе они соответствуют суммам квадратов):
|
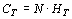 , , |
(6) |
|
|
(7) |
|
|
(8) |
Следующим этапом расчетов будет отнесение полученных величин к соответствующим числам степеней свободы (в дисперсионном анализе полученные таким образом величины называются средним квадратом):
|
|
(9) |
|
|
(10) |
Тогда показатель, который можно использовать для проверки нуль-гипотезы о равенстве всех оценок энтропии в используемых выборках, рассчитывается по формуле:
|
|
(11) |
где N0 – средняя взвешенная численность объектов в разных группах:
|
|
(12) |
В том случае, если объемы всех сравниваемых выборок равны между собой и составляют 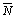 , эта величина и используется в качестве оценки N0 в формуле (11).
, эта величина и используется в качестве оценки N0 в формуле (11).
Показатель
ή варьирует в пределах от 0 до 1. Однако, его оценки в некоторых случаях могут быть меньше нуля. В том случае, если численности объектов разного типа равны или пропорциональны во всех сравниваемых выборках, данный показатель будет равен нулю. И, наоборот, при фиксации объектов разного типа в разных выборках, при равенстве числа выборок и числа типов объектов, и при больших объемах выборок показатель ή будет стремиться к единице.Кроме того, использование показателя
ή, по нашему мнению, имеет некоторое преимущество при сравнении двух выборок перед методом Баумена, поскольку учитывает не только численности отдельных типов объектов в выборке (например, видов при биоценотических сравнениях), но и структуру самих пулов объектов. Например, если в выборке №1 отмечено пять видов с численностями 27, 11, 6, 3 и 1, а в выборке №2 те же пять видов, но с численностями 3, 11, 27, 1 и 6, то метод Баумена даст заключение о том, что нулевая гипотеза не может быть отвергнута, поскольку обе сравниваемые выборки имеют одинаковые пулы абсолютных частот видов. Однако структура сравниваемых биоценозов явно отлична и показатель ή эту разницу отметит.Предлагаемый алгоритм ЭДА может быть использован не только для сравнения оценок энтропии (индекса Шеннона-Уивера) в экологических исследованиях, но и при энтропийно-информационном анализе (ЭИА) количественных признаков. В этом случае с помощью ЭДА можно проверить нуль-гипотезу о том, что разные выборки взяты из одной генеральной совокупности и, соответственно, характеризуются одинаковыми оценками энтропии. Эта проверка касается, прежде всего, характера распределения объектов в анализируемых выборках.
Для проверки данной нулевой гипотезы используются преобразование исходных данных, как описано в нашем первом сообщении (Крамаренко, 2005). При этом преобразование производится на основе обобщенной выборки всех исходных данных. Далее производится процедура классификации объектов, в результате чего получаем таблицу кросс-табуляции с организацией исходных данных, как это приведено в таблице 1.
Проверка нулевой гипотезы о равенстве оценок энтропии в сравниваемых выборках, следовательно, можно свести к проверке нулевой гипотезы:
|
|
(13) |
Стандартный метод проверки этой гипотезы, используемый в классическом дисперсионном анализе Р.Фишера, не может быть использован. Во-первых, исходные данные не имеют нормального распределения (а, скорее, распределены по полиномиальному закону), а во-вторых, оценки (9) и (10) по своей сути не являются истинными средними квадратами (вариансами), поэтому их отношение не имеет никакого отношения к F-распределению Фишера-Снедекора.
Более того, закон распределения оценки
ή вообще не известен, поэтому для проверки нулевой гипотезы (13) нужно использовать методы численного ресамплинга (resampling)(Efron, 1982). Из трех различных подходов, которые объединяет численный ресамплинг, наиболее приемлемым для данного случая будет метод перестановок (Permutation procedure). Он заключается в следующем. Особи из исходных выборок, используемых в анализе, с учетом их типа (в нашем случае, с учетом их видовой принадлежности) случайным образом перетасовываются по разным выборкам так, что суммы строк и столбцов в таблице 1 остаются без изменения. Для этой искусственно полученной матрицы данных рассчитывается оценка (11). Она носит название псевдооценки. Данные вновь перетасовываются и вновь рассчитывается соответствующая псевдооценка ή. Эта процедура повторяется еще много раз, например, M. Желательно, чтобы величина M имела порядок нескольких сотен или даже тысяч. Для полученного таким образом вектора псевдооценок подсчитывается, сколько раз эти псевдооценки были равны или превышали значение ή, полученное для матрицы исходных данных, т.е. оценку (11). Пусть это число будет m. Тогда уровень значимости оценки (11) можно рассчитать по формуле:|
|
(14) |
Рассмотрим всю процедуру проведения ЭДА на приведенном ниже примере.
Пример. При анализе четырех проб было отмечено присутствие пяти видов с численностями, представленными в таблице 2. Необходимо проверить нуль-гипотезу о том, что эти выборки отобраны из одной генеральной совокупности (т.е. из одного биоценоза) и, соответственно, характеризуются сходным распределением видов и одинаковыми оценками индекса Шеннона-Уивера.
Таблица 2
|
Виды |
Выборки |
Суммы по видам |
|||
|
1 |
2 |
3 |
4 |
||
|
A |
15 |
8 |
4 |
9 |
36 |
|
B |
5 |
5 |
1 |
6 |
17 |
|
C |
2 |
7 |
6 |
4 |
19 |
|
D |
5 |
6 |
5 |
4 |
20 |
|
E |
8 |
2 |
4 |
17 |
31 |
|
Суммы по выборкам |
35 |
28 |
20 |
40 |
123 |
Вначале рассчитаются частоты встречаемости каждого вида для каждой выборки и для их сумм в целом. Далее, на основе этих частот рассчитаются индексы Шеннона-Уивера (таблица 3).
Таблица 3
|
Виды |
Выборки |
Средние частоты |
|||
|
1 |
2 |
3 |
4 |
||
|
A |
0,4286 |
0,2857 |
0,2000 |
0,2250 |
0,2927 |
|
B |
0,1429 |
0,1786 |
0,0500 |
0,1500 |
0,1382 |
|
C |
0,0571 |
0,2500 |
0,3000 |
0,1000 |
0,1545 |
|
D |
0,1429 |
0,2143 |
0,2500 |
0,1000 |
0,1626 |
|
E |
0,2286 |
0,0714 |
0,2000 |
0,4250 |
0,2520 |
|
Индексы Шеннона-Уивера (H) |
2,0487 |
2,2084 |
2,1660 |
2,0838 |
2,2569 |
|
Hi·Ni |
71,7045 |
61,8352 |
43,3200 |
83,3520 |
277,5987 |
В последней строке таблицы 3 приведены произведения оценок индекса Шеннона-Уивера на объемы соответствующих выборок или, для последнего столбца, на суммарный объем комплекса.
Таким образом, по формулам (6)-(8) находятся величины:
|
CT = 2,2569·123 = 277,5987; |
|
CR = 71,7045 + … + 83,3520 = 260,2117; |
|
CA = 277,5987 – 260,2117 = 17,3870. |
Далее, используя формулы (9) и (10) рассчитываются оценки, аналогичные средним квадратам:
|
|
|
|
Объемы выборок не равны, поэтому необходимо вначале рассчитать среднюю взвешенную численность объектов в разных группах по формуле (12):
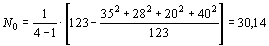 .
.
Наконец, по формуле (11) рассчитывается оценка показателя
ή: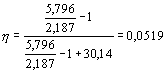 .
.
Для проверки нуль-гипотезы (13) о равенстве полученной оценки нулю используется перестановочный критерий.
(Данная процедура легко реализуется в полу-автоматическом режиме, используя табличный редактор MS Excel и в файле Primer_permutatuion.xls приводится пример реализации данной процедуры для рассмотренного ниже примера. Все детали можно получить у автора по e-mail: KSSNAIL@rambler.ru).После 500 перестановок в 19 случаях полученная случайным образом псевдооценка
ή превышала величину, рассчитанную для фактических данных. Таким образом, уровень значимости (ошибка II рода) данной величины составляет: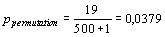 .
.
Это достаточно маленькая величина, поэтому нулевая гипотеза (13) не может быть принята, и, соответственно, можно считать, что исследуемые выборки взяты не из одной генеральной совокупности и различаются в отношении индекса Шенона-Уивера.
С другой стороны, нами было установлено, что распределение псевдооценок
ή имеет близкий к нормальному вид. Поэтому для проверки нуль-гипотезы (13) может быть использован и стандартный двусторонний Z-критерий:|
|
(15) |
где 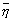 и
и 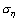 - среднее арифметическое и среднее квадратическое отклонение для вектора псевдооценок.
- среднее арифметическое и среднее квадратическое отклонение для вектора псевдооценок.
В данном примере, для первых 100 псевдооценок показателя
ή среднее арифметическое значение составляло 0,0149 со средним квадратическим отклонением – 0,0182. Поэтому оценка Z-критерия равна: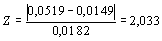 .
.
Поскольку эта величина превышает 1,96, можно считать, что нулевая гипотеза (13) должна быть отвергнута с уровнем значимости p < 0,05.
Точный уровень значимости для данного значения составляет 0,042, что достаточно близко, к оценке, полученной выше при использовании перестановочного критерия.
Литература:
Крамаренко С.С., 02.09.2007 г.
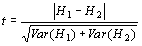 ,
,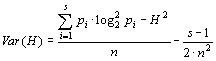 ,
,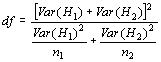 ,
,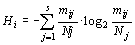 ,
,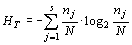 .
.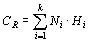 ,
,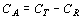 .
.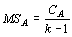 ,
,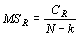 .
.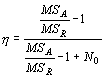 ,
,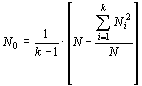 .
.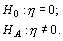
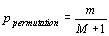 .
.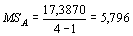 ,
,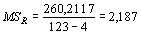 .
.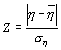 ,
,