| Назад
|
Конец |
Список
|
На главную
|
3.2. СОВРЕМЕННЫЕ ПОДХОДЫ К СТАТИСТИЧЕСКОМУ АНАЛИЗУ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
В.К. Шитиков, Г.С. Розенберг, С.С. Крамаренко, В.Н. Якимов
Таблицы переменных и задачи их обработки
Как много жизни, полной пыла, страстей и мысли,
глядит на нас со статистических таблиц
При проведении научного исследования в изучаемой системе S выделяется некоторая совокупность объектов А, отвечающих исходным предпосылкам проверяемой научной теории. Далее, в соответствии с имеющимися априорными представлениями, специфицируется набор свойств (или признаков объектов), с помощью которых предполагается отличать одни объекты от других той же природы. По результатам эмпирических наблюдений любому объекту а из S можно сопоставить вектор х в пространстве признаков X: (х1, ..., xj, ..., хп). Для каждого признака xj определена область его значений Dj (j = 1, ..., п) и указан тип шкалы, в которой он измерен. В спецификации такого набора измеряемых свойств состоит первый шаг планирования эксперимента.
Статистический анализ полученных данных можно разделить на два типа: первичный и вторичный. Первичный анализ данных проводится для проверки предположений исследователя, которые возникли у него до начала проведения эксперимента. Вторичный анализ {post hoc} проводится для поиска неизвестных заранее закономерностей в данных. Практически всегда у исследователя возникает соблазн проанализировать с большим трудом полученные данные всеми возможными способами. Здесь необходимо подчеркнуть, что такой анализ обычно носит исследовательский характер и не отвечает на вопросы (т.е. не проверяет гипотезы) исследователя, а ставит их (т.е. выдвигает новые плодотворные гипотезы).
Главной и неотъемлемой предпосылкой анализа любого типа является представление и хранение собранных данных в стандартизированной форме – в виде эмпирических таблиц, элементы которых есть результаты измерений ряда признаков у подмножества объектов А, выбранных из некоторого множества S. В дальнейшем разумно считать понятия данные и таблицы синонимами, полагая, что все собранные материалы исследователь хранит в виде таблиц. В стандартной эмпирической таблице типа "объект - признак" по традиции в каждой строке представлен индивидуальный объект наблюдения aÎ A, а в столбцах перечисляется множество свойств или признаков X. Разумеется, таблица данных может содержать информацию как о различных объектах или явлениях, так и о состоянии одного и того же объекта, но в разных ситуациях или в разные моменты времени.
Отметим характерные особенности данных, представленных в таблицах:
Существуют и другие типы специфических таблиц, например, квадратная и симметричная относительно главной диагонали матрица коэффициентов взаимного сходства сравниваемых объектов, рассчитанная с использованием какой-то метрики (евклидова расстояния, коэффициентов Съеренсена, корреляционных мер и проч.). Здесь понятие объекта и его признака становятся идентичными. Можно привести еще пример, где отношения между понятиями объекта и признака объекта вообще несколько запутываются. Такой "неправильной" таблицей является матрица связности графа трофических отношений между группами животных. В строках такой таблицы стоят виды-хищники, а в столбцах – те же виды (или их таксоны), но играющие роль субъектов питания. На пересечении соответствующей строки ("кошки") и столбца ("крысы") в ячейке таблицы указывается доля "крыс" в рационе "кошек", а при обратном порядке строки и столбца – доля "кошек" в рационе "крыс".
Нетрудно заметить, что некоторые признаки, представленные в таблицах, могут являться результатом математической обработки других признаков. Например, суммарная численность фитопланктона определяется простым суммированием численности сине-зеленых водорослей и остальных таксономических групп. Иногда возникает вполне обоснованный вопрос о целесообразности включения латентных (порождаемых из других, изначально "скрытых") признаков в таблицы данных наряду с натурально измеряемыми показателями.
Эпистемологические проблемы, возникающие при анализе природы и обоснованности существования явных и латентных признаков, можно разделить на три группы. Во-первых, если смысл латентных переменных не обнаруживает себя непосредственно, не являются ли они искусственно сконструированными собирательными понятиями – этикетками для несуществующих вещей? Если да, то нельзя ли произвести "санитарную" очистку языка экологии от вымышленных гипотез или индексов и оперировать только "реальными" терминами? Во-вторых, само разграничение признаков на явные и латентные условно и относительно, поскольку при ближайшем рассмотрении явная переменная оказывается латентной, т.е. обнаруживает себя опосредованно, в своих "видимостях". Строго говоря, явных переменных как таковых вообще не существует. В-третьих, явные переменные, кажущиеся вполне реальными, часто не обладают смыслом собственного существования, а светят отраженным светом глубинных сущностей. Например, вполне реальный показатель "ученое звание" являет миру латентную переменную, которую можно обозначить как "компетентность". Однако выдающийся биолог Н.В. Тимофеев-Ресовский не был не только профессором, но не имел даже высшего образования.
После заполнения таблиц данных результатами эксперимента появляется возможность ответить на традиционно ключевые вопросы многомерного анализа экосистем:
Разумно предположить, что под статистической обработкой данных исследователь подразумевает получение некоторого их описания, которое по своей длине существенно меньше, чем простое перечисление тех значений, которое принимают признаки объектов. То есть, в качестве конечного результата необходимо получить лаконичное, наглядное и полезное представление данных в пространстве существенно меньшей размерности. Таким образом, смысл эмпирико-статистического моделирования сводится, в большинстве случаев, к свертке исходных таблиц к матрице меньшего размера по какому-то определенному алгоритму, который выбрал сам исследователь. Например, из одной матрицы n´ m можно изготовить m-мерные векторы средних, медиан, дисперсий и других статистик и проч. Две матрицы можно свернуть в векторы t-критериев Стьюдента, p-вероятностей, различных непараметрических критериев, баллов значимости различий или любых других индексов сходства, принятых с учетом тех или иных соображений. Цель такой свертки матриц данных в векторы состоит лишь в том, чтобы было удобно обосновать на основе анализа строк некоторое логическое умозаключение, которое, как правило, имеет такую формулировку: "большой - маленький", "совпадают - не совпадают", "влияет - не влияет", т.е. проверить ту или иную статистическую гипотезу по существу подмножеств данных.
Особый характер редукции матриц наблюдений в вектор реализуется в ходе множественного регрессионного анализа: если объявить один из столбцов таблицы "объясняемой" переменной y, то можно получить вектор из m - 1 коэффициентов уравнения, позволяющего рассчитывать предполагаемое значение y в зависимости от уровней варьирования остальных признаков. Тем самым можно прогнозировать поведение системы по ее сенсорному звену при изменении внешних возмущающих воздействий, а по величине рассчитанных коэффициентов выполнить сравнительную оценку информационной значимости влияющих факторов. Табличный способ представления данных подчеркивает принципиальную многовариантность выбора отклика. В качестве y можно использовать любой столбец таблицы (или любую их комбинацию), гибко варьируя процесс генерации формальных гипотез о процессах и связях в экосистеме.
Матрицы исходных данных n´ m могут быть свернуты по строкам не только в векторы, но и в квадратные симметричные таблицы m´ m меньшего размера: матрицы ковариаций, корреляций или расстояний с использованием разнообразных метрик. С использованием различных дополнительных процедур эти промежуточные матрицы могут быть трансформированы в различные картинки – графы, дендрограммы, кластерные диаграммы и проч. Цель такой визуализации заключается в том, чтобы на полученном изображении некоторым оптимальным образом были видны основные закономерности, присущие набору данных: его кластерная структура, изначальное разделение данных на классы (если таковое имеется), существование различных зависимостей между признаками и т.д.
Кроме подходов, основанных на свертке таблиц данных по строкам, важнейшим этапом структурного анализа экосистем является уменьшение количества столбцов или снижение размерности признакового пространства (m ® k, m > > k). Извлечение полезной информации при ответе на этот вопрос, как правило, ведется в двух направлениях (впрочем, не вполне независимых друг от друга):
Традиционно всегда полезно иметь возможность представить многомерное облако данных в виде наглядной двумерной картинки, т.е. снизить размерность облака до двух измерений. Преследуя эту цель, мы, с одной стороны, ограничиваем точность описания, а с другой – даем возможность создать себе наглядный образ набора данных, с помощью которого можно анализировать их структуру, практически не прибегая к иным методам, кроме визуализации (Зиновьев, 2000).
Применение каждого метода обработки таблиц на практике сопровождается определенным ритуалом – обращением к строгим методическим принципам и терминам, целесообразность использования которых определяется лишь общепринятостью [термин использован А.Н. Горбанем и Р.М. Хлебопросом (1988)]. Например, исследователь, получив некоторый набор точек данных, в первую очередь считает среднее арифметическое координат этих точек и дисперсию – разброс около среднего, т.е. статистики нормального распределения. Исследователь, как правило, осознает, что распределение реальных данных может оказаться далеким от нормального и среднее значение точек облака может находиться вовсе вне области скопления данных, но делает это отчасти потому, что "так положено", отчасти чтобы представить себе данные "в первом приближении". Другим похожим ритуалом является проверка эффекта воздействия по критериям значимости (см. гл. 1), хотя разработано много других методов точного и корректного решения этой задачи.
Важную часть ритуала составляют "заклинания" (другой термин, использованный А.Н. Горбанем и Р.М. Хлебопросом) – устойчивые словесные формулировки, которыми сопровождается ритуал. Рекламные заклинания, вроде “фракталы описывают всю вертикаль реально существующего самоподобия структур” или “самоорганизующиеся карты Кохонена сохраняют топологические особенности набора данных”, являются эффективным средством выделить метод среди аналогичных и продвигать его на конференциях, демонстрируя отдельные полученные блестящие результаты. В рекламных заклинаниях, как правило, нет прямого обмана, но к ним всегда следует относиться осторожно, поскольку текущая реализация метода всегда сопровождается определенными оговорками. Технологические заклинания (“мы сделали это, потому что это вытекает отсюда”) призваны создать у окружающих впечатление того, что исследователь на своем пути строго следовал логически оправданным методологическим установкам. Хотя, как правило, реальный путь исследования был слишком извилистым, чтобы рассказывать о нем в подробностях. К технологическим заклинаниям необходимо относиться также с осторожностью, потому что существенная их часть делается "задним числом" (“раз это сработало – значит это верно”).
Цель двух последних абзацев – предупредить читателя, с чем он неизбежно столкнется на практике и чего необходимо опасаться. Читатель предупрежден – и мы следуем дальше, чтобы остановиться на обзоре некоторых методов статистической обработки данных, получивших признание в последние десятилетия.
Онтология анализа данных
Постулат Персига: Число разумных гипотез,
объясняющих любое данное явление, бесконечно.
Актуальной стратегией современного научного исследования является переход от оценки отдельных “воздействий в разовом эксперименте” по Р. Фишеру и С. Хелберту к обработке массивов постоянно пополняемых и расширяемых данных с целью создания адекватных многофункциональных моделей изучаемых экосистем. Время "лоскутной экологии" стремительно проходит, уступая комплексному (сейчас говорят "системному") подходу к описанию процессов и явлений. Именно информационные технологии создают предпосылки для построения адаптируемых моделей, шаг за шагом улучшающихся по мере поступления новых экспериментальных данных или расширения "сферы влияния" модели.
Современные информационные технологии предполагают размещение таблиц в сконцентрированном виде в хранилищах данных (Барсегян и др., 2004). В этих системах разрозненная информация представляется в виде многомерного куба, которым можно легко манипулировать, извлекая срезами нужную информацию. По осям гиперкуба размещаются параметры, определяющие предметную, пространственную или временную принадлежность элемента данных, а в ячейках на пересечении осей измерений {dimension} располагаются результаты непосредственных наблюдений. Использование такой модели данных позволяет организовать эффективную работу с ними – генерировать регулярные и произвольные запросы различной сложности, выделять необходимые подмножества, создавать прямой интерфейс с математическими пакетами прикладных программ и т.д.
Технология комплексного многомерного анализа данных и представления результатов в удобной графоаналитической форме получила название OLAP (On-Line Analytical Processing). При этом над многомерной моделью-гиперкубом могут проводиться следующие операции: среза {splice}, вращения {rotate}, детализации {drill down} и консолидации {drill up}, т.е. отображения информации в виде сводной кросс-таблицы. Эти основные приемы OLAP-технологий не являются предметом глубокого анализа (например, прогнозирования): исследователь использует компьютер только как средство извлечения данных, а выводы делает уже самостоятельно, руководствуясь либо инструкцией (например, каким образом можно реализовать механизмы реагирования на отклонения), либо интуицией. Для проверки сложных гипотез и решения стратегических проблем используется аппарат извлечения знаний из баз данных {knowledge discovery in databases} – рис. 1, основой которого является генерация продуктивных гипотез (Data Mining – или дословно "добыча данных"). Гипотезой в этом контексте будем считать любое предположение о влиянии определенных факторов на исследуемую нами систему, которое является нетривиальным, практически полезным и доступным для интерпретации. Здесь OLAP-технологии играют роль семантического слоя.

Рис. 1. Общая структурная схема работы информационно-аналитической системы
Data Mining, как ее достаточно точно определяет Г. Пиатецкий-Шапиро (Piatetsky-Shapiro), “это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей”. Процесс извлечения продуктивных гипотез из данных происходит по стандартной схеме установления физических законов: сбор экспериментальных данных, организация их в виде таблиц и поиск такой схемы рассуждений, которая, во-первых, делает полученные результаты очевидными и, во-вторых, дает возможность предсказать новые факты. При этом имеется ясное понимание того, что наши знания об анализируемом процессе, как и любом экологическом явлении, в какой-то степени приближенные.
Традиционными являются попытки разделить методы Data Mining на описательные и прогнозирующие. Описательные методы должны приводить к объяснению или улучшению понимания данных. Ключевой момент в таких моделях – легкость и прозрачность восприятия исследователем получаемых результатов. К таким задачам относятся классические методы проверки статистических гипотез, кластеризация и поиск ассоциативных правил - рис 2.
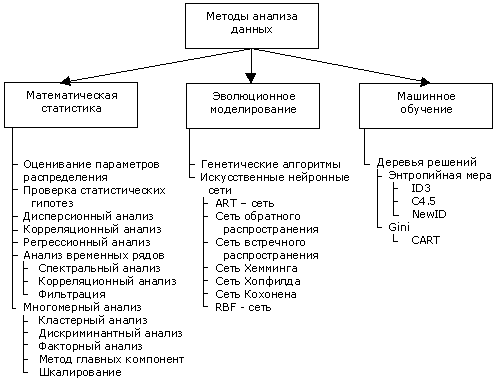
Рис. 2. Основные алгоритмы генерации продуктивных гипотез (Data Mining)
(по материалам сайта лаборатории "BaseGroup" -
http://www.basegroup.ru/)
Задачи прогнозирования решаются в два этапа: на основании данных с известным исходом строится модель, которая на втором этапе используется для предсказания результата на "свежих" данных. Г.С. Лбов (1981), например, выделяет следующие типы задач эмпирического прогнозирования:
В конечном итоге большинство задач анализа данных можно свести к задаче выбора функции y (xi), доставляющей минимальную степень ошибки:
 , (1)
, (1)
где Y - множество всех возможных функций; С[y, y (xi)] – функция потерь {loss function}, в которой y (xi) - значение зависимой переменной, найденное с помощью функции y для вектора xi, а y - ее точное (известное) значение. Например, для бинарной классификации (принадлежности объекта к одному из двух классов) простейшая функция потерь в случае неправильного предсказания принимает значение 1 и 0 – в противном случае. Ситуация усложняется при числе классов более двух. Каждый тип ошибки классификации вносит свой тип потерь и в общем случае получается матрица стоимостей ошибок k´ k (где k – число классов). В задачах регрессии чаще всего применяется минимизация квадратов разностей y (xi) - yi , что соответствует наличию аддитивного нормально распределенного шума, влияющего на результаты наблюдений yi. Впрочем, Д. Пуарье (1981) показал, что более устойчивые оценки получают не минимизацией квадратов разностей, а минимизацией степени 1.6 разностей, т.е. min (y(xi) - yi)1.6 !
Для решения задач, связанных с анализом данных при наличии случайных и непредсказуемых воздействий, математиками и другими исследователями за последние 200 лет был выработан мощный и гибкий арсенал методов, называемых в совокупности математической статистикой. Теоретические аспекты и прикладные проблемы ее использования широко описаны в литературе (в том числе, в наших двух монографиях: Розенберг и др., 1994; Шитиков и др., 2005). Подробная библиография применения прикладной статистики в экологических исследованиях приведена в сборнике “Количественные методы…” (2005).
В то же время следует отметить появление и развитие новых разделов прикладной статистики, полезных при обработке данных экологического эксперимента. К числу таких можно отнести статистику нечисловых и интервальных данных (Орлов, 2006). Объектами нечисловой природы называют элементы пространств, не являющихся линейными, т.е. их нельзя складывать и умножать на числа, не теряя при этом содержательного смысла. Примерами являются порядковые отношения (ранжировки, разбиения, классы), списки наименований, последовательности символов (тексты). В последние десятилетия подробно рассмотрены вероятностные модели конкретных объектов нечисловой природы (в частности, модели парных сравнений), проработана статистика бинарных отношений и бернуллиевских векторов, осуществлено аксиоматическое введение метрик и многомерное шкалирование. Одним из объектов нечисловой природы являются нечеткие множества, теория которых разработана Л.А. Заде (L. Zadeh), а практические приложения дали ощутимый научно-технический эффект, в том числе и в области биологии.
В статистике интервальных данных элементы выборки – не числа, а интервалы (например, х лежит в отрезке [a,b], а у – в отрезке [c,d]). Это приводит к основным идеям и подходам асимптотической статистики, принципиально отличающимся от классических. В отношении интервальных данных также рассмотрен ряд задач оценивания характеристик и параметров распределения, проверки гипотез, регрессионного, кластерного и дискриминантного анализов. По сути, речь идет о формировании математической теории объектов произвольной структуры, позволяющей получать "на выходе" исследования все виды статистических моделей, привычных для классического случая: ранжировки, кластеры, дихотомический анализ (принять или не принять гипотезу), модели регрессии и т.д. Результатом статистической обработки может быть и множество (например, зона наибольшего поражения экосистемы при катастрофическом воздействии). Поскольку результат наблюдения за состоянием объекта часто представляет собой вектор признаков смешанной природы, часть координат которого измерена в шкале наименований, другая часть – в порядковой шкале, еще часть – по шкале интервалов и т.д., то активно развиваются методы обработки разнотипных данных.
В последнее время активно развиваются новые методы анализа данных и извлечения знаний, основанные на иных подходах, нежели традиционная теоретико-статистическая парадигма. Имеются в виду такие методы искусственного интеллекта, как эволюционное моделирование и методы машинного обучения. Термин "эволюционное моделирование" в настоящее время является достаточно устоявшимся. Под этим термином подразумевают различные методы синтеза конечных автоматов, генетические алгоритмы и искусственные нейронные сети. Термин "машинное обучение" оставляет больше возможностей для дискуссий о том, какие методы имеются в виду; в частности, сюда относятся деревья решений и ассоциативные правила. Достаточно полная спецификация методов и алгоритмов искусственного интеллекта и примеры их использования представлены в монографии (Шитиков и др., 2005). Значительная часть описанных ниже средств анализа данных представлена в виде удобных и быстрых в эксплуатации программных модулей аналитического пакета Deductor Professional (http://www.basegroup.ru/).
Методами эволюционного моделирования решается широкий класс задач: классификация образов, кластеризация, аппроксимация, прогноз данных, оптимизация, ассоциативная память, управление динамическими объектами. Основными инструментами эволюционного моделирования являются генетические алгоритмы и искусственные нейронные сети. Если в основе классических подходов лежат формализованные каким-либо образом знания человека о предметной области, то для нейронной сети аналитическая форма представления знаний недоступна: все что она может – это запомнить и обобщить предъявленные ей на этапе обучения эмпирические таблицы, содержащие входные факторы и результирующие значения. То есть, нейронная сеть строит модель изучаемого процесса и в дальнейшем воспроизводит его поведение, причем настроенная модель может быть легко дообучена с учетом вновь поступивших данных. Это дает повод некоторым исследователям утверждать, что искусственные нейросети моделируют свойственные человеку приемы мышления. По нашему мнению, для практического использования нейросетевых технологий вполне достаточно того обстоятельства, что нейросети в состоянии строить сложные нелинейные модели процессов (Шитиков и др., 2002). Важно другое – качество модели зависит от качества обучающих данных (тут все как у людей). Нейронные сети по своей природе являются универсальными аппроксиматорами и позволяют моделировать очень сложные закономерности, что недоступно, скажем, классическим регрессионным моделям. Однако при использовании нейронных сетей мы должны очень осторожно подходить к вопросу о входных полях (с ростом количества обрабатываемых переменных, увеличивается время, затрачиваемое на процесс обучения, который может оказаться очень долгим).
Генетические алгоритмы используют механизмы генетической эволюции, которые в общем виде могут быть сформулированы так: чем выше приспособленность особи, тем выше вероятность того, что в его потомстве эта приспособленность будет выражена еще сильнее. Трактовка процесса приспособления как оптимизационного процесса приводит к идее использования генетических алгоритмов при обучении нейронных сетей (Шитиков и др., 2005). Причем если градиентные методы обучения гарантируют нахождение локального минимума, то генетический алгоритм обеспечивает глобальную оптимизацию.
Существуют нейросетевые парадигмы, например, самоорганизующиеся карты Кохонена (SOM), в которых процесс обучения происходит без учителя, т.е. сеть сама разбирает структуру данных (Количественные методы…, 2005). SOM-карты являются мощным инструментом ординации объектов, объединяющим в себе две основные парадигмы анализа – кластеризацию и проецирование, т.е. визуализацию конфигурации объектов на плоскости. Каждая карта представляет собой отображение облака исходных многомерных данных на экране, имеющим вид двумерной координатной сетки с шестиугольными ячейками. В узлах сетки располагаются нейроны, которые в ходе настройки нейронной сети перемещаются таким образом, чтобы метрической близости векторов исходных объектов соответствовала бы топологическая близость узлов на экране (рис. 3). Цвет и расположение фрагментов сетки используется для анализа закономерностей, связываемых с компонентами набора данных.
Другим современным подходом к кластеризации объектов являются алгоритмы типа fuzzy C-Means (Барсегян и др., 2004). Их отличие состоит в том, что кластеры являются нечеткими множествами и каждый объект принадлежит различным кластерам с разной степенью толерантных отношений (см. рис. 3). Другой алгоритм кластеризации Гюстафсона-Кесселя ищет кластеры в пространстве нечетких множеств в форме эллипсоидов, что делает его более гибким при решении различных задач.
|
|
|
Рис. 3
. Вид признакового пространства после наложения карты Кохонена (слева)и форма кластеров в алгоритме fuzzy C-Means (справа)В арсенал Data Mining успешно и прочно вошли методы распознавания образов и статистическая теория обучения, разработанные В.Н. Вапником и А.Я. Червоненкисом (1974). Алгоритмы классификации и регрессии под общим названием SVM (Support Vector Machines) основаны на предположении о том, что наилучшим способом разделения точек в m-мерном пространстве является гиперплоскость (m-1), заданная функцией y (xi) и равноудаленная от точек, принадлежащих разным классам. Метод "обобщенного портрета", принадлежащий этому семейству, предложен нами для оценки экологического состояния пресноводных водоемов по зообентосу (Шитиков и др., 2004).
Целью методов машинного обучения (Witten, Frank, 2005) является получение простых классифицирующих выражений, которые выявляют закономерности между связанными событиями и были бы легко понятны исследователю. Примерами такой закономерности служит правило, указывающее, что из события X следует событие Y, или другие логические конструкции, представленные в виде "если..., то...".
Деревья решений (иерархические классификационные деревья) – один из таких методов автоматического анализа данных. Они позволяют представлять правила в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. В исследовании, проведенном в рамках европейского проекта StatLog, был сделан сравнительный анализ статистических методов (дискриминантый анализ, кластер-анализ и т.д.), деревьев решений (C4.5, AC2, CART, NewID, CN2, Itrule и т.д.) и нейронных сетей (многослойные сети, РБФ-сети, карты Кохонена) для решения задач классификации. Данные были взяты из различных предметных областей: распознавание образов, медицинская диагностика, молекулярная биология, выдача кредитов и т.д. В ходе исследования выяснилось, что деревья решений показали наилучшие результаты в целом ряде тестовых задач. Применению деревьев решений в фитоценологии мы отводим ниже специальный подраздел.
Ассоциативные правила также позволяют находить закономерности между связанными событиями. Первый алгоритм поиска ассоциативных правил, названный AIS, был разработан в 1993 г. сотрудниками исследовательского центра IBM Almaden, после чего интерес к этим разработкам не угасал и каждый год появлялось несколько алгоритмов. Ассоциативные правила имеют следующий вид:
если <условие> то <результат>,
где, в отличие от деревьев классификации, <условие> – не логическое выражение, а набор объектов из множества А, с которыми связаны (ассоциированы) объекты, включенные в <результат> данного правила. Например, ассоциативное правило { если (вид_1, вид_2) то (вид_3) } означает, что если в биотопе встретились вид_1 и вид_2, то там же предположительно встретится и вид_3.
Выделяют три вида правил:
При поиске ассоциативных правил обычно используются два этапа:
Для оценки полезности и продуктивности перебираемых правил используются различные частотные критерии, анализирующие встречаемость кандидата в пуле транзакций (комбинаций наборов признаков, выбранных для анализа):
Как уже отмечалось, существует целое семейство алгоритмов синтеза ассоциативных правил, из которых наиболее известен алгоритм “Apriori” (Agrawal, Srikant, 1994), который использует одно из свойств этих критериев: поддержка любого набора признаков не может превышать минимальной поддержки любого из его подмножеств.
В отличие от физических систем, где основной задачей является оптимизация вектора результирующих параметров Y путем подбора управляющих воздействий, исследование экосистем заключается прежде всего в количественной параметризации фундаментального в биологии понятия "норма" Yo и оценки диапазона допустимых значений входных параметров, при которых отклик экосистемы не выходит за пределы гибких адаптационных колебаний Y = Yo ± D Y. Несмотря на бесконечное разнообразие возможных систем и их функций, характер зависимости Y = Y (X) бывает довольно типичным, независимо от предметного содержания исследования. Например, большое число процессов воздействия факторов на экосистему может быть описано логистической (сигмоидальной) моделью, включающей три характерные области: слабой связи (малой чувствительности к внешним влияниям), сильной связи и области насыщения, свидетельствующей, возможно, о кризисных изменениях. В связи с этим все большее распространение получают логистическая регрессия, нейронные сети с сигмоидальной функцией активации и ROC-анализ (Receiver Operator Characteristic) .
ROC-кривые (см. рис. 4) наиболее часто используются для представления результатов бинарной классификации в машинном обучении и диагностике (Zweig, Campbell, 1993). Поскольку классов два (например, зарегистрированы негативные изменения в экосистеме или нет), один из них называется классом с положительными исходами, второй – с отрицательными исходами.

Рис. 4.
Точка "баланса" между чувствительностью и специфичностью на ROC-кривойОбъективная ценность любого бинарного классификатора определяется двумя показателями: чувствительностью и специфичностью модели. Чувствительность {sensitivity} – доля распознанных истинно положительных случаев, а чувствительный диагностический тест проявляется в гипердиагностике – максимальном предотвращении пропуска отрицательных исходов. Специфичность {specificity} – доля истинно отрицательных случаев, которые были правильно идентифицированы моделью, а специфичный диагностический тест оптимизирован на диагностику патологических ситуаций (например, если гипердиагностика не желательна из-за побочных эффектов). ROC-кривая показывает зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров. При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр называют порогом, или точкой отсечения {cutt-off value}, в зависимости от которого будут получаться различные величины ошибок I и II рода (см. рис. 4).
Анализ кривых полноты и точности детерминационных правил давно и с успехом используется коллективом авторов (Булгаков и др., 2003) для индикации состояния природных экосистем и нормирования факторов окружающей среды.
Некоторые из вышеупомянутых методов анализа данных будут рассмотрены ниже более подробно.
Объединение результатов нескольких исследований (мета-анализ)
Закон Фелдсона: Кража идей у одного человека – плагиат,
кража у многих – научное исследование.
Достаточно часто результаты исследований, в которых оценивается эффект воздействия одного и того же внешнего фактора в сходных условиях и на аналогичные экосистемы, в той или иной мере различаются. В связи с этим возникает необходимость относительной оценки результатов разных исследований и интеграции их результатов с целью получения обобщающего вывода.
Целью мета-анализа является выявление, изучение и объяснение различий (вследствие наличия статистической неоднородности или гетерогенности) в множественных результатах исследований, а также более точная оценка изучаемого эффекта воздействия (Glass, 1976; Реброва, 2002; Sinha et al., 2006). В мета-анализе (термин предложен Дж. Глассом, 1976) могут быть математически объединены два и более исследования, целью которых является проверка одной и той же гипотезы.
Существуют два основных подхода к выполнению мета-анализа.
Идеальной моделью является анализ по первичным данным для каждого объекта наблюдения, т.е. объединение баз данных каждого исследования и последующая статистическая обработка de novo. Очевидно, что это далеко не всегда выполнимо, поскольку создание хранилищ экспериментальных данных находится на первоначальном этапе своего развития.
Второй (и основной) подход заключается в обобщении опубликованных результатов исследований, посвященных одной проблеме. Такой мета-анализ выполняется обычно в несколько этапов, важнейшими среди которых являются:
Результаты мета-анализа обычно представляются графически (точечные и интервальные оценки величин эффектов для каждого из включенных в мета-анализ исследований; пример на рис. 5).

Рис 5.
Типичное представление данных мета-анализа в диаграмме.Необходимо отметить, что этап определения круга исследований, включаемых в обобщение, является ключевым как в аспекте полноты выявления выполненных работ, так и в отношении формальных критериев оценки их методологического качества. Обоснованность мета-анализа существенно зависит от корректности включенных в него исходных материалов, а также возможных различий исследований по критериям включения и исключения, структуре и составу проведенных манипуляций, контролю качества и т.д., что часто становится источником систематических ошибок обобщенного вывода. Существует также смещение, связанное с преимущественным опубликованием положительных результатов эксперимента (исследования, в которых получены статистически значимые результаты, чаще публикуются, чем те, в которых такие результаты не были получены).
Собственно мета-анализ может осуществляться, например, с использованием пакета прикладных программ (ППП) ReviewManager (RevMan, Cochrane Collaboration, доступен бесплатно по адресу http://www.cc-ims.net/RevMan), который содержит необходимые сервисные модули для оформления обзора и статистические процедуры для выполнения самого мета-анализа.
Формулируя задачу синтеза исследований, необходимо установить две основных отправных точки для применения статистических методов: способ установления эффекта воздействия, о котором должны свидетельствовать обобщаемые показатели, и общий подход к объединению совокупности разнородных данных (используется фиксированная или случайная модель эффектов).
Оценка эффекта воздействия
Вывод о значимости эффекта воздействия обычно делается, чтобы ответить на вопрос: каково соотношение между двумя подмножествами данных X1 и X2? Оценить это можно двумя способами:
Наиболее общие меры различий представлены стандартизованной разностью взвешенных групповых средних значений, стандартизированным различием двух соотношений, различием двух корреляций, показателями отношения шансов, относительного риска или разности рисков в сопоставляемых выборках. Покажем, что во всех перечисленных случаях оценка эффекта воздействия может осуществляться по единой процедуре.
Оценка эффекта воздействия, основанная на средних.
 , где s
– среднее стандартное отклонение совокупности (а именно, среднее от s
12 и s
22). Для оценки s
используются различные выражения выборочной дисперсии S2, основанные на эмпирических выборках объемом n1 и n2 (n1, n2 >> 1), например:
, где s
– среднее стандартное отклонение совокупности (а именно, среднее от s
12 и s
22). Для оценки s
используются различные выражения выборочной дисперсии S2, основанные на эмпирических выборках объемом n1 и n2 (n1, n2 >> 1), например:
 .
.
Тогда выборочная оценка стандартизованной разности будет  , а оценка дисперсии этой разности
, а оценка дисперсии этой разности  .
.
Как всегда в таких случаях, проверка нулевой гипотезы H0: q = 0 против альтернативы H1: q ¹ 0, будет основана на стандартизированной параметрической статистике критерия
 .
.
Оценка эффекта воздействия, основанная на долях.
Пусть доли двух совокупностей (экспериментальной объемом n1 и контрольной объемом n2), которые являются носителем анализируемого признака, составляют p
1 и p
2 соответственно. Тогда оценки величины эффекта воздействия и дисперсии этой величины могут быть рассчитаны, например, по следующим формулам :
 ;
;
 ;
;
 .
.
Оценка приведенных величин легко осуществляется по выборочным данным: p1 = X1/n1; p2 = X2/n2, где X1 и X2 - количество объектов, обладающих необходимым свойством, в случайных экспериментальной и контрольной выборках. Проверка нулевой гипотезы H0: q = 0 против альтернативы H1: q ¹ 0 осуществляется в соответствии с представленной выше статистикой
 .
.
Оценка эффекта воздействия, основанная на коэффициенте j и
отношении шансов.|
X |
Y |
||
|
Да |
Нет |
Всего |
|
|
Да |
P 11 |
P 12 |
P 1* |
|
Нет |
P 21 |
P 22 |
P 2* |
|
Всего |
P *1 |
P *2 |
1 |
Первая мера ассоциированности между X и Y основана на коэффициенте корреляции между двумя бинарными переменными:  . Выборочная оценка j
, основанная на частотах nij, близко связана с классической статистической величиной c
2 = n** j
2. Стандартная ошибка j
, полученная на больших выборках, определяется как
. Выборочная оценка j
, основанная на частотах nij, близко связана с классической статистической величиной c
2 = n** j
2. Стандартная ошибка j
, полученная на больших выборках, определяется как
 .
.
Вторая мера связи между X и Y основана на отношении шансов, называемом иначе cross-product ratio:  , оценка стандартной ошибки которого, выполненная по частотам, равна
, оценка стандартной ошибки которого, выполненная по частотам, равна  .
.
Проверка нулевых гипотез H0: j = 0 и H0: w = 0 против альтернатив H1: j ¹ 0 и H1: w ¹ 0 осуществляется c использованием соответствующих Z- статистик:
 и
и  .
.
Оценка эффекта воздействия, основанная на корреляции может использовать как непосредственно сам выборочный коэффициент корреляции r, так и статистику z, основанную на преобразовании Р. Фишера, стабилизирующем дисперсию:

Объединение статистических гипотез для множества испытаний
Методология объединения результатов повторных независимых испытаний основана на идеях Р. Фишера (1932s) и К. Пирсона (1933s). Ключевым моментом всех методов объединения испытаний является оценка р-значений отклонения нулевых гипотез. Если рассматривать k различных исследований, в которых проверялись гипотезы H0i против Н1i, то общий принцип объединения заключается в проверке глобальной нулевой гипотезы H0: все H0i верны для i = 1, ..., k против альтернативы H1: некоторые из H0i не верны.
Должны быть достигнуты два основных требования к процедуре объединения испытаний:
Выделяют (Sinha et al., 2006) два основных класса объединяющих процедур, основанных на р-значениях. К методам равномерного распределения относятся:
К числу методов преобразования вероятностей относятся обратный нормальный метод С. Стауфера (Stouffer, 1949s), взвешенный метод Стауфера, метод Фишера (1932s) и логит-метод (George, 1977s). Каждый из перечисленных методов удовлетворяет принципу монотонности и поэтому оптимален для любой комбинации испытаний.
Методы обобщения величины эффекта воздействия
Гетерогенность результатов разных исследований при мета-анализе обуславливается следующими источниками:
Целью мета-анализа для непрерывных данных обычно является получение обобщенного эффекта воздействия в виде точечных значений и оценок доверительных интервалов. Предположим, что имеется k независимых исследований, каждое i-е из которых привело к выборочной величине эффекта воздействия Тi, которая является оценкой истинного эффекта q
i. Пусть также выборочная дисперсия  является оценкой дисперсии Ti, i = 1, …, k. Обычно величина Тi основана на случайной выборке размером ni из i-й совокупности или исследования, а при больших выборках Ti распределена по нормальному закону со средним q
i и дисперсией
является оценкой дисперсии Ti, i = 1, …, k. Обычно величина Тi основана на случайной выборке размером ni из i-й совокупности или исследования, а при больших выборках Ti распределена по нормальному закону со средним q
i и дисперсией  .
.
Примем, что q
1 = q
2 = …= q
k = q
, где q
-
обобщенная величина эффекта воздействия. Его оценку получим в результате использования наиболее общего метода взвешенного линейного объединения, обоснованного В. Кохреном (Cochran, 1937s):  , где wi -
неотрицательный вес, назначенный исследованию i.
, где wi -
неотрицательный вес, назначенный исследованию i.
Предположим также, что дисперсия между исследованиями близка к нулю. Тогда для любого набора нестохастических весов минимум вариации var(q ) будет достигнут, если каждому из исследований приписывается вес, обратно пропорциональный дисперсии результата данного исследования:
 . (2)
. (2)
Оценка дисперсии  в этом случае будет равна
в этом случае будет равна  .
.
Наряду с оценкой стандартного отклонения  обобщеннной величины эффекта воздействия (т.е. T) может быть найден доверительный интервал для , аппроксимированный с уровнем вероятности (1 - a
):
обобщеннной величины эффекта воздействия (т.е. T) может быть найден доверительный интервал для , аппроксимированный с уровнем вероятности (1 - a
):
{нижняя граница} = T - za
/2 , {верхняя граница} = T + za
/2
, {верхняя граница} = T + za
/2 .
.
Если вышеупомянутый доверительный интервал не содержит 0, мы отклоняем нулевую гипотезу H0: q = 0 на уровне значимости a в пользу альтернативы H1: q ¹ 0. Ту же проверку мы можем выполнить с использованием Z-статистики
 .
.
Наконец, на первом этапе мета-анализа целесообразно выполнить оценку гетерогенности (статистической неоднородности) результатов эффекта воздействия в разных исследованиях, т.е. нулевой гипотезы H0: q 1 = …= q k = q . Для этого часто используют критерий c 2 с высоким критическим уровнем значимости для повышения статистической мощности (чувствительности) теста:
 .
.
Описанная модель постоянных (фиксированных) эффектов предполагает, что выявляемые различия результатов исследований обусловлены только дисперсией внутри исследований, а дисперсия между исследованиями равна нулю. Иными словами, фиксированная модель исходит из предположения, что все наблюдения основаны на влиянии одной и той же комбинации идентичных факторов, изучаемое вмешательство во всех исследованиях имеет одну и ту же эффективность, а отличие в данных определяется лишь специфическими особенностями первичных единиц, использованных в исследованиях. В пакете прикладных программ ReviewManager такой подход представлен версией метода в интерпретации Н. Мантеля, В. Ханцеля и Р. Пето (Mantel, Haenszel, 1959s; Peto et al., 1985s).
Приведем небольшой пример использования мета-анализа. Пусть на 8 станциях наблюдения р.Байтуган были взяты гидробиологические пробы и по их совокупности рассчитаны значения индекса разнообразия Шеннона H с использованием усредненных численностей особей макрозообентоса каждого вида. Оценку дисперсии каждого частного значения H рассчитаем по формуле (Bowman et al., 1969)
 ,
,
где S - число видов, встречающихся на станции, N - их суммарная численность. Полученные данные представим в табл. 1.
Таблица 1
Значения индекса разнообразия Шеннона Н и оценки дисперсии VH, рассчитанные для станций р. Байтуган по численностям видов макрозообентоса
|
Станция |
Кол-во проб |
Н |
V H |
Станция |
Кол-во проб |
Н |
V H |
|
01 |
5 |
3.15 |
0.00134 |
05 |
4 |
4.82 |
0.00102 |
|
02 |
2 |
3.49 |
0.00189 |
06 |
1 |
1.49 |
0.00215 |
|
03 |
8 |
3.97 |
0.00215 |
07 |
4 |
3.20 |
0.00530 |
|
04 |
3 |
3.93 |
0.00475 |
08 |
1 |
1.71 |
0.00391 |
Поставим задачу найти статистически обоснованные оценки биоразнообразия бентосных сообществ для всей реки. Отметим предварительно, что среднее арифметическое значение Hса = 3.22. Если в формуле (2) положить значения анализируемого эффекта Ti = Hi и оценок дисперсии = VH, то получим обобщенную величину биоразнообразия = 3.47, а оценку ее дисперсии = 0.00026. Задавшись уровнем значимости a
, получим доверительный интервал для :
= 0.00026. Задавшись уровнем значимости a
, получим доверительный интервал для :
 = 3.47 ±
1.96×
0.0161 = 3.44 ¸
3.50.
= 3.47 ±
1.96×
0.0161 = 3.44 ¸
3.50.
Таким образом, вычисленное с использованием мета-анализа оценка биоразнообразия по индексу Шеннона несколько превышает среднее арифметическое значение за счет того, что больший вес придается измерениям с меньшей оценкой дисперсии.
Принципиально другой подход в мета-анализе – когда каждое исследование интерпретируется как эмпирическая выборка измерений случайной величины из общей генеральной совокупности. Модель случайных эффектов предполагает, что эффективность изучаемого вмешательства в разных исследованиях может быть разной, и учитывает дисперсию не только внутри одного исследования, но и между разными исследованиями. В этом случае суммируются дисперсии внутри исследований и дисперсия между исследованиями. В модели случайных эффектов чаще всего применяют метод Р. ДерСимониана и Н. Ларда (DerSimonian, Laird, 1986s).
Существует также ряд других подходов к выполнению мета-анализа: байесовский мета-анализ, кумулятивный мета-анализ, многофакторный мета-анализ, мета-анализ выживаемости (перечисленные методы пока не представлены в ППП RevMan версии 3.0).
Байесовский мета-анализ позволяет рассчитать априорные вероятности эффективности воздействия с учетом косвенных данных. Такой подход особенно эффективен при малом числе анализируемых исследований. Он обеспечивает более точную оценку эффективности воздействия в модели случайных эффектов за счет объяснения дисперсии между разными исследованиями.
Кумулятивный мета-анализ – частный случай байесовского мета-анализа – пошаговая процедура включения результатов исследований в мета-анализ по одному в соответствии с каким-либо принципом (в хронологической последовательности, по мере убывания методологического качества исследования и т.д.). Он позволяет рассчитывать предтестовые (априорные) и послетестовые (апостериорные) вероятности в итерационном режиме по мере включения исследований в анализ.
Регрессионный мета-анализ (логистическая регрессия, регрессия взвешенных наименьших квадратов, модель Кокса и др.) используется при существенной гетерогенности результатов исследований. Он позволяет учесть влияние нескольких характеристик исследования (например, размера выборки, мощности воздействующего фактора, способа его проявления, характеристик экспериментальных единиц и др.) на результаты испытаний воздействия. Результаты такого мета-анализа обычно представляют в виде коэффициента наклона с указанием доверительных интервалов.
Следует заметить, что мета-анализ может выполняться для обобщения результатов не только контролируемых экологических воздействий, но и мониторинговых наблюдений (например, исследований факторов риска). Однако при этом следует учитывать высокую вероятность возникновения систематических ошибок.
Особый вид мета-анализа – обобщение оценок информативности диагностических методов, полученных в разных исследованиях. Цель такого мета-анализа - построение характеристической кривой взаимной зависимости чувствительности и специфичности тестов (ROC-кривой) с использованием взвешенной линейной регрессии.
После получения обобщенной оценки величины эффекта возникает необходимость определить ее устойчивость. Для этого выполняется так называемый анализ чувствительности. Одним из способов его проведения является сопоставление результатов, получаемых в двух моделях – фиксированных и случайных эффектов. Во второй модели результаты обычно бывают статистически менее значимыми. Другой способ анализа чувствительности - исключение того или иного исследования из анализа и пересчет результатов с последующей оценкой гетерогенности результатов по критерию c 2.
Существуют также способы оценки полноты выявления включенных в мета-анализ исследований. Обычно неполнота выявления обусловлена возникновением систематической ошибки, связанной с преимущественным опубликованием положительных результатов исследований (результатов, описывающих статистически значимые различия групп). Для качественной оценки наличия такой систематической ошибки мета-анализа обычно прибегают к построению воронкообразной диаграммы рассеяния результатов отдельных исследований в координатах "величина эффекта воздействия –размер выборки". При полном выявлении исследований эта диаграмма должна быть симметричной. Вместе с тем существуют и формальные методы оценки существующей асимметрии.
В заключение необходимо подчеркнуть, что мета-анализ является достаточно новой областью применения статистических методов в экологических исследованиях, при выполнении и интерпретации результатов которого существует много нерешенных проблем. Однако расширение исследований в этом направлении определяется объективной необходимостью перехода от "лоскутной экологии" к концепции широкого обобщения данных эксперимента для обоснования главных тенденций экологического развития на основе комплекса частных гипотез. По этой причине вряд ли можно согласиться с С. Хелбертом (2004), оценивающим мета-анализ только как “удобные и сжатые резюме литературных данных”.
Методы генерации псевдовыборок (resampling: bootstrap, jackknife, permutation)
Техника скоро дойдет до такого совершенства, что человек сможет обойтись без себя самого.
С.Е. Лец
При эмпирическом анализе данных обычно недостаточно получить точечную оценку некоторого выборочного параметра. Необходимо также изучить его статистические свойства, в первую очередь распределение полученной оценки, что является основой для построения доверительных интервалов и тестирования статистических гипотез. Поскольку точный вид распределения обрабатываемых данных, как правило, неизвестен, используют приближенные методы аппроксимации истинных свойств исследуемой статистики. Классическая теория основывается на асимптотическом методе, в котором используется то или иное стандартное предельное (при стремлении размера выборки к бесконечности) распределение выборочных параметров. Современной альтернативой асимптотическому методу является моделирование эмпирического распределения данных, т.е. аппроксимация координат точек с данными с использованием методов повторной генерации выборок.
Понятие повторные выборки в общем случае отличается от обычного представления, применяемого в методах выборочного анализа. Если, например, производится анализ биоразнообразия и отбирается проба в определенном месте и в определенный момент времени, то отобрать вторую, третью и т.д. пробы уже невозможно, потому что это будут уже пробы из другого места или же взятые в другой момент времени. Поэтому возникает проблема: как, имея лишь одну единственную пробу, оценить значение необходимого нам показателя и получить меру точности этой оценки.
В том случае, когда нет возможности получить истинные повторности наблюдений, разработаны методы, которые формируют так называемые "псевдовыборки", и на их основе позволяют получить необходимые характеристики искомого показателя: оценки математического ожидания, дисперсии, доверительного интервала. Методы "численного ресамплинга" {resampling} или, как их иногда называют в русскоязычной литературе, "методы по взятию повторных выборок" объединяют три разных подхода, отличающихся по алгоритму, но близких по сути: метод "складного ножа" {jackknife}, бутстреп {bootstrap} и метод перестановок {permutation}.
Идея первого алгоритма численного ресамплинга, предложенного в 1949 г. М. Кенуем, заключалась в том, чтобы последовательно исключать из имеющейся выборки по одному наблюдению, обрабатывать всю оставшуюся информацию и предсказывать результат в исключенной точке. Совокупность расхождений, полученных таким образом по всем точкам, несет в себе информацию о выборочном смещении, которой можно воспользоваться. Дж. Тьюки активно усовершенствовал этот метод, назвав его "jackknife", и использовал для оценки дисперсии изучаемой совокупности и проверки нулевой гипотезы о том, что распределение некоторой статистики симметрично относительно заданной точки. “Понятие "складной нож" относится к универсальному методу, призванному заменить частные методики, которые не всегда пригодны, подобно бойскаутскому ножу, годящемуся на все случаи жизни” (Мостеллер, Тьюки, 1982).
Bootstrap-процедура или "бутстреп" была предложена как некоторое обобщение процедуры "складного ножа". Дело в том, что формирование подвыборок в jackknife, а тем более в методах перепроверки, означает выбор без возвращения в имеющуюся совокупность. Известный американский статистик, профессор Станфордского университета Б. Эфрон (Efron, 1979) предложил воспользоваться выбором с возвращением, и тогда формально сохраняются все степени свободы на каждом этапе обработки данных. Видимо, именно в этом заключается преимущество бутстрепа перед другими планами управления выборками. Вопрос о полной корректности такого приема остается открытым, но если признать его законным, то асимптотические достоинства бутстрепа удается доказать вполне строго.
По одной из версий, слово "bootstrap" означает кожаную полоску в виде петли, прикрепляемую к заднику походного ботинка для облегчения его натягивания на ногу. Благодаря этому термину появилась английская поговорка 30-х годов: “Lift oneself by the bootstrap”, которую можно трактовать как “Пробить себе дорогу благодаря собственным усилиям”. Бутстреп-процедура не требует информации о виде закона распределения изучаемой случайной величины и в этом смысле может рассматриваться как непараметрическая, т.е. она работает без опоры на существенную часть априорной информации, чем, по-видимому, и обусловлен такой выбор термина.
Основная идея группы методов "размножения выборок" заключается в следующем. Пусть дана выборка x1, x2, x3, …, xk-1, xk, xk+1, …, xn-1, xn и предполагается, что это – набор независимых одинаково распределенных случайных величин. Задача заключается в изучении свойств некоторой статистики fn (x1, x2, …, xn). Метод "складного ножа" состоит в том, чтобы из одной выборки сделать n новых, исключая каждый раз по одному наблюдению. По каждой из сгенерированных выборок объемом (n - 1) можно рассчитать значение интересующей нас статистики:
fn-1,k (w ) = fn-1 (x1, x2, x3, …, xk-1, xk+1, …, xn-1, xn).
Полученные значения статистики позволяют судить о ее распределении и о характеристиках распределения – математическом ожидании, медиане, квантилях, разбросе, среднем квадратическом отклонении. Значения статистик, построенных по размноженным подвыборкам, строго говоря, не являются независимыми, однако при увеличении n влияние зависимости может ослабевать и со значениями статистик типа fn-1,k (w ), k = 1,2, …, n, можно обращаться как с независимыми случайными величинами.
Основная идея бутстрепа по Б. Эфрону (Efron, 1979; Mayer et al., 1986) состоит в том, что методом Монте-Карло (статистических испытаний) многократно извлекаются выборки из эмпирического распределения на основе генератора псевдослучайных чисел. А именно, берется конечная совокупность из n элементов исходной выборки x1, x2, x3, …, xk-1, xk, xk+1, …, xn-1, xn и с помощью датчика случайных чисел из нее формируется любое число размноженных выборок. Процедура эта, хотя и нереальна без ЭВМ, довольно проста с точки зрения программирования.
Есть много способов развития идеи размножения выборок (Орлов, 2006). Можно, например, по исходной выборке построить эмпирическую функцию распределения, а затем тем или иным образом от кусочно-постоянной функции перейти к непрерывной функции распределения, например, соединив точки [x(i); i/n], i = 1, 2, …, n, отрезками прямых. Другой вариант построения размноженных выборок - к исходным данным добавляются малые независимые одинаково распределенные погрешности (при таком подходе одновременно соединяются вместе идеи устойчивости и бутстрепа).
Итак, в основе бутстреповского подхода лежит идея, что истинное распределение статистик можно легко получить эмпирически. Пусть из исходной популяции с распределением F(x) была получена выборка размера n. Тогда эмпирическая функция распределения  равномерно стремится к F(x) при n®
¥
. Это свойство мотивирует использование бутстрепа, который выполняет автогенерацию, например, nk псевдостатистик. Рассмотрим процесс получения бутстреповских статистик на примерах.
равномерно стремится к F(x) при n®
¥
. Это свойство мотивирует использование бутстрепа, который выполняет автогенерацию, например, nk псевдостатистик. Рассмотрим процесс получения бутстреповских статистик на примерах.
Построение доверительных интервалов выборочных величин при неизвестном законе ее распределения.
Изучалась мелкомасштабная структура популяции наземных моллюсков B. bidens и было взято s = 11 выборок. Для каждой выборки подсчитывалось количество особей, имеющих на раковинах радиальные темные пигментные пестрины (признак Пигм+). Относительные частоты данного признака (см. табл. 2) свидетельствует о его значительной пространственной изменчивости в пределах изученной популяции, которая может быть выражена в числовой форме в виде оценки индекса фенетической дифференциации PST.
Таблица 2
Популяционные показатели особей B. bidens, обладающих признаком Пигм+, в изученных субпопуляциях
|
Популяционные показатели |
Номера выборок (субпопуляций) |
|||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
||
|
Объем выборки |
93 |
67 |
60 |
49 |
24 |
59 |
61 |
25 |
58 |
19 |
44 |
|
|
Результаты наблюдений |
ni |
58 |
43 |
37 |
35 |
13 |
27 |
46 |
17 |
31 |
12 |
36 |
|
pi |
0.624 |
0.642 |
0.617 |
0.714 |
0.542 |
0.458 |
0.754 |
0.680 |
0.534 |
0.632 |
0.818 |
|
Примечание: ni – абсолютная частота; pi – относительная частота искомого признака в i-той выборке, 1 ≤ i ≤ 11.
Для оценки показателя PST необходимо выполнить следующие расчеты. Вначале вычисляются средние квадраты отклонений, связанные с внутрипопуляционной изменчивостью по частоте исследуемого признака во всех 11 анализируемых выборках:

и обусловленные изменчивостью между субпопуляциями
 ,
,
где N – суммарная численность всех субпопуляций.
Тогда оценку показателя фенетической дифференциации можно произвести по следующей формуле:

 ,
,
где n* = 49.96 – средневзвешенный объем выборок.
Оценку 95% доверительного интервала для PST можно выполнить, используя F-распределение Фишера-Снедекора. Нижняя PST(L) и верхняя PST(U) доверительные границы в этом случае рассчитываются по формулам

 ,
,
где F – отношение средних квадратов, т.е.  ;
F1 – табличное значение критерия Фишера для α = 0.025; df1 = s – 1; df2 = N – s;
F2 – табличное значение критерия Фишера для α = 0.975; df1 = s – 1; df2 = N – s.
;
F1 – табличное значение критерия Фишера для α = 0.025; df1 = s – 1; df2 = N – s;
F2 – табличное значение критерия Фишера для α = 0.975; df1 = s – 1; df2 = N – s.
Таким образом, интервальная оценка искомого показателя составляет [0.0030; 0.1129].
С другой стороны, оценку 95% доверительного интервала для PST можно также получить, используя распределение χ2, по формулам



 ,
,
где χ2U – табличное значение распределения критерия для α = 0.975 и числа степеней свободы df = s – 1; χ2L – значение χ2 для α = 0.025 и числа степеней свободы df = s – 1. В этом случае интервальная оценка искомого показателя составит [0.0133; 0.0782].
Однако, поскольку закон распределения показателя PST apriori неизвестен, более обоснованным методом для построения его доверительного интервала будет одна из ресамплинг-процедур, а именно, bootstrap-процедура. В основе данного метода лежит принцип отбора с возвращением и формирование множества новых выборок (псевдовыборок) объема n из одной и той же эмпирической совокупности того же объема.
Например, в выборку № 1 попало 93 особи B. bidens, из которых 58 имели пестрины на раковине. Необходимо сформировать псевдовыборку того же объема для этой субпопуляции. В идеальном случае для этого необходимо отобрать первую попавшуюся особь из выборки № 1, отметить ее фен (раковина с пестринами или без) и возвратить обратно. Далее отобрать вторую особь, отметить ее фен и вновь возвратить обратно. И так поступить еще 91 раз. В итоге мы получим первую псевдовыборку для субпопуляции № 1. Аналогичным образом формируются вторая, третья, четвертая и остальные псевдовыборки для этой, а также для каждой из оставшихся 11 субпопуляций.
На практике это делается следующим образом. Поскольку мы имеем выборочную частоту (например, для первой субпопуляции она составляет 0.624; см. табл. 2) и объем выборки (93 особи), можно использовать генератор случайных чисел, например, встроенный в MS Excel, который будет с легкостью генерировать такие псевдовыборки, имеющие биномиальное распределение с заданными нами параметрами (например, для первой субпопуляции n = 93 и p = 0.624). Лучше всего, чтобы таких псевдовыборок для каждой субпопуляции было сформировано несколько сотен или даже тысяч. Например, мы сгенерировали по 1000 таких псевдовыборок для каждой субпопуляции (табл. 3).
Таблица 3
Псевдовыборки абсолютных частот особей B.bidens, обладающих признаком Пигм+, сгенерированные случайным образом для изученных субпопуляциях
|
Псевдо-выборки |
Номера выборок (субпопуляций) |
PST |
||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
||
|
1 |
61 |
44 |
39 |
35 |
17 |
28 |
48 |
19 |
25 |
11 |
37 |
0.0513 |
|
2 |
60 |
51 |
35 |
36 |
12 |
32 |
43 |
13 |
32 |
11 |
31 |
0.0145 |
|
3 |
49 |
42 |
41 |
33 |
15 |
28 |
47 |
18 |
36 |
14 |
33 |
0.0228 |
|
4 |
66 |
40 |
38 |
33 |
14 |
35 |
47 |
16 |
29 |
7 |
38 |
0.0381 |
|
5 |
61 |
51 |
36 |
34 |
12 |
28 |
45 |
18 |
21 |
13 |
37 |
0.0702 |
|
6 |
57 |
51 |
33 |
39 |
15 |
27 |
49 |
16 |
33 |
10 |
34 |
0.0472 |
|
7 |
61 |
48 |
30 |
35 |
12 |
23 |
43 |
14 |
32 |
10 |
34 |
0.0434 |
|
8 |
53 |
42 |
34 |
36 |
12 |
34 |
45 |
17 |
37 |
12 |
38 |
0.0218 |
|
9 |
51 |
46 |
42 |
33 |
13 |
30 |
37 |
17 |
38 |
10 |
38 |
0.0235 |
|
10 |
56 |
38 |
42 |
33 |
15 |
31 |
42 |
20 |
35 |
15 |
33 |
0.0093 |
|
… |
||||||||||||
|
1000 |
60 |
42 |
32 |
38 |
12 |
25 |
48 |
19 |
35 |
12 |
33 |
0.0420 |
В последнем столбце табл. 3 приведены соответствующие оценки (псевдооценки) показателя фенетической дифференциации PST, рассчитанные аналогично тому, как это было сделано выше для набора эмпирических данных. Рассчитав 2.5% и 97.5% перцентили для распределения псевдооценок PST, можно получить, соответственно, нижнюю и верхнюю границы 95% доверительного интервала для искомого показателя. В нашем случае bootstrap-оценка доверительного интервала составляет [0.0121; 0.0895].
Сравнительный анализ всех трех приведенных процедур оценивания границ доверительного интервала PST показывает, что наиболее устойчивая оценка получена при использовании ресамплинг-метода. Наименее эффективен метод, основанный на распределении χ2, который в случае отрицательных значений выборочной оценки PST дает абсурдные значения.
Оценивание вариансы и статистической ошибки выборочной величины при неизвестном законе ее распределения.
Методы численного ресамплинга незаменимы и в том случае, когда необходимо оценить варинсы (или ковариансы) показателей, закон распределения которых неизвестен или же значительно отклоняется от гауссовского.
Например, рассчитаем оценки вариансы индекса фенетической дифференциации PST, используя метод "складного ножа" (jackknifing-процедуру). Для этого, необходимо предварительно получить выборку из jackknifing-оценок PST. Поэтому на первом этапе удаляем из 11 исходных данных значения частот для субпопуляции № 1 и рассчитываем значение PST, основываясь лишь на оставшихся 10 выборках. Далее удаляем из расчетов субпопуляцию № 2 и опять оцениваем значение PST. Эти действия повторяем столько раз, сколько исходных выборок мы имеем, т.е. 11 раз, и получаем, соответственно, 11 jackknife-оценок PST:
|
Субпопуляция |
||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
0.0349 |
0.0331 |
0.0327 |
0.0283 |
0.0286 |
0.0130 |
0.0225 |
0.0298 |
0.0268 |
0.0300 |
0.0157 |
Это – стандартная jackknife-процедура, хотя единицей анализа является не отдельная особь, а субпопуляция (точнее, выборка из нее). Данная методика используется в том случае, когда имеет место иерархическая структурированность исходных данных: особи собраны в субпопуляции, каждая из которых является частью популяций, объединяемых в свою очередь в группы популяций и т.п. В этом случае объектом jackknife-процедуры является тот иерархический уровень, для которого производится оценка показателя. В рассмотренном случае показатель фенетической дифференциации относится не к отдельным особям, а к их совокупностям (субпопуляциям), поэтому объектом анализа и принимается отдельная субпопуляция.
Основываясь теперь на выборке jackknife-оценок показателя PST, рассчитаем по следующим формулам оценки jackknife-среднего значения

 ,
,
jackknife-вариансы  =
= = 0.000452
= 0.000452
и jackknife-статистической ошибки 
 = 0.0213.
= 0.0213.
Таким образом, jackknife-оценка показателя фенетической дифференциации для рассмотренного примера составляет: 0,0263 ± 0,0213.
Нетрудно заметить, что в приведенном нами примере, как и во многих других случаях, при росте числа статистических испытаний методом Монте-Карло бутстреп-оценка приближается к классической оценке – среднему арифметическому результатов наблюдений. Другими словами, бутстреп-оценка отличается от обычной только шумом псевдослучайных чисел. Следовательно, там “где найдены методы анализа данных, в том или иной смысле близкие к оптимальным, бутстрепу делать нечего. А вот в новых областях со сложными процессами, свойства которых недостаточно ясны, он представляет собой ценный инструмент для изучения ситуации” (Орлов, 2006).
Оценка уровня значимости p при проверке статистических гипотез.
Стандартный метод определения p-значений основан на теоретическом распределении, которое имеет некая статистика G, рассчитываемая в ходе проверки нулевой гипотезы. Иными словами, априори предполагается известной форма распределения тест-статистики G в случае, если влияние исследуемого фактора отсутствует, т.е. все эмпирические выборки относятся к одной генеральной совокупности. Практически это распределение можно оценить, перебрав все возможные комбинации формирования выборок из значений, полученных в результате наблюдения. Ввиду огромного числа возможных вариантов перебора этот процесс нечасто реализуем (например, в структуре так называемого точного критерия Фишера, применяемого к таблицам сопряженности размером 2´
2). Решение этой проблемы может быть осуществлено на основе так называемого перестановочного теста {permutation-test}.
Общая идеология перестановочной процедуры для оценки p-значения заключается в следующем:
 , где I[E] принимает значение 0 либо 1 в зависимости от того верно или нет утверждение E.
, где I[E] принимает значение 0 либо 1 в зависимости от того верно или нет утверждение E.Обычно ограничиваются разумным числом случайно выбранных комбинаций для оценки p-значения (чаще всего вполне достаточно выполнить U = 10 000 перестановок).
Рассмотрим на конкретном примере процедуру перестановочного теста. Выполняется качественный анализ видовой структуры ихтиоценоза Чебоксарского водохранилища по результатам многолетних наблюдений. Полная база содержит данные по 152 съемкам методом неводного лова, в которых всего зафиксировано S = 34 вида ихтиофауны. Все 67 станций наблюдений отнесены к 4 типичным участкам. Показатели встречаемости отдельных видов могут выражаться количеством проб ni, в которых обнаружен вид, либо долей ti, т.е. отношением частоты к общему числу проб (табл. 4).
Таблица 4
Распределение встречаемости видов рыб на участках Куйбышевского водохранилища
|
Вид |
Верхнеречной |
Среднеречной |
Озер-ный |
Припло-тинный |
Река Ока |
Водохранилище в целом |
Критерий χ2 |
p -вероят-ность |
|
|
n |
t |
||||||||
|
Бычок кругляк |
0 |
5 |
8 |
8 |
5 |
26 |
17.1 |
20.65 |
0.0005 |
|
Густера |
2 |
15 |
7 |
5 |
2 |
31 |
20.4 |
3.998 |
0.4122 |
|
Елец |
9 |
28 |
16 |
11 |
8 |
72 |
47.4 |
2.059 |
0.7347 |
|
Ерш |
8 |
15 |
8 |
5 |
7 |
43 |
28.3 |
2.549 |
0.6482 |
|
Жерех |
3 |
26 |
11 |
10 |
9 |
59 |
38.8 |
10.77 |
0.0286 |
|
Лещ |
18 |
45 |
23 |
8 |
14 |
108 |
71.0 |
8.081 |
0.0934 |
|
Окунь |
20 |
48 |
26 |
15 |
14 |
123 |
80.9 |
0.927 |
0.9286 |
|
Плотва |
19 |
52 |
26 |
17 |
15 |
129 |
84.9 |
2.483 |
0.6637 |
|
Тюлька |
4 |
15 |
5 |
1 |
6 |
31 |
20.4 |
6.114 |
0.1969 |
|
Уклея |
19 |
32 |
15 |
9 |
12 |
87 |
57.2 |
10.11 |
0.0384 |
|
Щука |
6 |
29 |
9 |
4 |
4 |
52 |
34.2 |
8.207 |
0.0837 |
|
Язь |
7 |
35 |
15 |
13 |
13 |
83 |
54.6 |
12.26 |
0.0156 |
Примечание: виды, для которых обнаружены достоверно значимые отличия во встречаемости между участками водохранилища, выделены жирным шрифтом.
Выполним анализ встречаемости отдельных видов с применением критерия χ2, который традиционно используется для анализа частотных данных:  , где oj и ej – соответственно, наблюдаемые и ожидаемые частоты для каждой j-й ячейки таблицы сопряженности 2´
k, k – количество диапазонов, на которые делится интервал варьирования анализируемого показателя. В такой форме значение статистики χ2 является приближением оценки максимального правдоподобия, точность которого снижается, если наблюдаемая частота в одной из ячеек таблицы сопряженности меньше 5. В этих случаях лучше использовать точное значение оценки максимального правдоподобия:
, где oj и ej – соответственно, наблюдаемые и ожидаемые частоты для каждой j-й ячейки таблицы сопряженности 2´
k, k – количество диапазонов, на которые делится интервал варьирования анализируемого показателя. В такой форме значение статистики χ2 является приближением оценки максимального правдоподобия, точность которого снижается, если наблюдаемая частота в одной из ячеек таблицы сопряженности меньше 5. В этих случаях лучше использовать точное значение оценки максимального правдоподобия:  . Однако при работе с частотами видов во взятых ихтиологических пробах нередко встречается ситуация, когда в той или иной выборке наблюдаемая частота вида nj = 0 (т.е. вид вообще не был отмечен). Тогда корректно рассчитать значение статистики χ2 ни по одной из двух формул становится уже невозможным.
. Однако при работе с частотами видов во взятых ихтиологических пробах нередко встречается ситуация, когда в той или иной выборке наблюдаемая частота вида nj = 0 (т.е. вид вообще не был отмечен). Тогда корректно рассчитать значение статистики χ2 ни по одной из двух формул становится уже невозможным.
Для разрешения описанной проблемы используем перестановочную процедуру {permutation}. Вначале частоты nj рассчитаем как общую встречаемость анализируемого вида по всем пробам, относящимся к j-му участку. На основе этих частот по любой из приведенных формул легко определяется статистика χ20 (которая фиксируется как G0). Далее элементы данных случайным образом многократно переставляются между выборками и каждый раз новое полученное значение статистики фиксируется как χ2u (т.е. Gu). Процедура перестановок повторяется U раз (например, в приведенном примере использовалось 10 000 перестановок), а p-значение рассчитывается по формуле  . Некоторые результаты оценки различий во встречаемости доминирующих видов рыб в разных сообществах представлены в табл. 4.
. Некоторые результаты оценки различий во встречаемости доминирующих видов рыб в разных сообществах представлены в табл. 4.
Другая задача связана с выявлением общих различий в видовой структуре сообществ как совокупностей, составляемых видами. Здесь необходим многомерный анализ, обобщающий все переменные, каждая из которых соответствует тому или иному виду, образующему ихтиоценоз. В терминах анализа сообществ это означает, что в единой процедуре должна быть рассмотрена вся совокупность видов, как структурный элемент экосистемы, обладающий эмерджентными надпопуляционными свойствами. Непараметрическая версия такого анализа также может быть реализована в рамках перестановочной процедуры. Представляет интерес следующий алгоритм решения (Good, 2005):
 . Процедура ранжирования осуществляется отдельно для каждой из переменных.
. Процедура ранжирования осуществляется отдельно для каждой из переменных. .
. .
.Некоторым аналогом описанного метода анализа мог бы послужить многомерный дисперсионный анализ в пространстве численностей видов (или иных количественных характеристик обилия), но возможности параметрических процедур существенно ограничиваются проблемой исполнения исходных предпосылок о нормальном законе распределения данных.
Многомерная версия перестановочного теста для всего видового списка дает следующие результаты. Наблюдаемое значение комбинирующей функции Фишера составило B0 = 87.68. Распределение этой статистики для всех 10 000 перестановок представлено на рис. 3. Такое распределение имела бы статистика B, если бы все выборки относились к одной генеральной совокупности, т.е. при условии отсутствия каких-либо отличий между участками водохранилища.

Рис. 3. Гистограмма распределения значений комбинирующей функции Фишера в многомерном перестановочном тесте
Наблюдаемое значение статистики B (на рис. 3 обозначено стрелкой) находится в правом шлейфе этого распределения. Это означает, что вероятность получить такое значение при отсутствии различий крайне мало (реально максимальное значение B, полученное в результате случайных перестановок составило 74.96). Оценка этой вероятности на основе полученного распределения и формулы по шагу 4 алгоритма составляет p = 0.00005. Таким образом, можно говорить о высокой степени достоверности различий в видовой структуре между пятью участками водохранилища, зафиксированных на основе данных по встречаемости видов.
В следующем подразделе приведен еще один пример использования метода перестановок для оценки уровня значимости полученной величины в случае заранее неизвестного закона ее распределения.
Энтропийный дисперсионный анализ (ЭДА): метод сравнения нескольких групп с использованием информационного индекса Шеннона
Из концепций элементов объективности полны
выплывают перманентно адекватные челны.
В фундаментальных работах К. Шеннона, У. Эшби, Р. Маргалефа, Р. Мак-Артура, И.И. Шмальгаузена обосновывается использование энтропии для характеристики меры сложности биологической системы с точки зрения ее разнообразия. Это дает возможность учесть не только абсолютное количество элементов системы, но и вероятность pi, с которой система принимает то или иное состояние:  . В последнее время появилось много публикаций, в которых продемонстрированы возможности применения энтропийно-информационного анализа (ЭИА) в различных областях биологической науки, физиологии и медицине и др. В экологии, наряду с использованием формулы К. Шеннона для оценки меры биоразнообразия отдельных сообществ и биоценозов, ЭИА получил свое применение и в качестве метода биоиндикации экосистем по соотношению мер адаптивности и инадаптивности признака или группы признаков (см. Крамаренко, 2005).
. В последнее время появилось много публикаций, в которых продемонстрированы возможности применения энтропийно-информационного анализа (ЭИА) в различных областях биологической науки, физиологии и медицине и др. В экологии, наряду с использованием формулы К. Шеннона для оценки меры биоразнообразия отдельных сообществ и биоценозов, ЭИА получил свое применение и в качестве метода биоиндикации экосистем по соотношению мер адаптивности и инадаптивности признака или группы признаков (см. Крамаренко, 2005).
Основные положения теории информации исходно были разработаны для дискретных (качественных) признаков, имеющих полиномиальное распределение, и до сих пор нет единого, теоретически обоснованного метода оценки энтропии H для количественных признаков. В общем случае, для всего возможного спектра значений, которые может принять признак, устанавливают некую меру точности (Δх) измерения, в пределах которого состояния системы оказываются практически неразличимы. Тогда непрерывно варьирующую систему можно приближенно свести к дискретной. Если признак х системы имеет нормальное распределение, то его энтропия, рассчитанная по гистограмме, будет равна  . С.С. Крамаренко (2005) приведены аргументы, показывающие противоречивость такого подхода, поскольку имеет место частотная неравномерность диапазонов Δх на кривой Гаусса-Лапласа. Предлагается оценивать энтропию не для величин плотности распределения z-трансформированных значений исходной выборки, а для интеграла этих оценок, т.е. использовать величины
. С.С. Крамаренко (2005) приведены аргументы, показывающие противоречивость такого подхода, поскольку имеет место частотная неравномерность диапазонов Δх на кривой Гаусса-Лапласа. Предлагается оценивать энтропию не для величин плотности распределения z-трансформированных значений исходной выборки, а для интеграла этих оценок, т.е. использовать величины
 .
.
Другой важнейшей задачей ЭИА является оценка достоверности различий полученных оценок энтропии (в экологических исследованиях -
индекса Шеннона-Уивера) в двух или более выборках с последующим вычислением уровня значимости полученных различий. В статье К. Баумена с соавторами (Bowman et al., 1969) предлагается для проверки нулевой гипотезы о равенстве энтропии в двух выборках использовать следующий критерий:  , где H1 и H2 – выборочные оценки энтропии в двух сравниваемых совокупностях, а Var(H1) и Var(H2) – их вариансы. Оценку вариансы энтропии для соответствующей выборки можно получить по формуле
, где H1 и H2 – выборочные оценки энтропии в двух сравниваемых совокупностях, а Var(H1) и Var(H2) – их вариансы. Оценку вариансы энтропии для соответствующей выборки можно получить по формуле
 ,
,
где n – объем выборки; s – число альтернативных состояний системы или групп элементов в выборке.
Показано, что рассчитанная t-статистика может быть аппроксимирована распределением t-критерия Стьюдента с числом степеней свободы:  , где n1 и n2 – объемы сравниваемых выборок.
, где n1 и n2 – объемы сравниваемых выборок.
Ниже предложен алгоритм сравнения k (k > 2) оценок энтропии, полученных одновременно по более чем двум выборкам. Этот алгоритм подобен алгоритму дисперсионного анализа с разложением суммарной изменчивости комплекса на межгрупповую компоненту и остаточную, поэтому данная методика может быть названа "энтропийный дисперсионный анализ" (ЭДА).
Предложим, что имеется k групп (т.е. выборок) объектов с соответствующими объемами Ni, где  . В каждой группе встречаются j типов объектов (например, экологических видов), с каждым из которых связано целочисленное значение показателя обилия mij ,
. В каждой группе встречаются j типов объектов (например, экологических видов), с каждым из которых связано целочисленное значение показателя обилия mij ,  . Тогда по таблице исходных данных могут быть рассчитаны следующие суммарные значения:
. Тогда по таблице исходных данных могут быть рассчитаны следующие суммарные значения:
 ,
,  ,
,  .
.
Для каждой включенной в анализ выборки, а также для суммарных данных рассчитываются соответствующие оценки энтропии:
 ;
;  .
.
Затем необходимо рассчитать следующие величины (в дисперсионном анализе они соответствуют суммам квадратов):
 ,
,  ,
,  .
.
Следующим этапом расчетов будет отнесение полученных величин к соответствующим числам степеней свободы (в дисперсионном анализе полученные таким образом величины называются средними квадратами):
 и
и  .
.
Тогда показатель, который можно использовать для проверки нуль-гипотезы о равенстве всех оценок энтропии в используемых выборках, рассчитывается по формуле  ,
,
где N0 – средняя взвешенная численность объектов в разных группах, вычисляемая по формуле 
Показатель h варьирует в пределах от 0 до 1 (хотя в некоторых случаях может оказаться меньше нуля). В том случае, если численности объектов разного типа равны или пропорциональны во всех сравниваемых выборках, данный показатель будет равен нулю. И, наоборот, при отчетливой блочной (существенно неоднородной) структуре распределения объектов разного типа по выборкам и при достаточно больших N показатель h будет стремиться к единице.
Использование показателя h , по нашему мнению, имеет некоторое преимущество и при сравнении двух выборок перед методом К. Баумена, поскольку учитывает не только численности отдельных типов объектов в выборке (например, видов при биоценотических сравнениях), но и структуру самих пулов объектов. Например, если в выборке № 1 отмечено 5 видов с численностями 27, 11, 6, 3 и 1, а в выборке № 2 те же 5 видов, но с численностями 3, 11, 27, 1 и 6, то метод Баумена даст заключение о том, что нулевая гипотеза не может быть отвергнута, поскольку обе сравниваемые выборки имеют одинаковые пулы абсолютных частот видов. Однако структура сравниваемых биоценозов явно отлична, и показатель h эту разницу способен отчетливо оценить.
Таким образом, проверку предположения о равенстве оценок энтропии в сравниваемых выборках можно свести к тесту нулевой гипотезы  при альтернативе
при альтернативе  Стандартный метод проверки этой гипотезы, используемый в классическом дисперсионном анализе Р. Фишера, не может быть использован. Во-первых, исходные данные не имеют нормального распределения (скорее, распределены по полиномиальному закону), а во-вторых, приведенные оценки варианс по своей сути не являются истинными средними квадратами, поэтому их отношение не имеет никакого отношения к F-распределению Фишера-Снедекора.
Стандартный метод проверки этой гипотезы, используемый в классическом дисперсионном анализе Р. Фишера, не может быть использован. Во-первых, исходные данные не имеют нормального распределения (скорее, распределены по полиномиальному закону), а во-вторых, приведенные оценки варианс по своей сути не являются истинными средними квадратами, поэтому их отношение не имеет никакого отношения к F-распределению Фишера-Снедекора.
Поскольку закон распределения оценки h
нам не известен, для проверки нулевой гипотезы можно использовать методы численного ресамплинга. Из трех различных подходов, перечисленных в предыдущем подразделе, наиболее приемлемым для данного случая будет метод перестановок {permutation procedure}. Особи из исходных выборок, используемых в анализе, с учетом их типа (в нашем случае -
с учетом их видовой принадлежности) случайным образом перетасовываются по разным выборкам так, чтобы суммы строк и столбцов в исходной таблице данных оставались бы без изменения. Для этой искусственно полученной матрицы данных рассчитывается псевдооценка h
*. Далее данные вновь перетасовываются и рассчитывается вторая псевдооценка h
*. Эта процедура повторяется многократно (например, M раз). Желательно, чтобы величина M имела порядок нескольких тысяч. Для полученного таким образом вектора псевдооценок |h
*| подсчитывается, сколько раз эти значения равны или превысили значение ή, полученное для матрицы исходных данных. Если это число будет равно m, то уровень значимости оценки ή можно рассчитать по формуле  .
.
Рассмотрим всю процедуру проведения ЭДА на приведенном ниже примере. Пусть при анализе четырех проб было отмечено присутствие пяти видов с численностями, представленными в табл. 5. Необходимо проверить нуль-гипотезу о том, что эти выборки отобраны из одной генеральной совокупности (т.е. из одного биоценоза) и, соответственно, характеризуются сходным распределением видов и одинаковыми оценками индекса разнообразия Шеннона.
Таблица 5
Пример исходных данных для энтропийного дисперсионного анализа
|
Вид |
Число особей и частоты встречаемости (в скобках) видов по выборкам |
Средняя частота |
|||
|
1 |
2 |
3 |
4 |
||
|
A |
15 (0.4286) |
8 (0.2857) |
4 (0.2000) |
9 (0.2250) |
36 (0.2927) |
|
B |
5 (0.1429) |
5 (0.1786) |
1 (0.0500) |
6 (0.1500) |
17 (0.1382) |
|
C |
2 (0.0571) |
7 (0.2500) |
6 (0.3000) |
4 (0.1000) |
19 (0.1545) |
|
D |
5 (0.1429) |
6 (0.2143) |
5 (0.2500) |
4 (0.1000) |
20 (0.1626) |
|
E |
8 (0.2286) |
2 (0.0714) |
4 (0.2000) |
17 (0.4250) |
31 (0.2520) |
|
Сумма по выборкам |
35 |
28 |
20 |
40 |
123 |
|
Индекс Шеннона (H) |
2.0487 |
2.2084 |
2.1660 |
2.0838 |
2.2569 |
|
Hi·Ni |
71.7045 |
61.8352 |
43.3200 |
83.3520 |
277.598 |
Вначале рассчитываются частоты встречаемости pi каждого вида для каждой выборки и для их сумм в целом (представлены значениями в скобках табл. 4). Далее, на основе этих частот рассчитываются индексы разнообразия Шеннона. В последней строке табл. 5 приведены произведения оценок индекса Шеннона на объемы соответствующих выборок или, для последнего столбца, на суммарный объем комплекса.
Затем по вышеприведенным формулам находятся оценки величин, аналогичные суммам квадратов (CT , CR , CA) и средним квадратам (MSA, MSR) отклонений:
CT = 2.257·123 = 277.6; CR = 71.76 + … + 83.356 = 260.26;
CA = 277.6 – 260.26 = 17.39;
 ;
;  .
.
Поскольку объемы выборок не равны, предварительно рассчитывается средневзвешенная численность объектов в разных группах
 ,
,
и, наконец, оценка искомого показателя  .
.
Для проверки нуль-гипотезы о равенстве полученной оценки нулю используется permutation-процедура. После 500 перестановок в 19 случаях псевдооценка h
*, полученная случайным образом, превышала величину, рассчитанную для фактических данных. Таким образом, уровень значимости (ошибка II рода) данной величины составляет 
Эта величина достаточно мала, поэтому нулевая гипотеза не может быть принята, и, соответственно, можно считать, что исследуемые выборки взяты не из одной генеральной совокупности и различаются по величине шенноновской энтропии.
С другой стороны, нами было установлено, что распределение псевдооценок h
имеет вид, близкий к нормальному. Поэтому для проверки нулевой гипотезы может быть использован и стандартный двусторонний Z-критерий:  , где
, где  и
и  -
среднее арифметическое и среднее квадратическое отклонение вектора псевдооценок.
-
среднее арифметическое и среднее квадратическое отклонение вектора псевдооценок.
В данном примере для первых 100 псевдооценок показателя h
среднее арифметическое значение составляло 0.0149 со средним квадратическим отклонением 0.0182. Поэтому оценка Z-критерия равна:  . Поскольку эта величина превышает 1.96, можно считать, что нулевая гипотеза должна быть отвергнута с уровнем значимости p < 0.05. Точный уровень значимости для данного значения составляет 0.042, что достаточно близко к оценке, полученной выше при использовании перестановочного критерия.
. Поскольку эта величина превышает 1.96, можно считать, что нулевая гипотеза должна быть отвергнута с уровнем значимости p < 0.05. Точный уровень значимости для данного значения составляет 0.042, что достаточно близко к оценке, полученной выше при использовании перестановочного критерия.
Предлагаемый алгоритм ЭДА может быть использован не только для сравнения оценок энтропии (индекса Шеннона-Уивера) в экологических исследованиях, но и в общем случае энтропийно-информационного анализа (ЭИА) для количественных признаков. При этом с помощью ЭДА также проверяется нуль-гипотеза о том, что разные выборки взяты из одной генеральной совокупности и, соответственно, характеризуются одинаковыми оценками энтропии. Эта проверка касается прежде всего характера распределения объектов в анализируемых выборках. Для оценки значений энтропий может быть использовано преобразование переменных, упомянутое выше (Крамаренко, 2005), на основе обобщенной выборки всех исходных данных. Далее производится процедура классификации объектов, в результате чего получаем таблицу кросс-табуляции со стандартной организацией для дисперсионного анализа.
Деревья классификации и регрессии
Дерева вы мои, дерева,
Что вам головы гнуть-горевать.
До беды, до поры шумны ваши шатры,
Терема, терема, терема.
"Операционным полем" аналитических действий в области экологии сообществ являются наборы данных, организованные в виде трех таблиц: матрицы B (n´ p), содержащей подмножество p аутэкологических свойств изучаемой совокупности n видов (таксонов); матрицы W (n´ m) показателей обилия видов, зарегистрированых в ходе наблюдений на подмножестве m местообитаний, и матрицы E (m´ s), содержащей измерения совокупности s факторов среды в каждой точке взятия экологических проб. Важнейшими задачами при этом являются: (i) выделение эколого-ценотических и функциональных групп видов или (ii) классификация местообитаний (районирование). При этом возникает необходимость искать ответы на целый ряд сопутствующих вопросов:
Существует много математических методов частной или обобщенной обработки таблиц B, W и E для решения поставленных вопросов. Классическими подходами в этих случаях являются многомерный дисперсионный анализ (MANOVA), метод главных компонент и дискриминантный анализ функций (DA), однако следует упомянуть также непараметрический MANOVA, пермутационные процедуры мультиотклика (MRPP), индикаторный анализ видов (ISA), тест Мантеля (Mantel) на контраст групп, алгоритм программы ANOSIM и др. (McCune, Grace, 2002). Большинство перечисленных методов сосредотачиваются на оценке статистических отличий групп, не анализируя, какие переменные определяют эти различия. ISA, DA, и частично тест Мантеля, позволяют идентифицировать такие переменные, однако только DA обеспечивает явную возможность классификации неизвестных выборок с использованием решающих правил, полученных на обучающих последовательностях.
Метод Data Mining построения деревьев решений {decision trees} предлагает новую и весьма перспективную альтернативу оценки различий между группами, одновременно выполняя функции прогнозирования (McCune, Grace, 2002; Шитиков и др., 2004). Иногда деревья решений также называют деревьями решающих правил, деревьями классификации и регрессии (CART). Классификационные модели деревьев иерархического типа рекурсивно делят набор данных на подмножества, являющиеся все более и более гомогенными относительно определенных признаков, которые обеспечивают древовидную классификацию и ассоциативный дихотомический ключ, дающий возможность выполнять классифицирование неизвестных выборок. Отличие классификационных и регрессионных моделей заключается в том, что в деревьях классификации зависимая переменная измеряется в категориальных шкалах (например, тип древостоя), когда как деревья регрессии предсказывают непрерывные значения отклика (например, средний диаметр древостоя). В каждом случае работает один и тот же алгоритм, хотя терминология, форма представления и интерпретация несколько отличаются для дискретного и непрерывного случая. Многомерные деревья регрессии подобны одномерным деревьям, но заменяют единственный непрерывный отклик математической комбинацией некоторого множества непрерывных откликов.
По своей сути деревья решений используют принцип "наивной" классификации {naive approach}, поскольку исходят из предположения о взаимной независимости признаков. Поэтому модели классификационных деревьев статистически наиболее работоспособны, когда комплекс анализируемых переменных не является аддитивным или мультипликативным. Из-за своей рекурсивной природы этот метод особенно применим в случаях, когда имеется регулярная внутренняя множественная альтернатива в исходной комбинации переменных, связанная с самим процессом группировки.
Отметим ряд несомненных преимуществ классификационных моделей деревьев:
Деревья решений представляют собой последовательные иерархические структуры, состоящие из узлов, которые содержат правила, т.е. логические конструкции вида "если…, то…". Конечными узлами дерева являются "листья", соответствующие найденным решениям и объединяющие некоторое количество объектов классифицируемой выборки. "Листья" еще именуются метками прогнозируемого класса, т.е. являются значениями зависимой категориальной переменной. Это похоже на то, как положение листа на дереве можно задать, указав ведущую к нему последовательность ветвей, начиная от корня и кончая самой последней веточкой, на которой лист растет.
Корневой узел связан с одной из переменных исходной таблицы данных, которая выбирается в качестве стартовой или опорной. Общее правило для выбора опорного признака можно сформулировать следующим образом: “выбранный признак должен разбить множество Х* так, чтобы получаемые в итоге подмножества Х*k , k = 1, 2, …, p, состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому”. От корня может отходить к внутренним узлам дерева две (для бинарного случая) или более ветвей, называемых предикторами расщепления. Каждый внутренний узел представляет собой критерий расщепления {splitting criterion}, связанный c наиболее подходящими переменными исходной таблицы, и выбранный таким образом, чтобы количество чужеродных объектов из других классов в каждом из формируемых далее подмножеств было как можно меньше.
Построение деревьев классификации связано с такими методологически важными этапами, как содержательное описание идентифицируемых классов, выбор предикторных переменных и управление индуктивным процессом формирования иерархической структуры, в том числе, оптимизация полученного дерева.
В большинстве случаев выбор классификационных групп прямо соответствует поставленной задаче, однако всегда необходимо учитывать некоторые "тонкие" нюансы, которые не всегда принимаются во внимание на практике. Например, при анализе видовой структуры сообществ часто выбирают классификационную модель с двумя исходами (т.е. отклик – бинарная переменная), противопоставляя, например, "естественную" экосистему "нарушенной". При этом предполагается, что большинство видов, образующих сообщество "естественной экосистемы" будет отсутствовать в "нарушенной". Но такой подход игнорирует ту обычную возможность, что существенное количество видов, потенциально характерных для естественной среды, по тем или иным случайным причинам могут отсутствовать в конкретных выборках.
Критическая проблема назначения в качестве отклика множественной порядковой переменной – это степень, в которой каждая группа является самостоятельной (т.е. исключительной). Можно установить несколько градаций степени нарушенности экосистем, как это сделано, например, с классами качества вод водоемов от I до VI. Но при этом нужно отчетливо установить критерии отличия этих градаций. Другой проблемой статистического характера является неравная априорная вероятность появления отдельных градаций в выборках. Например, появление в исходной таблице данных о водоемах с I классом качества является уникальной ситуацией, поскольку подавляющее большинство естественных водоемов относятся к III или IV классам качества вод.
В экологии интересен опыт применения моделей деревьев классификации для оценки типов растительности в пространстве взвешенных факторов окружающей среды. Рассмотрим пример дерева решений, построенного для анализа и прогнозирования эколого-ценотических групп (ЭЦГ) таежных сообществ сосудистых растений (Смирнов и др., 2006). При анализе 133 видов, имеющих значения по всем экологическим шкалам из таблиц Г. Элленберга, опорным фактором при разделении видов средней тайги на девять ЭЦГ выступил свет (L) - см. рис. 4.

Рис. 4. Классификационное дерево (усеченное) для видов средней тайги.
F - увлажнение почвы, L -
освещенность, N – богатство азотом, R -
кислотность почвы, T – температурный режим. Обозначения эколого-ценотических групп (представлены жирным курсивом) см. в тексте
Полностью теневые, теневые и полутеневые растения (L<=5) разделились далее по фактору температурного режима на растения холодного и прохладного климата (T<=4) – они составили группу бореального мелкотравья (Br_m), и на растения умеренно теплого и теплого климата (T>4). Последние далее разделились по фактору увлажнения почв на неморальные (F<=6) и нитрофильные (F>6). Правая часть дерева – полусветовые и световые растения (L>5) разделились по фактору кислотности почв на растения очень кислых и кислых почв (R<=4) – группы бореальных кустарничков и вечнозеленых трав (Br_k), боровая (Pn) и олиготрофная (Olg), и на растения слабокислых и нейтральных почв (R>4) - группы лугово-опушечных видов (Md), бореального высокотравья (H) и прибрежно-водных видов (Wt). При этом группа Olg отделилась от групп Br_k и Pn по фактору увлажнения (F>6), а группы Br_k и Pn разделились между собой по температурному режиму – на растения холодного и прохладного климата – Br_k (T<=4) и на растения умеренно теплого и теплого климата – Pn (T>4). Группы Md, H и Wt разделились между собой по фактору увлажнения (F<=5, 5<F<=8 и F>8 соответственно).
Процесс конструирования деревьев решений состоит из двух этапов: "построение" или "создание" дерева {tree building} и "сокращение" дерева {tree pruning}. Качество классификационной модели, построенной при помощи дерева решений, характеризуется точностью распознавания, т.е. отношением объектов, правильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении. В ходе создания дерева решаются следующие частные вопросы, призванные повысить точность распознавания:
На сегодняшний день существует большое число алгоритмов, реализующих построение деревьев решений, которые различаются следующими характеристиками:
Ни один алгоритм построения дерева нельзя априори считать наилучшим или совершенным: подтверждение целесообразности использования конкретного алгоритма должно быть проверено и подтверждено экспериментом. Наибольшее распространение и популярность на сегодняшний день получили следующие (Witten, Frank, 2005):
Классификационное дерево на рис. 4 было построено с использованием свободно распространяемой Java-программы машинного обучения WEKA 3.4 на основе алгоритма C4.8 (университет Вайкато, Австралия, http://www.cs.waikato.ac.nz/~ml/weka).
Модели мониторинга, основанные на совокупности "биотестов"
(фрагмент из отзыва чл.-корр. РАН А.Г. Дегерменджи, официального оппонента докторской диссертации одного из авторов)
Число открываемых законов стремится заполнить
все доступное для публикации пространство.
"Традиционная" (по сути редукционистская) схема построения математической модели состояния водной экосистемы и качества вод опирается на достаточно детальную блок-схему биохимических превращений вещества и энергии по трофическим звеньям экосистемы, учитывает характер и интенсивность межпопуляционных нетрофических (регуляторных) взаимодействий, зависимость кинетических характеристик от модифицирующих факторов и т.п. Многие из этих характеристик могут быть экспериментально получены в лабораторных или полуполевых условиях. Этап идентификации и верификации таких моделей требует также использования обширных гидрохимических и гидробиологических натурных данных, включая и гидрометеорологические сведения. Затем, в случае адекватного модельного представления, расчеты, полученные по многочисленным компонентам, агрегируются в некие показатели или классы качества воды и сравниваются с соответствующими нормативными значениями. Этот подход еще долгие годы будет успешно работать для различных задач и на различных водоемах. Однако представляется, что такой путь для целей прогноза качества воды является избыточным, крайне трудоемким, дорогостоящим и нуждается в научном поиске альтернативных решений.
Растущая степень антропогенного воздействия поставит перед этим подходом ряд трудноразрешимых проблем:
Перечисленные причины заставляют развивать новые интегральные методы оценки состояния водных экосистем, по сути своей базирующиеся на холистическом подходе в биофизике. К такому направлению относится разработка комплекса так называемых "биотестов", основную идею и сущность которых можно определить следующим образом:
В более подробном виде существо предлагаемого подхода заключается в следующем. Пусть имеется расширяемый спектр химических веществ: (X1, X2, ..., Xk) = {XJ}, где k - велико. Указанный набор {XJ} влияет на некоторые важнейшие биологические функции человеческого организма и/или экосистемы, например: F1 - активность дыхательной системы; F2 - активность пищеварительной системы; F3 - выживаемость; F4 - мутагенность; F5 - ростовая активность и др. К настоящему времени существуют многие интересные биотесты, например, люциферазный, тесты на генотокичность и др.
Из общих соображений следует, что множество целевых функций (F1, F2, ..., Fp) = {Fr}, r = 1, 2, ..., р, хотя и может расширяться (размерность р растет в процессе изучения), но, по-видимому, в пределе существует базис, т.е. набор конечного числа (m) независимых функций (р = m). Эти функции таковы, что не существует связи W, для которой W(F1, F2, ..., Fm) = 0; при этом любая Fr (r > m) может быть выражена через базис. Ясно, что целевые функции зависят от расширяющегося химического спектра {XJ}: Fr(X1, X2, ..., Xk). Под интегральными показателями (назовем их биотестами) будем понимать такие показатели: (T1, T2, ..., Tn) = {Ti}, i = l, 2, ..., n, которые зависят от {XJ}: Ti(X1, X2, .,., Xk) и, в свою очередь, целевые функции в общем случае могут быть выражены через Тi: Fr(T1, T2, ..., TJ), r = 1, 2, ..., m. При лабораторном "конструировании" биотестов (например, люциферазных) или использовании естественных вариантов, предпочтительнее ситуация, когда Fi(Ti), т.е. "каждой целевой функции - свой биотест".
Таким образом, функции TJ являются промежуточными показателями между спектром веществ и целевой функцией: {XJ} ® {TJ} ® Fr. Можно показать, что если {TJ} и {Fr} образуют базисы, то m < n, т.е. число биотестов не меньше числа тестируемых функций. Если между биотестами обнаруживается корреляция, что часто рассматривается экспериментаторами как достоинство, то это значит, что как минимум один из биотестов должен быть исключен из базиса.
Одна из очевидных областей приложения биотестов - это alarm-test, т.е. экспресс-сигнализатор неблагоприятного воздействия среды на тестируемую функцию в данном месте. В таком случае, это место должно детально анализироваться химическими методами для нахождения "химической" причины биотоксичности.
Вторая абсолютно новая область - это предсказание и расчет значения {TJ} для реальной экосистемы. Огромное потенциальное преимущество биотестов заключается в том, что множество {TJ} образует "полное событие" и добавление новых химических или иных компонентов не расширяет этого множества. Тогда, если удастся построить замкнутую модель динамики {TJ} для данной экосистемы, то предсказание, например, качества воды будет осуществляться прямо в терминах и единицах биотестов, которые через заранее определенные функции FJ(T1, T2, ..., TJ) пересчитываются в "медицинские" последствия или целевые функции. Для FJ вводится понятие "зона толерантности", т.е. пределы нормы: Fj,min < Fj < Fj,max, j = 1, 2, ..., m. Параметры Fj,min и Fj,max выполняют роль, подобную ПДК, но лишены их основных недостатков: зависимости ПДК от характера одновременного действия нескольких веществ и широты химического спектра. Обратным ходом, исходя из вида FJ(T1, T2, ..., TJ), соответственно, рассчитываются границы норм для биотестов {Тi}.
Если конструировать уравнения экосистем, в которые наравне с биотестами {TJ} входят гидрохимические {HXk} и гидробиологические {НВl} компоненты, то никакого принципиального облегчения в процедуре предсказания мы не получим. Это будут все те же "редукционистские" модели. Надо заметить, что на этапе исследования возможно включение всех трех групп компонент {TJ, HXk, НВl}, однако конечная цель - это замкнутая система дифференциальных уравнений (для гомогенного случая) в виде:
{dTj/dt} = Rj,v(T1, ..., Tn; T1.0, ..., Tn.0), j = l, ..., n,
где Ti.0 - входные "потоки" биотестов в экосистему; Rj,v - вид уравнений.
Эти уравнения и соответствующие им динамики могут называться экологическими законами интегральных биотестов. Ситуация очень напоминает начальные этапы становления моделей типа Ферхюльста-Перла в области популяционной экологии, когда уравнение S-образной кривой роста популяции выписывалось на основании экспериментальных данных только по динамике численности популяции X(t) без привлечения тонких механизмов лимитирования роста недостатком субстрата или торможения продуктами метаболизма. Индекс v в приведенном уравнении характеризует такое важнейшее понятие, как "тип экосистемы", в основе которого лежит представление (гипотеза) о возможной дискретности типов функционирования экосистем по динамике некоторых интегральных показателей, например, самоочищения. Видимо, при разработке концепции типизации водных экосистем должны также привлекаться такие показатели трофического статуса, как олиго-, мезо- и политрофный тип водоема.
Подводя итоги перспективы этого биофизического направления, можно сказать, что в идеальном случае возможным станет определение важнейших показателей состояния экосистем, используя непосредственно измеряемые интегральные показатели - биотесты. Число их будет невелико и много меньше числа химических веществ. Тогда логика построения "холистических" прогнозных моделей видится как следующая процедура:
Очевидно, что химический контроль и биотесты не антагонисты и прекрасно дополняют друг друга: химический контроль в первую очередь должен проводиться в тех местах водоема, в которых биотесты показали тревожную ситуацию. Возможно, что биотесты станут новым важным инструментом контроля среды ХХI века. Стратегическая задача заключается в разработке единой логически выверенной методологии и системы биотестирования, в которой органически располагается "мозаика" конкретных биотестов.
| Назад
|
Начало |
Список
|
На главную
|

