| Дальше
|
Назад |
Начало |
Конец |
Список
|
3
.3.2. Классификация алгоритмов комплексацииКоллектив предикторов
g чаще всего представляют в виде линейной комбинации из базового или суженного (наиболее информативного) множества исходных предикторов: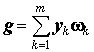
где
yk - вектор расчетных значений, полученных по k-му индивидуальному алгоритму для каждого момента времени, k=(1, 2, ..., m), w k - вектор неизвестных коэффициентов.Задача комплексации эквивалентна определению совокупности векторов w
k, удовлетворяющих заданным ограничениям и минимизирующим некоторый критерий качества.Число различных алгоритмов синтеза непрерывных коллективных предикторов постоянно возрастает, а их классификация может быть весьма условной. Тем не менее выделим алгоритмы комплексации без адаптации, в которых предполагается, что компоненты вектора весовых коэффициентов w
k неизменны для всех моментов времени (вектор превращается в скалярную величину), и алгоритмы с адаптацией, если элементы вектора w k пересчитываются (адаптируются) при переходе от точки t к точке t+1.К группе алгоритмов без адаптации могут быть отнесены следующие:
g
= F( y1, y2, ..., ym; t)использует многорядный алгоритм МГУА (Брусиловский, Розенберг, 1983);
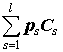
где
ps - задаваемые исследователем неотрицательные весовые коэффициенты (приоритеты) отдельных критериев Cs;К адаптивным алгоритмам относятся алгоритмы Бейтса-Гренджера (Bates, Grander, 1965), Ньюболда-Гренджера (Newbald, Grander, 1974), Лукашина (1979) и др.
Очевидно, что подавляющее большинство неадаптивных алгоритмов комплексации основано на тривиальных методах обработки многомерных наблюдений.
Обозначим как G1 коллективный прогноз временного ряда NH4+ , полученный как среднее арифметическое сопряженных значений по 8 описанным выше индивидуальным моделям.
Использование описанного выше шагового метода получения регрессионной модели дает следующее линейное уравнение:
G2
= -44.5 + 0.832 R2 + 0.48 R8 + 0.779 R7 - 0.748 R5.Если в регрессионном уравнении учесть также все парные взаимодействия индивидуальных прогнозов, то коллективный предиктор будет иметь вид:
G3
= 59.6 - 0.203 R1 - 0.6 R8 + 0.00973 R2 R8 + 0.0138 R7 R8 -- 0.0079 R5 R8 - 0.0024 R6 R8 - 0.0033 R4 R8.
Аналогичная модель, полученная по комбинаторному алгоритму МГУА (см. описание в разд. 3.2.3) с использованием внутреннего критерия - среднеквадратической ошибки на всей выборке, выражается следующим полиномиальным уравнением
G4
= 0.5805 R7 - 0.1864 R8 + 0.0098 R2 R8 - 0.002 R6 R8 - 0.0024 R1 R5.Более строгий подход к специфике и исходным предпосылкам синтеза коллектива предикторов демонстрирует алгоритм Дикинсона-Ершова, общее описание которого приводится ниже.
Пусть исходные предикторы, входящие в базовый набор, удовлетворяют следующим условиям:
На компоненты вектора w
k налагаются ограничения нормировки: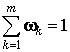 , w
k > 0 , k = 1, 2, ..., m ,
, w
k > 0 , k = 1, 2, ..., m ,
С учетом сделанных допущений, дисперсия ошибки коллективного предиктора вычисляется по формуле
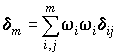
Минимизируя d
m методом неопределенных множителей Лагранжа: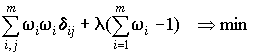
легко получить искомый вектор весовых коэффициентов w
opt.На практике дисперсии ошибок d
ij оказываются неизвестными, поэтому Дж.Дикинсон (Dikinsen, 1975) предлагает использовать их оценки Sij. Э.Б.Ершов (1975) для определения w opt применял метод максимального правдоподобия и постулировал нормальность совместного распределения ошибок индивидуальных предикторов, входящих в базовый набор.Kоллектив предикторов Дикинсона-Ершова для набора исходных моделей
R1-R8 ряда NH4+ имеет вид:G5
= -20.088 - 0.144 R1 + 0.9597 R2 + 0.0746 R3 - 0.359 R4 - 1.153 R5 + 0.045 R6 + 1.247 R7 + 0.331 R8Интересно отметить, что во всех синтезированных коллективах
G2-G5, если ориентироваться на коэффициенты уравнений, достаточно скромный вклад вносит наилучшая исходная модель R2 (и уж совсем незаметна индивидуально сильная модель сплайновой интерполяции R3). В то же время неожиданную "популярность" приобрела весьма специфическая модель полигармоничного тренда R8, совсем не блиставшая в рейтинге индивидуалов. Этот факт служит подтверждением высказанного выше тезиса о ценности для коллектива "зерен нетривиальности", рассыпанных в исходных моделях.Алгоритм Бейтса-Гренджера, в его каноническом описании, предназначен для синтеза коллектива, имеющего минимальную возможную дисперсию ошибки по двум исходным моделям
y1 и y2:gi
= w i Ri1 + (1 - w i) Ri2, i = 1,2,...,n.При этом постулируются все исходные допущения, декларированные в методе Дикинсона-Ершова, а вектор w
i можно рассматривать как оценку вектора w opt, вычисленную в точке i в условиях отсутствия достоверной информации об элементах ковариационной матрицы ошибок. Для расчета вектора весовых коэффициентов используют различные адаптационные процедуры, обладающие необходимыми свойствами сходимости и эффективности.Для того, чтобы алгоритм Бейтса-Гренджера мог быть использован в случае произвольного числа исходных предикторов, применяют специально разработанные многошаговые и комбинированные процедуры.
Сравнительный анализ эффективности каждого из рассмотренных методов комплексации проведем с использованием знакомого нам по предыдущему разделу набора критериев:
|
№ модели |
Средне-квадра-тич. ошибка |
Cредний модуль ошибки |
Макси-мальный модуль ошибки |
Критерий регуляр- ности |
Коэффи-циент корре-ляции |
Критерий Дарбина-Уотсона |
|
G1 |
58.4 |
38 |
277 |
0.739 |
0.711 |
1.49 |
|
G2 |
47.8 |
34 |
218 |
0.605 |
0.797 |
1.93 |
|
G3 |
42.8 |
30.7 |
178 |
0.541 |
0.841 |
1.93 |
|
G4 |
43.9 |
31 |
210 |
0.556 |
0.831 |
1.91 |
|
G5 |
47.9 |
34.2 |
197 |
0.607 |
0.796 |
1.87 |
|
G6 |
54.2 |
36.9 |
276 |
0.686 |
0.727 |
1.71 |
Использованные в таблице номера соответствуют следующим коллективам предикторов:
Нетрудно заметить, что безусловным аутсайдером по всем критериям оценки является простое усреднение частных прогнозов (
G1). Это естественно, поскольку составить работоспособный коллектив без учета уровня компетентности его членов - невыполнимая задача в любой сфере деятельности. Не претендуя в настоящей работе на глобальные обобщения, следует отметить явное преимущество нелинейных регрессионных методов (G3) и алгоритмов МГУА (G4) над другими процедурами. Они позволяют расширить класс функций, в котором ищется предиктор-коллектив, до класса полиномов произвольной степени от многих аргументов и использовать в качестве целевой функции не только дисперсию ошибок, но и любой другой критерий. Кроме того, для их применения не требуется выполнения условия нормировки весовых коэффициентов.График интерполяции ряда NH
4+ коллективом предикторов, полученный с помощью нелинейной регрессионной модели (G3), представлен на рис. 3.9.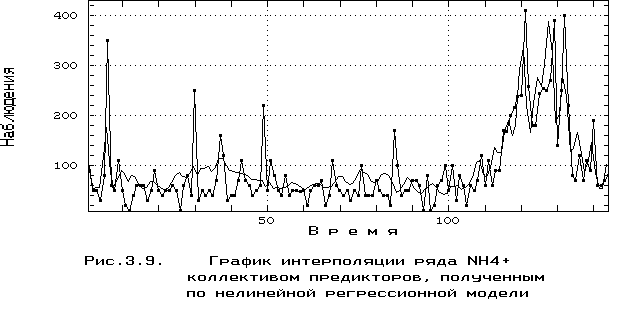
| Дальше
|
Назад |
Начало |
Конец |
Список
|