| Вперед
|
Назад
|
Конец |
Список
|
2. Оценка доверительного интервала, вариансы и статистической ошибки показателя PST
Оценка доверительного интервала (например, 95 %) для полученного показателя фенетической дифференциации исследованной популяции B.bidens PST может быть произведена тремя различными способами. Они дают разные оценки нижней и верхней доверительной границ.
а) Оценка 95 % доверительного интервала для PST, используя распределение Хи-квадрат.
Нижняя PST(L) и верхняя PST(U) доверительные границы в этом случае рассчитываются по формулам:
|
|
(1.4) |
|
|
(1.5) |
где χ2U – табличное значение распределения Хи-квадрат для α = 0,975 и числа степеней свободы df = s – 1; χ2L – табличное значение распределения Хи-квадрат для α = 0,025 и числа степеней свободы df = s – 1.
Для исследованной популяции наземного моллюска B.bidens доверительные границы показателя фенетической дифференциации, соответственно, будут равны:
 ,
,
 .
.
Таким образом, интервальная оценка искомого показателя составляет [0,0133; 0,0782].
б) Оценка 95 % доверительного интервала для PST, используя F-распределение Фишера-Снедекора.
Нижняя PST(L) и верхняя PST(U) доверительные границы в этом случае рассчитываются по формулам:
|
|
(1.6) |
|
|
(1.7) |
где
|
|
(1.8) |
|
|
(1.9) |
где F – оценка дисперсионного отношения, полученная в результате проведения ДА; F1 – табличное значение критерия Фишера-Снедекора для α = 0,025; df1 = s – 1; df2 = N – s; F2 – табличное значение критерия Фишера-Снедекора для α = 0,975; df1 = s – 1; df2 = N – s. Значение n* рассчитывается по формуле (1.3).
Для исследованной популяции наземного моллюска B.bidens доверительные границы показателя фенетической дифференциации, соответственно, будут равны:

 ;
;  ,
,
 ;
;  .
.
Таким образом, интервальная оценка искомого показателя составляет [0,0030; 0,1129].
в) Оценка 95 % доверительного интервала для PST, используя метод “спуска по лестнице”.
В основе данного метода лежит принцип Resampling, т.е. отбора с возвращением множества новых выборок равного объема n из одной и той же генеральной совокупности того же объема. Например, в выборку № 2 попало 93 особи B.bidens из которых 58 имели раковины с пигментными пестринами. Мы начинаем формировать из этой же выборки новую того же объема. Для этого отбираем первую случайным образом выбранную особь, отмечаем ее фен (с пестринами или без) и возвращаем обратно. Далее отбираем вторую особь, отмечаем ее фен и вновь возвращаем обратно. И так далее, еще 91 раз. В итоге мы имеем новую выборку. Для нее уже частота встречаемости особей с пигментными пестринами на раковине не обязательно будет составлять 58 (даже, скорее всего, эта величина будет иной). Таким же образом формируем вторую выборку, третью и т.д. Например, повторяем эту процедуру 10 раз.
Аналогично, сформируем по 10 новых выборок для оставшихся 10 субпопуляций.
Конечно, на самом деле поступать таким образом – это очень долго и не обязательно. Поскольку мы имеем выборочную частоту (например, для второй выборки она составляет 0,624; см. табл. 1.1) и объем выборки, мы можем использовать генератор случайных цифр, который будет генерировать нам такие выборки, учитывая, что они имеют биномиальное распределение с n = 93 и p = 0,624. (Такой генератор случайных цифр имеется в MS Excel и других статистических пакетах.)
В таблице 1.4 приведены частоты искомого признака в 10 сгенерированных выборках для каждой из 11 субпопуляций.
Таблица 1.4
|
Субпопуляция |
|||||||||||
|
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
|
1 |
56 |
46 |
34 |
34 |
17 |
28 |
43 |
16 |
31 |
11 |
37 |
|
2 |
52 |
51 |
37 |
38 |
15 |
28 |
44 |
18 |
33 |
12 |
38 |
|
3 |
58 |
40 |
28 |
33 |
15 |
26 |
45 |
17 |
32 |
13 |
35 |
|
4 |
55 |
42 |
41 |
30 |
13 |
34 |
51 |
17 |
32 |
16 |
38 |
|
5 |
55 |
48 |
43 |
33 |
11 |
23 |
49 |
18 |
28 |
11 |
36 |
|
6 |
61 |
46 |
38 |
33 |
13 |
20 |
52 |
16 |
28 |
15 |
37 |
|
7 |
50 |
44 |
39 |
42 |
15 |
29 |
45 |
18 |
28 |
11 |
38 |
|
8 |
56 |
44 |
35 |
37 |
13 |
23 |
42 |
16 |
19 |
14 |
34 |
|
9 |
64 |
31 |
33 |
38 |
13 |
34 |
46 |
18 |
27 |
8 |
36 |
|
10 |
58 |
42 |
42 |
32 |
13 |
25 |
45 |
16 |
28 |
14 |
37 |
Поскольку оцененная нами частота признака в выборке № 2 (т.е. 58 из 93) есть величина случайная и с равным успехом она могла быть и 56, и 52, и 55, и т.д., равно как и для любой другой субпопуляции, мы подставляем вместо 58 величину 56 и получаем новое псевдозначение показателя фенетической дифференциации популяции PST. Далее, вместо значения 43 для выборки № 3 подставляем величину 46 и получаем очередное псевдозначение показателя PST. Таким образом поступаем, пока не подставим все значения первой сгенерированной выборки для всех 11 субпопуляций. Затем переходим ко второму значению для субпопуляции № 2 и т.д. И так постепенно мы подставляем все полученные с помощью генератора случайных цифр значения.
Этот процесс перебора сгенерированных псевдозначений напоминает спуск по лестнице. Шаги по ступеням отражает пошаговая замена значений псевдозначениями от первой субпопуляции до последней, а переход от одной строки матрицы псевдозначений к следующей – переход по лестничной площадке. Поэтому мы и назвали этот метод “спуском по лестнице”.
В итоге, мы получили 110 псевдозначений PST, которые приведены в таблице 1.5.
Минимальное из них составляет 0,0063, а максимальное – 0,1126 (в табл. 1.5 они выделены жирным шрифтом). Для этой совокупности оценок PST мы найдем перцентиль 0,025 (PST = 0,0209) и 0,975 (PST = 0,0911). Эти оценки и можно принять за нижнюю и верхнюю границы 95 % доверительного интервала, соответственно.
Таким образом, интервальная оценка искомого показателя составляет [0,0209; 0,0911].
Таблица 1.5
|
0,0273 |
0,0248 |
0,0395 |
0,0421 |
0,0219 |
0,0734 |
0,0705 |
0,1126 |
0,0388 |
0,0821 |
0,0396 |
|
0,0292 |
0,0277 |
0,0492 |
0,0429 |
0,0219 |
0,0744 |
0,0811 |
0,1113 |
0,0403 |
0,0853 |
0,0385 |
|
0,0311 |
0,0365 |
0,0367 |
0,0316 |
0,0282 |
0,0829 |
0,0791 |
0,0769 |
0,0589 |
0,0853 |
0,0301 |
|
0,0298 |
0,0345 |
0,0306 |
0,0315 |
0,0379 |
0,0759 |
0,0791 |
0,0576 |
0,0537 |
0,0663 |
0,0301 |
|
0,0296 |
0,0415 |
0,0446 |
0,0318 |
0,0379 |
0,0685 |
0,0833 |
0,0591 |
0,0512 |
0,0745 |
0,0491 |
|
0,0267 |
0,0405 |
0,0355 |
0,0225 |
0,0395 |
0,0679 |
0,0868 |
0,0556 |
0,0803 |
0,0771 |
0,0469 |
|
0,0215 |
0,0405 |
0,0355 |
0,0216 |
0,0408 |
0,0655 |
0,0911 |
0,0595 |
0,0837 |
0,0474 |
0,0445 |
|
0,0209 |
0,0418 |
0,0408 |
0,0229 |
0,0394 |
0,0613 |
0,0889 |
0,0523 |
0,0685 |
0,0513 |
0,0422 |
|
0,0209 |
0,0433 |
0,0428 |
0,0063 |
0,0457 |
0,0613 |
0,0895 |
0,0523 |
0,0753 |
0,0575 |
0,0383 |
|
0,0213 |
0,0402 |
0,0413 |
0,0219 |
0,0797 |
0,0570 |
0,0895 |
0,0539 |
0,0818 |
0,0538 |
0,0419 |
В таблице 1.6 приведены полученные оценки нижней и верхней границ 95% доверительного интервала для выборочной оценки показателя фенетической дифференциации популяции PST, полученные разными методами.
Таблица 1.6
|
Метод |
95 % доверительный интервал для PST |
|
|
нижняя граница |
верхняя граница |
|
|
основан на распределении Хи-квадрат |
0,0133 |
0,0782 |
|
основан на F-распределении Фишера-Снедекора |
0,0030 |
0,1129 |
|
“спуска по лестнице” |
0,0209 |
0,0911 |
Если оценить саму процедуру оценивания границ доверительного интервала PST (с одной стороны затраты времени, а с другой – точность оценки), то, конечно, метод “спуска по лестнице” является самым продолжительным по затратам времени (если, конечно, полностью не автоматизировать процесс перебора значений), но и самый точный. Из двух оставшихся, процедура оценивания нижней и верхней границ доверительного интервала, основанный на распределении Хи-квадрат, является наименее точным, поскольку в случае отрицательных значений выборочной оценки PST, дает абсурдные значения. Метод, основанный на F-распределении, дает самые широкий доверительный интервал. Однако, во-первых, он полностью базируется на результатах ДАКП (на оценке дисперсионного отношения). А во-вторых, при отрицательных значениях выборочной оценки PST дает полностью реальные величины границ. Характерно, что граничные оценки, полученные с помощью метода, основанного на F-распределении, близки к минимальной и максимальной оценкам, полученным с использованием метода “спуска по лестнице”.
Не менее затруднительным этапом анализа является процесс оценивания статистической ошибки выборочной величины PST. Эта процедура также основывается на Resampling-процедуре (вернее, ее различных вариантах).
Первым делом необходимо получить выборку из значений jackknifing-оценок PST. Это можно сделать следующим образом. Удаляем из исходной таблицы ДАКП первое значение (для субпопуляции № 2), т.е. 58 из 93 и рассчитываем значение PST, основываясь на оставшихся 10 значениях. Далее удаляем значение для субпопуляции № 3 (43 из 67) и опять рассчитываем значение PST. Так повторяем 11 раз (столько, сколько имеется субпопуляций) и получаем 11 псевдозначений PST. Эта процедура называется оцениванием с помощью метода “складного ножа” (jackknife estimated).
В таблице 1.7 приведены псевдозначения PST, полученные при удалении значений для каждой субпопуляции последовательно.
Таблица 1.7
|
Субпопуляция |
||||||||||
|
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
0,0349 |
0,0331 |
0,0327 |
0,0283 |
0,0286 |
0,0130 |
0,0225 |
0,0298 |
0,0268 |
0,0300 |
0,0157 |
Среднее значение  и вариансу Var(PST) можно теперь оценить, основываясь на этой выборке псевдозначений jackknife-оценок PST:
и вариансу Var(PST) можно теперь оценить, основываясь на этой выборке псевдозначений jackknife-оценок PST:
|
|
(1.10) |
|
|
(1.11) |
где  - jackknife-оценка PST, полученная в результате удаления значений для i-той субпопуляции (т.е. значения, приведенные в табл. 1.7).
- jackknife-оценка PST, полученная в результате удаления значений для i-той субпопуляции (т.е. значения, приведенные в табл. 1.7).
Для анализируемой популяции B.bidens соответствующие значения будут равны:
 ,
,
 .
.
Статистическая ошибка полученной величины PST рассчитывается как корень квадратный из вариансы; в нашем случае эта величина равна:
|
|
(1.12) |
“Исправленную” оценку выборочного значения величины PST можно получить, используя bootstrap-процедуру. Ее суть заключается в том, что из выборки jackknife-оценок PST мы формируем новую псевдовыборку того же объема (т.е. n = 11), используя процедуру отбора значений с возвращением. Аналогичным образом формируется обычно большое число псевдовыборок (например, 1000, 5000, 10000 или больше). Для каждой из сгенерированных псевдовыборок рассчитывается среднее значение. Как правило, закон распределения этих оценок близок к нормальному. Поэтому для них применяются стандартные процедуры оценивания выборочной статистической ошибки.
Конечно, данная процедура требует больших затрат времени работы, поэтому редко используется при неавтоматизированном анализе (т.е. “вручную”). Многие современные статистические пакеты содержат блок программ RESAMPLE, в которым имеются jackknife- и bootstrap-процедуры. Мы можем рекомендовать пакет статистических программ S-PLUS 2000 фирмы MathSoft Inc. Кроме того, имеются специальные программы, предназначенные только для использования Resample-процедур. Например, мы использовали программу Resampling Procedures 1.3 (2001), созданную David C. Howell (University of Vermont). Бесплатную версию этой программы можно “скачать” с сайта автора.
На рисунке 1.3 приведен график распределения bootstrap-оценок среднего значения величины PST для 1000 псевдовыборок.
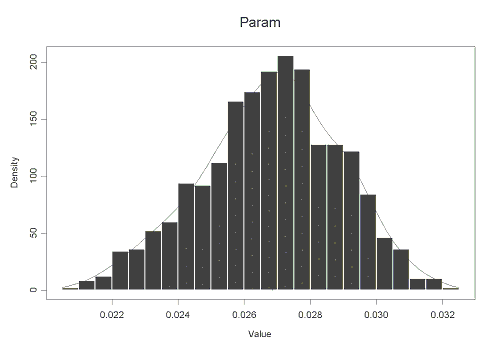
Рис. 1.3. Распределение средних значений PST для 1000 псевдовыборок
Bootstrap-оценка для среднего значения PST составляет 0,0269 (с 95 % доверительным интервалом от 0,0218 до 0,0302). Таким образом, точечная оценка показателя фенетической дифференциации исследуемой популяции B.bidens в отношении признака наличие/отсутствие на раковине пигментных пестрин (полученная bootstrap-методом) составляет PST ± SEPST = 0,0269±0,0213 (т.е. расхождение с величиной, полученной с помощью jackknife-метода в четвертом знаке после запятой; см. выше).
Теперь, получив все необходимые оценки, можно сделать общий вывод о степени фенетической дифференциации исследуемой популяции B.bidens в отношении признака наличие/отсутствие на раковине пигментных пестрин.
Результаты ДАКП (табл. 1.3) свидетельствуют о том, моллюски из 11 субпопуляций, включенных в анализ достоверно различаются по частоте встречаемости данного признака (получено значение дисперсионного отношения F = 2,378 с уровнем значимости p = 0,0092). Следовательно, доказано наличие фенетической дифференциации. Оценкой ее степени является показатель PST, точечная оценка которого равна 0,0269±0,0213, а 95 % доверительный интервал (используя F-распределение Фишера-Снедекора) включает интервал значений [0,0030; 0,1129]. Поскольку этот интервал не содержит нуля, подтверждается вывод о пространственной гетерогенности анализированной популяции в отношении частоты встречаемости рассматриваемого признака.
| Вперед
|
Назад
| Начало |
Список
|
 ,
, ,
, ,
, ,
, ;
; ,
, ,
, ,
, .
.