| Дальше
|
Назад |
Начало |
Конец |
Список
|
5.6. Непараметрическая корреляция и регрессия
Формулировка задачи
Исходные условия те же, что и для регрессионного анализа: т.е. имеется две группы сопряженных наблюдений
X
º (x1, ..., xm) и Y = (y1, ..., ym) .Если есть сомнения в применимости гауссовой модели распределения данных (а они, в большинстве случаев, небезосновательны), то для оценки связи между переменными
Y и X можно воспользоваться некоторыми альтернативами метода наименьших квадратов. Обсуждая в разделе 5.4 измерения в порядковых (ординальных) шкалах, мы убедились, что реальным содержанием этих измерений является тот порядок, в котором выстраиваются объекты по степени выраженности измеряемого признака. Порядковый номер числа в таком отсортированном списке называется его рангом.Необходимо оценить степень влияния признака
X на степень выраженности отклика Y. Если такого влияния нет, то справедлива нулевая гипотеза Но о независимости порядковых признаков. Решение этой задачи будем искать, основываясь на рангах измерений.Рекомендуемая литература та же, что и для раздела 5.4.
Математический лист
Пусть каждому i-му измерению приписана пара натуральных чисел (ri, si), где ri – ранг xi среди чисел (x1, ..., xm), а si – ранг yi среди чисел (y1, ..., ym). Будем при этом считать, что среди рядов чисел Х и Y нет повторяющихся значений, так что переход к рангам вопросов не вызывает.
Если признаки Х и Y взаимосвязаны, то последовательность рангов r1, r2, …, rm влияет на ранговую последовательность s1, s2, …, sm; в противном случае порядок среди Y случаен по отношению порядка среди Х. Поэтому центральным моментом обсуждения гипотезы Ho является оценка, насколько являются ранги s1, s2, …, sm равновозможными (т.е. равновероятными) при любом порядке чисел r1, r2, …, rm. Вторым важным моментом является выбор меры сходства двух наборов рангов.
Коэффициент ранговой корреляции, предложенный в 1900 г. знаменитым психологом Ч. Спирменом, основан на том, что близость этих двух рядов чисел отражает величина:
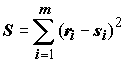 ,
, (5.93)
(5.93)
которая варьируется от 0 , если последовательности полностью совпадают, до (
m3 – m)/3, когда последовательности рангов полностью противоположны.Нормированный по своему максимальному значению, коэффициент ранговой корреляции Спирмена
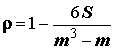 (5.94)
(5.94)
варьирует от +1 до –1 и свои крайние значения принимает в случаях полной предсказуемости одной ранговой последовательности по другой. Заметим, что значение
S не зависит ни от значения первого номера последовательности, ни от порядка сортировки.Другой коэффициент ранговой корреляции, получивший популярность после работ М. Кендалла, в качестве меры сходства между двумя ранжировками использует минимальное число перестановок, которое надо осуществить между соседними объектами, чтобы одно упорядочение объектов превратить в другое.
Статистику Кендалла К подсчитывают следующим образом. Выстраивают сопряженные наблюдения в порядке возрастания признака
X и для каждого значения yi определяют его ранг si. На последовательности рангов s1, s2, …, sm определяют количество инверсий, т.е. нарушений порядка следования. Например, при m = 4 и последовательности рангов {4, 3, 1, 2} имеем количество инверсий (суть – статистику Кендалла) K = 3 + 2 = 5, где 3 – количество инверсий для числа 3 и 2 – количество инверсий для числа 3. Наименьшее возможное значение К = 0 получается при полном совпадении ранговых последовательностей, наибольшее K = m(m -1)/2 – при полной их противоположности.Коэффициент ранговой корреляции по Кендаллу представляет собой статистику, нормированную по ее максимуму, и изменяется в тех же пределах, что и коэффициент корреляции Спирмена
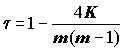 .(5.95)
.(5.95)
Статистика t
Кендалла эквивалентна r Спирмена как по мощности, так и по выполнению основных предположений. Обычно, однако, числовые значения r Спирмена и t Кендалла различны, потому что они отличаются как своей внутренней логикой, так и способом вычисления. Более важно то, что статистики Кендалла и Спирмена имеют различную интерпретацию: если коэффициент корреляции Спирмена может рассматриваться как прямой аналог коэффициента корреляции r Пирсона, вычисленный по рангам, то статистика Кендалла скорее основана на подсчете вероятностей (выражаясь более точно, проверяется наличие различий между вероятностями порядка расположения наблюдаемых данных для двух величин).Если в данных имеется много совпадающих значений, то предпочтительнее использовать третью ранговую статистику g – критерий, который по своей интерпретации и вычислениям эквивалентен статистике Кендалла, за исключением того, что совпадения явно учитываются в нормировке. Выражаясь кратко, g
представляет собой разность между вероятностью того, что ранговый порядок двух переменных совпадает, минус вероятность того, что он не совпадает, деленную на единицу минус вероятность совпадений.Для проверки предположения об отсутствии связи между признаками надо вычислить выборочное значение любого коэффициента ранговой корреляции и сравнить его с критическим значением для данного уровня значимости. Нулевую гипотезу
Ho следует отвергнуть, если полученное в опыте значение коэффициентов r или t по модулю превосходит критическое.Критические значения ранговых критериев можно найти по таблицам, либо вычислить по приближенным формулам, которые основаны на том, что при
Ho и с увеличением m распределение случайных величин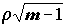 и
и 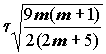 асимптотически приближается к стандартному нормальному закону N(0,1).
асимптотически приближается к стандартному нормальному закону N(0,1).
Результаты расчетов
В результате гидробиологических наблюдений установлено, что при загрязнении водоемов происходит закономерное изменение соотношения численности личинок хирономид подсемейств Chironominae, Orthocladiinae и Tanypodinae. Ортокладиины обычно доминируют в чистых водах, таниподины – в загрязненных, что дало основания Е.В. Балушкиной предложить индекс, отражающий соотношение обилия представителей этих трех подсемейств и описанный в разделе 4.2.
Проверим справедливость этого предположения с использованием ранговых критериев r , t и g (см. табл. 5.19, где приведены статистики и соответствующие им значения вероятностей р). Расчет был выполнен по выборке из 88 наблюдений, а в качестве показателя загрязнения водоема использовались значения биологического потребления кислорода БПК5.
Таблица 5.19
Корреляция между БПК
5 и обилием различных групп личинок хирономид с использованием ранговых критериев|
Наименование показателя и подсемейства хирономид |
Коэффициент Спирмена |
Коэффициент Кендалла |
Статистика g |
|||
|
r |
p |
t |
p |
g |
p |
|
|
N Chironominae |
-0.162 |
0.131 |
-0.108 |
0.135 |
-0.110 |
0.135 |
|
N Orthocladiinae |
-0.271 |
0.011 |
-0.196 |
0.007 |
-0.253 |
0.007 |
|
N Tanypodinae |
-0.205 |
0.055 |
-0.141 |
0.051 |
-0.161 |
0.051 |
|
А Chironominae |
0.190 |
0.076 |
0.129 |
0.076 |
0.135 |
0.076 |
|
А Orthocladiinae |
-0.251 |
0.018 |
-0.185 |
0.011 |
-0.238 |
0.011 |
|
А Tanypodinae |
-0.159 |
0.139 |
-0.113 |
0.118 |
-0.128 |
0.118 |
|
Индекс Балушкиной |
0.251 |
0.018 |
0.185 |
0.011 |
0.238 |
0.011 |
Примечание
: жирным шрифтом выделены строки со значимым влиянием фактораПроведенные расчеты позволяют сделать следующие выводы.
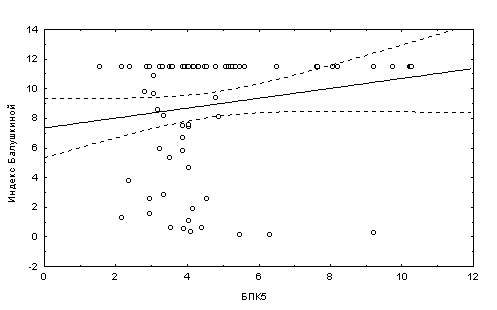
Представляемый пример демонстрирует также высокую технологичность ранговых коэффициентов корреляции по сравнению с коэффициентом корреляции Пирсона в условиях негауссовых распределений анализируемых выборок. Для доказательства этого выполним параллельный расчет уравнений линейной регрессии классическим методом наименьших квадратов (графики рассчитанных зависимостей представлены на рис. 5.15):
NOrt = 107.23 - 7.02 * БПК5
|
|
|
Рис. 5.15. Графики зависимостей численности ортокладиин и индекса Балушкиной от значения БПК
5Поскольку основные предположения регрессионного анализа на этих выборках не выполняются, полученные уравнения и коэффициенты корреляции оказались недостоверными. В то же время, использование непараметрических критериев дало уверенное заключение о наличии такой связи.
| Дальше
|
Назад |
Начало |
Конец |
Список
|