| Дальше
|
Назад |
Начало |
Конец |
Список
|
5.5. Задача о законе влияния фактора: линейный регрессионный анализ
Мем № 29
: “Теоретическая кривая никогда не проходит в точности через все точки, полученные в результате измерений…” В. Фукс [1975].Формулировка задачи
Пусть имеется две группы числовых переменных
X º (x1 , ..., xp) и Y º (y1 ,..., ym), причем предполагается, что Х – независимая переменная (фактор) влияет на значения Y – зависимой переменной (отклик). В общем случае предполагается, что обе переменных измерены в количественных шкалах (интервальной, абсолютной или шкале отношений). Также постулируется независимость самих измерений, т.е. одни наблюдения не оказывают систематического влияния на другие.Предположим, что из совокупности наблюдений
X-Y может быть укомплектована репрезентативная обучающая выборка (Xi , Yi), i = 1, ..., n сопряженных измерений, выполненных в идентичных пространственно-временных условиях. Необходимо по имеющейся обучающей выборке построить функцию f (X), которая приближенно описывала бы изменение Y при изменении X: Y »
f(X).
Y »
f(X).
Этой постановке соответствует широкий круг задач, связанных с построением (восстановлением) всевозможных зависимостей по имеющимся эмпирическим данным, т.е. открытие больших и малых законов, начиная от закона всемирного тяготения И. Ньютона и кончая законом Б.Л. Гутельмахера о линейной зависимости логарифма скорости экскреции биогенных элементов от массы тела зоопланктеров.
Статистика как метод исследования в принципе не интересуется причинно-следственной связью явлений. Однако рассмотренные в настоящем разделе методы аппроксимации близки идеям математического моделирования в смысле поиска наилучшей функциональной зависимости. Более того, уравнение кривой, полученной в результате обработки данных наблюдений, может подтолкнуть исследователя к пониманию внутренних взаимосвязей изучаемого явления.
Рекомендуемая литература: [Хальд, 1956; Андерсен, 1963; Себер, 1980; Дрейпер, Смит, 1986; Дюк, 1997; С.А. Прохоров, 2002; Прохоров с соавт. 2003].
Математический лист
Предполагается, что множество допустимых функций, из которого подбирается f(X), является параметрическим: Y » f (X, q ), где q – неизвестный параметр (вообще говоря, многомерный). Если имеет место равенство f (X, q ) = A(q )X, где A(q ) – некоторая матрица коэффициентов, то функция f (X, q ) линейно зависит от параметров q и мы имеем дело с задачей линейного регрессионного анализа.
При построении аппроксимирующей функции будем считать, что
Y
= f (X, q ) + e , (5.66)
где первое слагаемое – закономерное изменение
Y от X, а второе e – случайная составляющая с нулевым средним. Функция f (X, q ) является условным математическим ожиданием Y при условии известного X и называется регрессией Y по X. Слагаемое e отражает как внутреннюю присущую отклику стохастическую изменчивость (ошибку измерения), так и влияние факторов, не учтенных в f (X, q ).Классический регрессионный анализ предполагает, что статистическая природа случайной составляющей является неизменной для всех наблюдений, т.е. e
1, e 2, …, e n статистически независимы в опытах и одинаково распределены. Неоднородность дисперсий ошибок (гетероскедастичность, heteroscedasticity) в целом характерна для гидробиологических данных, поскольку обработке подвергаются показатели, полученные в разные моменты времени, по различным регионам, в различных экспедиционных условиях. Последствия гетероскедастичности могут привести к тому, что вычисленные значения t- и F-отношений уже нельзя рассматривать как наблюдаемые значения случайных величин, имеющих t- и F-распределения, что может приводить к ошибочным статистическим выводам в отношении гипотез о значениях коэффициентов линейной модели.Простая линейная регрессия
Пусть
X и Y одномерные величины, обозначенные как x и y, а функция f(x, q ) имеет вид f (x, q ) = A + bx, где q = (A, b). Относительно имеющихся наблюдений (xi , yi), i = 1, ..., n, полагаем, чтоyi
= A + bxi + e i ,(5.67)
где e
1, ..., e n – независимые (ненаблюдаемые) одинаково распределенные случайные величины.Существует ряд методов подбирать "лучшую" прямую линию, из которых наиболее широко используется метод наименьших квадратов
(МНК), который заключается в следующем. Построим оценку параметра q = (A, b) так, чтобы величиныei
= yi - f (xi, q ) = yi - A - bxi , (5.68)
называемые остатками, были как можно меньше, а именно, чтобы сумма их квадратов была минимальной:
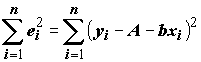 ®
min
®
min
(5.69)
Решение (
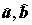 ), для которого сумма квадратов невязок оказывается наименьшей, может быть найдено с использованием выборочных средних
), для которого сумма квадратов невязок оказывается наименьшей, может быть найдено с использованием выборочных средних 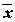 и
и 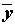 по следующим формулам:
по следующим формулам:
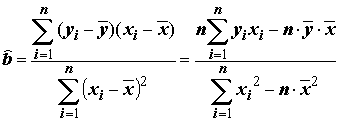
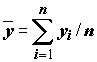 , =
, = 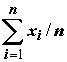 . (5.70)
. (5.70)
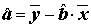
Рассчитать уравнение регрессии не представляет никакой сложности, особенно при наличии компьютера с установленным табличным процессором Microsoft Excel, или любого другого пакета статистических программ. Основные методологические трудности возникают в ходе проверки выполнения априорных предпосылок регрессионного анализа и последующей оценки адекватности полученного уравнения.
Как и в случае дисперсионного анализа, оценка уравнений регрессии предполагает два основных подхода: непараметрический и гауссовый, которые различаются предположениями о характере распределения остатков
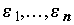 . Гауссова модель простой линейной регрессии предполагает, что случайная величина e
распределена по нормальному закону N(0, s
2) с некоторой неизвестной дисперсией s
2. Сам по себе метод наименьших квадратов в этих предположениях не нуждается, однако в гауссовой модели, во-первых, МНК обладает дополнительными свойствами оптимальности и, во-вторых, оценки неизвестных параметров приобретают ясные статистические свойства.
. Гауссова модель простой линейной регрессии предполагает, что случайная величина e
распределена по нормальному закону N(0, s
2) с некоторой неизвестной дисперсией s
2. Сам по себе метод наименьших квадратов в этих предположениях не нуждается, однако в гауссовой модели, во-первых, МНК обладает дополнительными свойствами оптимальности и, во-вторых, оценки неизвестных параметров приобретают ясные статистические свойства.
Разложение полной суммы квадратов и коэффициент детерминации
Нетрудно, как и для однофакторного дисперсионного анализа, рассчитать полную сумму квадратов вариации отклика 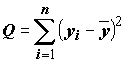 , и две ее составляющие: сумму квадратов объясненную моделью
, и две ее составляющие: сумму квадратов объясненную моделью 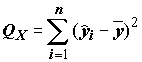 , и остаточную сумму квадратов
, и остаточную сумму квадратов 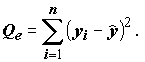 Все эти три суммы квадратов связаны соотношением
Все эти три суммы квадратов связаны соотношением
Q
= Qx + Qe ,(5.71)
которое представляет собой разложение полной суммы квадратов.
Если вариация отклика, объясненная влиянием переменной
X (точнее, уравнением регрессии) Qx ® 0, то полная сумма квадратов соответствует значению Qe. В этой ситуации привлечение информации о значениях переменной X не дает ничего нового для объяснения закономерности поведения Y в наблюдениях, а значит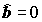 и "наилучшая" прямая имеет вид
и "наилучшая" прямая имеет вид 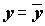 , отрицающий наличие линейной зависимости Y от X.
, отрицающий наличие линейной зависимости Y от X.
Аналогично, тенденция линейной связи между
X и Y выражена в максимальной степени, если Qe = 0 : при этом, все точки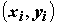 , i = 1, 2,..., n, располагаются на одной прямой.
, i = 1, 2,..., n, располагаются на одной прямой.
Рассмотрим традиционную для дисперсионного анализа
F-статистику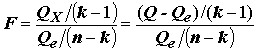 , (5.72)
, (5.72)
где
k = 2 – число степеней свободы простой линейной регрессии. Если остатки распределены нормально 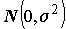 , то F-статистика, рассматриваемая как случайная величина, при справедливости гипотезы H0 (т. е. когда действительно ) имеет стандартное распределение Фишера с (k -1) и (n - k) степенями свободы. В соответствии с этим, нулевая гипотеза отвергается при "слишком больших" значениях F, превышающих пороговое значение
, то F-статистика, рассматриваемая как случайная величина, при справедливости гипотезы H0 (т. е. когда действительно ) имеет стандартное распределение Фишера с (k -1) и (n - k) степенями свободы. В соответствии с этим, нулевая гипотеза отвергается при "слишком больших" значениях F, превышающих пороговое значение 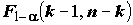 . При этом, вероятность ошибочного отвержения гипотезы
. При этом, вероятность ошибочного отвержения гипотезы 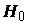 равна a
. Большинство пакетов прикладных программ при анализе статистической значимости уравнения регрессии, наряду со значением F-статистики, приводят соответствующее ему P-значение (P-value), т. е. вероятность
равна a
. Большинство пакетов прикладных программ при анализе статистической значимости уравнения регрессии, наряду со значением F-статистики, приводят соответствующее ему P-значение (P-value), т. е. вероятность 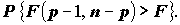
Для оценки тесноты ("меры выраженности") линейной связи принято использовать долю объясненной суммы квадратов, не зависящую от шкал, в которых измерены значения переменных
x и y и называемую часто коэффициентом детерминации: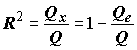 .(5.73)
.(5.73)
Этот коэффициент изменяется в пределах от 0 (при
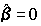 , т. е. Q = Qе) до 1 (при Qe = 0). Чем ближе к 1 значение R2 , тем лучше качество подгонки. При R2 ®
0 можно сделать два вывода: либо фактор не оказывает никакого влияния на отклик, либо функция регрессии имеет существенно нелинейный характер.
, т. е. Q = Qе) до 1 (при Qe = 0). Чем ближе к 1 значение R2 , тем лучше качество подгонки. При R2 ®
0 можно сделать два вывода: либо фактор не оказывает никакого влияния на отклик, либо функция регрессии имеет существенно нелинейный характер.
Коэффициент детерминации тесно связан с другой мерой связи между переменными – выборочным коэффициентом линейной корреляции Пирсона. Пусть определены выборочные дисперсии,
характеризующие степень разброса значений X и Y: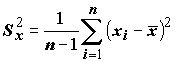 ,
, 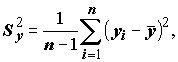 (5.74)
(5.74)
а также выборочная ковариация, характеризующая совместное распределение этих двух выборок в
N-мерном евклидовом пространстве: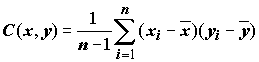 (5.75)
(5.75)
Коэффициент линейной корреляции Пирсона между выборками
Y и X определяется как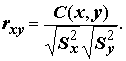 (5.76)
(5.76)
Нетрудно заметить его симметричность, т.е.
rxy = ryx. Констатируем также без доказательств два известных факта: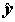 при гауссовских предположениях связаны простой формулой
при гауссовских предположениях связаны простой формулой 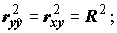
Следует отметить, что традиционные мнения о возможности оценить тесноту линейной связи только по коэффициенту корреляции Пирсона
r (либо его квадратам R2 и h 2) не являются статистически корректными. Например, Я.Я. Вайну [1977] приводит следующую классификацию линейности по r: менее 0.2 – слабая, от 0.2 до 0.4 – слабее средней тесноты, от 0.4 до 0.6 – средняя и т.д. Нетрудно заметить, что коэффициенты корреляции, основанные на сумме квадратов, не учитывают числа степеней свободы, поэтому их сравнение правомочно только для выборок примерно одинаковой размерности. При увеличении числа обработанных измерений статистическая надежность уравнений регрессии по критерию Фишера начинает возрастать, когда как величина коэффициента корреляции чаще всего монотонно снижается.Для удобства интерпретации параметра угла наклона
b иногда пользуются коэффициентом эластичности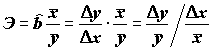 , (5.77)
, (5.77)
который показывает среднее изменение (в долях или %) зависимой переменной
y при изменении фактора х: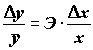 .
.
Доверительные интервалы для коэффициентов и проверка гипотез
Если принять дополнительные предположения о гауссовом характере распределения остатков e 1 , ..., e n , то:
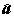 и
и 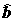 нормально распределены и независимы от дисперсии остатков s
2;
нормально распределены и независимы от дисперсии остатков s
2;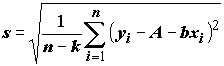 ,(5.78)
,(5.78)
где
k = 2 – число степеней свободы регрессии;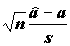 и
и 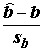 , где
, где 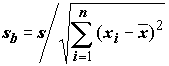 , имеют распределение Стьюдента с (n -2) степенями свободы;
, имеют распределение Стьюдента с (n -2) степенями свободы;
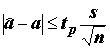
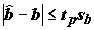 ,(5.79)
,(5.79)где
tp – квантиль уровня (1 + P) / 2 распределения Cтьюдента с n - 2 степенями свободы, P – доверительная вероятность.Статистическая значимость уравнения линейной регрессии проверяется отклонением нулевой гипотезы о равенстве нулю коэффициента
b, отражающего угол наклона линии тренда. Гипотеза Но: b = 0 соответствует предположению, что изменчивость y обусловлена только случайными составляющими e i . Существует два эквивалентных способа проверки нулевой гипотезы: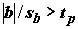 , то гипотезу Н следует отклонить; уровень значимости при этом a
= 1 -
P;
, то гипотезу Н следует отклонить; уровень значимости при этом a
= 1 -
P;
F = 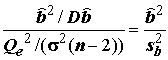 ;(5.80)
;(5.80)
если
F > F1- a , где F1- a – квантиль уровня (1 - a ) распределения F(1, n-2), то гипотеза Н отклоняется с уровнем значимости a .
Тестирование правильности спецификации регрессионной модели
Необходимость изменить функциональную форму регрессии возникает, если неверна одна из следующих гипотез, выполнение которых требуется для того, чтобы метод наименьших квадратов в применении к регрессионной модели (5.67) давал хорошие результаты.
1. Ошибки имеют нулевое математическое ожидание, или, что то же самое, математическое ожидание зависимой переменной является линейной комбинацией регрессоров:
E (e i) = 0, E (Y i) = b X i.
2. Ошибки гомоскедастичны, т. е. имеют одинаковую дисперсию для всех наблюдений:
V (e
i2) = E (e i2) = s 2.Если перечисленные предположения неверны, то в ошибке осталась детерминированная (неслучайная) составляющая, которая может быть функцией входящих в модель регрессоров. Это означает, что имеет место неверная спецификация функциональной формы. Заметить ошибку спецификации можно на глаз с помощью графиков остатков. Формальный тест на “нормальность остатков” можно провести с помощью вспомогательной регрессии квадратов остатков по “подозрительным” переменным, значимость которой можно оценить по обычной методике, описанной выше. Похожим образом обнаруживается и гетероскедастичность (отсутствие гомоскедастичности), которая проявляется в том, что разброс остатков меняется в зависимости от значения переменной
X. Тест на гетероскедастичность может быть выполнен с помощью LM-статистики, которая равна половине объясненной суммы квадратов из регрессии по константе и X и распределена асимптотически как c 2 [Цыплаков, URL].При проверке правильности спецификации нулевая гипотеза всегда состоит в том, что модель специфицирована корректно, а альтернативная гипотеза - в том, что имеется ошибка соответствующей спецификации. Если статистика незначима (например, уровень значимости больше 5%), то следует принять гипотезу о правильности спецификации.
Обычно умеренные ошибки в спецификации не приводят к серьезным последствиям, таким как несостоятельность оценок. При отклонениях остатков от нормальности МНК может давать не очень точные оценки, а вычисляемые
t- и F-статистики не распределены в конечных выборках точно как t и F (хотя эти статистики остаются состоятельными, то есть их использование оправдано асимптотической теорией).Учет нелинейности связи факторов в моделях линейной регрессии
В разделе 2.6 мы подробно останавливались на необходимости учета объективной нелинейности реального мира и проблемах нахождения модели оптимальной сложности.
Лучшим инструментом оценки качества приближения экспериментальных точек к расчетной кривой является человеческий глаз. Для проверки гипотезы о линейном характере связи Y и Х более педантичные исследователи, например, делят область рассеяния точек наблюдения на четыре равных квадранта и подсчитывают количество экспериментальных точек, попавших в каждый квадрант: для линейной зависимости характерен четкий дисбаланс между частотами по обеим диагоналям. Более строгие методы проверки гипотезы о линейности связаны с анализом выборочных корреляционных отношений и представлены в главе 6.
Перечислим в таблице 5.15 основные виды функциональных форм регрессионной модели с примерами нелинейных зависимостей. Более сложные нелинейные модели связаны с использованием сплайнов, алгоритмов МГУА и др. [Розенберг с соавт., 1994].
Таблица 5.1
5Функциональные формы регрессионных моделей с примерами нелинейных зависимостей
|
Функциональная форма |
Примеры |
|
Полиномиальная |
Y = а0 + а1 X + а2 X2 + а3 X3 + …+ аkXk |
|
Гиперболическая |
Y = а0 / (а1 + X) |
|
Семейство обращенных полиномиальных функций |
Y = a / (а0 + а1 X + а2 X2 + …+ akXk);Y = X / (а0 + а1 X + а2 X2 + …+ akXk); Y = (b0 + b1 X + b2 X2 + …+ blXl) / (а0 + а1 X + а2 X2 + …+ akXk); |
|
Логлинейная |
lnY = а0 +а1 lnX |
|
Обобщенная логарифмическая |
Y = а0 + а1 lnX + а2 X |
|
Степенная |
Y = а0 +а1 Xc, где с – любое вещественное число |
|
Экспоненциальная |
Y = a eb X |
|
Функция Гомперца |
lnY = b - a e – X |
|
Логистическая |
Y = с /(1 + e(a + b X)) |
|
Экспоненциально-степенная |
Y = a e b X Xc |
|
Обращенная экспоненциальная |
Y = 1/(a + b* e – X) |
|
Показательная |
Y = a*bХ |
|
Тригонометрическая |
Y = b о + b 1 sinw x + b 2 cos w x |
Слово “линейный” в названии "линейный регрессионный анализ" указывает на линейность модели относительно параметров
aj, но не факторов xj . Это означает, что мы можем проделать с выборкой Х любые функциональные преобразования и включить преобразованные факторы в линейное уравнение.Линеаризации, например, могут легко подвергаться полиномы
yi
= aо + a1 xi + a2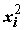 + ...+ ak
+ ...+ ak 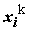 + e
i ,(5.81)
+ e
i ,(5.81)
поскольку для имеющейся обучающей выборки (
xi, yi), i = 1, ..., n, можно записать матричную форму:Y
= X A + e , где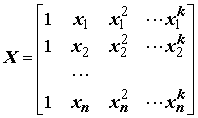 .
.
В этом и в ряде других случаев расчет коэффициентов
aj можно свести к стандартной задаче линейной регрессии, и потому все формулы МНК оказываются справедливыми и для нелинейной формы аппроксимирующего уравнения.Выбор между альтернативными функциональными формами обычно осуществляют на основе некоторого критерия, оценивающего точность подбора, в качестве которого обычно используется коэффициент детерминации (
R2). Чтобы учитывать при селекции простоту модели, делают поправку на количество регрессоров k. Это дает коэффициент детерминации, скорректированный на количество степеней свободы: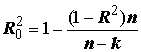 . (5.82)
. (5.82)
Оценки метода наименьших квадратов являются одновременно и оценками метода максимального правдоподобия [Дрейпер, Смит, 1986]. Поэтому предлагается сравнивать модели на основе максимума логарифмической функции максимального правдоподобия (
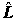 ). Если учесть при этом количество наблюдений (n) и ввести "штраф" за большое количество регрессоров (k), то получится информационный критерий Акаике (Akaike information criterion):
). Если учесть при этом количество наблюдений (n) и ввести "штраф" за большое количество регрессоров (k), то получится информационный критерий Акаике (Akaike information criterion):
AIC = – 2/n (– k) . (5.83)
Чем меньше AIC, тем лучшей считается модель.
В некоторых случаях, приведенных в таблице 5.15, нельзя свести нелинейную функцию
f(Х) к линейной форме. B такой ситуации оценки наименьших квадратов параметров a и b приходится получать с помощью итерационных вычислительных процедур, осуществляющих последовательное приближение к минимуму суммы квадратов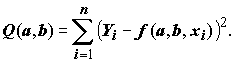 (5.84)
(5.84)
Выполнить это приближение можно стандартными методами нелинейной оптимизации – методами Ньютона-Рафсона, Нелдера-Мидда и проч. [Банди, 1988; Гайдышев, 2001], включаемыми в большинство пакетов статистических программ.
В ряде случаев линеаризация оказывается возможной, но методически неверным является "обратное" преобразование линеаризированных уравнений. Например, в разделе 4.8 отмечалось, что для расчета большинства компонентов материального баланса отдельной особи канонизировано употребление параболических (степенных) зависимостей:
Y
= a Xk ,(5.85)
где
X и Y – произвольные биоэнергетические или аллометрические показатели, a и k – коэффициенты уравнения регрессии. Подавляющее большинство ученых-экологов (например, [Тодераш, 1984; Балушкина, 1987; Голубков, 2000]) в своих работах рекомендуют применять не вполне корректную схему расчета коэффициентов a и k путем нахождения параметров линейной регрессии видаlg Y = lg a + k lg X .(5.86)
Определенная методологическая неточность присутствует и у А.А. Умнова [1976], когда он при стандартных допущениях регрессионного анализа предлагает найти в выражении
Y = aXk значения коэффициентов a и k, обеспечивающие минимальность квадратичной формы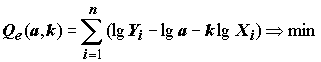 .(5.87)
.(5.87)
Нетрудно видеть из (5.84), что аксиоматика метода наименьших квадратов требует нахождения экстремума совсем иного функционала:
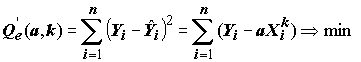 .(5.88)
.(5.88)
Согласно известным положениям регрессионного анализа [Дрейпер, Смит, 1986] нелинейная функция может быть приведена к линейной форме (т.е. линеаризирована) только в том случае, если ошибка обоих уравнений регрессии остается аддитивной, то есть зависимая переменная является суммой своего математического ожидания и ошибки. Пусть, например, исследователь из своих теоретических соображений желает получить степенную зависимость модели наблюдений
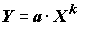 . Выполнив логарифмирование данных и применив МНК, он получает линейную в логарифмах зависимость
. Выполнив логарифмирование данных и применив МНК, он получает линейную в логарифмах зависимость 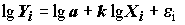 . Однако, при обратном преобразовании логлинейного уравнения (5.86) в уравнение (5.85), будет имеет место мультипликативное вхождение ошибок
. Однако, при обратном преобразовании логлинейного уравнения (5.86) в уравнение (5.85), будет имеет место мультипликативное вхождение ошибок 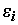 в нелинейное уравнение отклика:
в нелинейное уравнение отклика: 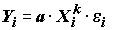 . Последняя форма записи далеко не идентична стандартной регрессионной модели с аддитивными ошибками
. Последняя форма записи далеко не идентична стандартной регрессионной модели с аддитивными ошибками 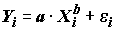 . Иными словами, выражения (5.85) и (5.86) представляют собой два принципиально разных уравнения регрессии, поэтому использование для модели МНК-оценок (a, k) из линеаризированного уравнения , неизбежно приведет к заведомо искаженным результатам.
. Иными словами, выражения (5.85) и (5.86) представляют собой два принципиально разных уравнения регрессии, поэтому использование для модели МНК-оценок (a, k) из линеаризированного уравнения , неизбежно приведет к заведомо искаженным результатам.
Из такой ситуации существует два возможных выхода:
Результаты расчетов
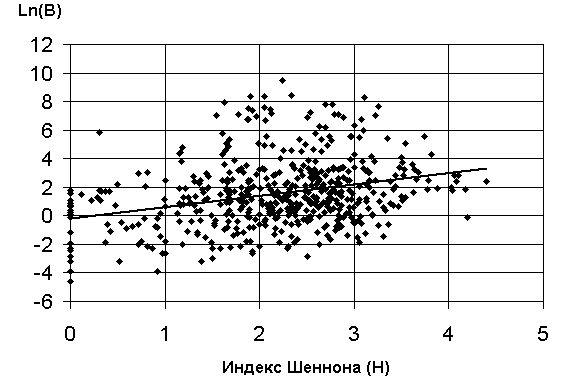
Мем № 30: “По отношению к сообществам донных животных значения индекса Шеннона тесно коррелируют со значениями биотического индекса Вудивисса, отражающего степень загрязнения вод. Существенно, что между разнообразием системы и биомассой организмов существует вполне определенная обратная зависимость, которая по отношению к планктонным сообществам была количественно выражена А.М. Гиляровым, и подтверждена мною на основании данных по нескольким латгальским озерам” А.Ф. Алимов [1990].
Рассмотрим, насколько этот тезис подтверждается для зообентоса рек средней полосы России. Сформируем выборку из 533 сопряженных наблюдений, куда включим следующие показатели зообентоса: индекс Шеннона (Н), биотический индекс Вудивисса (
V), число видов (S), суммарную численность (NS) и биомассу (ВS) всех видов в пробе, а также обилие отдельных таксономических групп – хирономид (Bchi), олигохет (Nоli, Воli) и хищников-хватателей (Nh).Для оценки связи этих показателей выполним расчет подмножества регрессионных уравнений, основные параметры которых представлены в табл. 5.16. По каждой диагностической статистике приведены уровни значимости использованных критериев. Если Р-значение, соответствующее величине статистики, больше 5%, то нет оснований отвергать исходную нулевую гипотезу: об отсутствии влияния фактора, равенстве 0 коэффициента угла наклона
b, отличии распределения остатков от нормального или влиянии фактора на остатки соответственно.Таблица 5.16
Регрессионные зависимости между отдельными гидробиологическими показателями (обозначения по тексту)
|
Уравнение регрессии |
Коэффи -циент де-термина-ции R2 , % |
Значи -мость по F-критерию Фишера |
Гипотеза b=0 по t-критерию Стьюдента |
Распределение остатков |
|
|
Нормаль -ность по критерию c 2 |
Гетероске -дастичность по крите-рию c 2 |
||||
|
1. H = 2.15 + 4.6 10-5 Bs |
-0.048 |
0.75 |
0.866 |
22.6 |
3.21 |
|
2. H = 1.98 + 0.112 ln(Bs) |
8.69 |
50.4 |
7.09 |
12.0 |
6.99 |
|
3. ln(Bs) = -0.159 + 0.79 H |
8.69 |
50.4 |
7.09 |
58.0 |
0.317 |
|
4. ln(S) = 1.935 + |
16.89 |
106.48 |
10.31 |
54.0 |
6.56 |
|
5. H/ln(S) = 0.873 + |
1.768 |
10.34 |
3.216 |
177.68 |
38.87 |
|
6. H = 2.319 + 0.09 ln(BChi) |
4.35 |
22.49 |
4.74 |
10.88 |
4.197 |
|
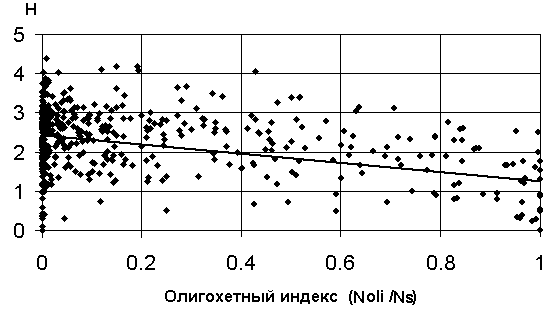
7. H = 2.19 – 0.019 ln(BOli) |
~ 0 |
0.926 |
0.96 |
19.58 |
0.0053 |
|
8. H = 2.415 – |
16.53 |
103.8 |
-10.19 |
14.96 |
0.0587 |
|
9. H = 1.46 + |
24.65 |
170.8 |
13.07 |
20.3 |
1.67 |
|
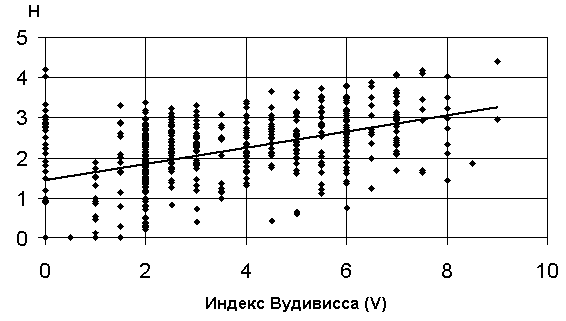
10. H = 1.43 + 0.203 V |
22.66 |
153.0 |
12.37 |
4.45 |
36.15 |
Примечание
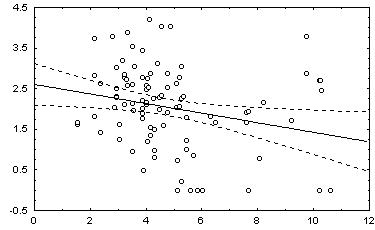
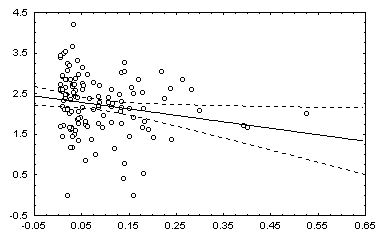
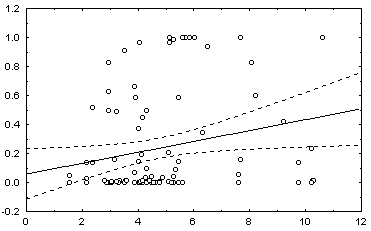
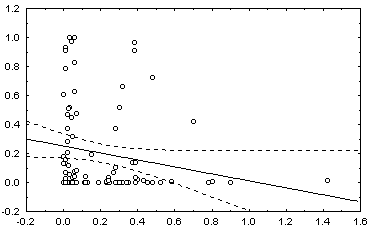
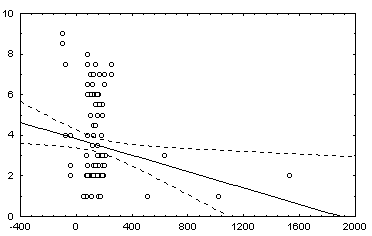
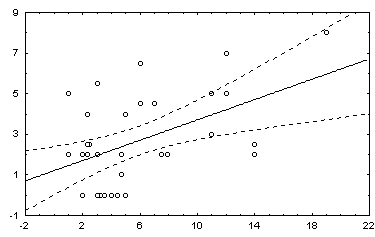
: в квадратных скобках приведены Р-значения для соответствующей статистики.Некоторые графики полученных зависимостей и гистограмм распределений показаны на рис. 5.12.
|
а) график зависимости 3 : ln( Bs)=a + bН |
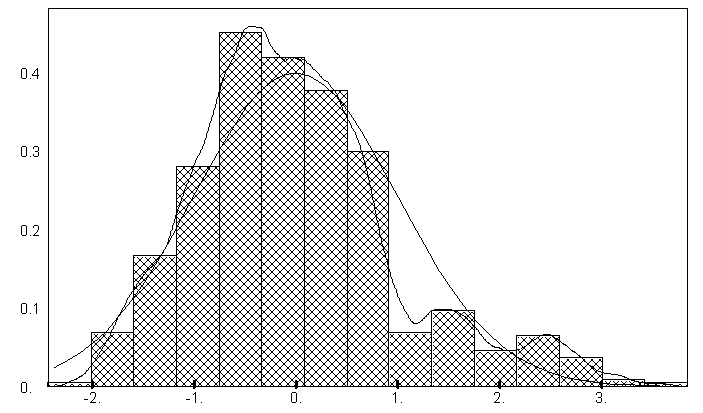
б) гистограмма остатков зависимости 3. |
|
в) график зависимости 8: H = a + b (Noli/Ns) |
г) график зависимости 10: H = a + b V |
Рис. 5.12. Графики зависимостей между индексом Шеннона и некоторыми гидробиологическими показателями (уравнения приведены в таб. 5.15)
По результатам расчетов можно сделать следующие выводы:
Мем № 31
: “Для практического использования при определении качества воды предлагаются следующие методы: система сапробности; биотический индекс Вудивисса в нашей модификации. Для углубленного изучения экологических условий водного объекта можно использовать индекс видового разнообразия Шеннона-Уивера” В.А. Яковлев [1988].
Рассмотрим, подтверждаются ли распространенные утверждения о закономерном влиянии факторов гидрохимического загрязнения на такие показатели как индекс Шеннона Н, олигохетный индекс Гуднайта-Уитлея и Пареле
P и биотический индекс Вудивисса V, полученные для малых рек Самарской области. Рассчитанные уравнения линейной регрессии зависимости этих индексов от традиционных гидрохимических показателей представлены в табл. 5.17 и на рис. 5.13.Таблица 5.17
Регрессионные зависимости гидробиологических показателей (индекс Шеннона Н, олигохетный индекс Гуднайта-Уитлея и Пареле Р и биотический индекс Вудивисса
V) от гидрохимических факторов|
Наименование фактора, объем выборки и ее размах ( min-max) |
Уравнения регрессии (С – гидрохимический фактор из столбца 1) |
Коэффициент детерминации R2, % |
F -критерий Фишера и его р-значение |
|
pH в придонном слое, 331 изм., 5.3 ¸ 9.8 |
Н = 2.18 + 0.001*С |
0.303 |
10-4 [0.99] |
|
P = 0.464 - 0.031*C |
0.046 |
0.845 [0.358] |
|
|
V = 6.68 - 0.351*C |
0.368 |
2.22 [0.137] |
|
|
Растворенный кислород (на дне), 306 изм., 6.5 ¸ 184 |
Н = 2.49 - 0.002*C |
0.065 |
0.799 [0.37] |
|
P = 0.0785 + 0.0012*C |
0.467 |
2.43 [0.12] |
|
|
V = 4.35 - 0.005*C |
0.062 |
0.81 [0.36] |
|
|
Редокс-потенциал (Еh) в поверхностном слое, 139 изм., 100¸ 1530 мВ |
Н = 2.403 - 0.001*C |
4.78 |
7.93 [0.0056] |
|
P = 0.254 + 0.0003*C |
2.54 |
4.6 [0.034] |
|
|
V = 3.819 - 0.25*C |
3.11 |
5.43 [0.02] |
|
|
Фосфор минеральный, 125 изм., 0.005 ¸ 0.525 мг/л |
Н = 2.363 - 1.59*C |
2.99 |
4.82 [0.029] |
|
P = 0.203 + 0.598*C |
2.02 |
3.568 [0.061] |
|
|
V = 3.497 - 1.041*C |
0.537 |
0.336 [0.56] |
|
|
Аммонийный азот, 90 изм., 0.001 ¸ 1.42 мг/л |
Н = 2.196 - 0.172*C |
0.856 |
0.24 [0.62] |
|
P = 0.251 - 0.24*C |
2.85 |
3.61 [0.06] |
|
|
V = 3.7 - 0.8*C |
0.036 |
0.967 [0.32] |
|
|
БПК 5,99 изм., 1.55 ¸ 10.59, мг/л |
Н = 2.6 - 0.118*C |
4.61 |
5.74 [0.018] |
|
P = 0.0575 + 0.0375*C |
3.87 |
4.95 [0.028] |
|
|
V = 3.89 - 0.8*C |
2.629 |
3.64 [0.059] |
|
|
Железо, 71 изм., 0.001 ¸ 2.6 мг/л |
Н = 2.35 - 0.477*C |
2.99 |
3.16 [0.08] |
|
P = 0.2 + 0.12*C |
0.512 |
1.36 [0.24] |
|
|
V = 3.89 - 0.8*C |
1.38 |
0.045 [0.83] |
|
|
Медь, 33 изм., 1 ¸ 19 мкг/л |
Н = 2.05 + 0.0323*C |
1.29 |
0.589 [0.44] |
|
O = 0.367 - 0.013*C |
0.497 |
0.84 [0.36] |
|
|
V = 1.202 + 0.25*C |
21.7 |
9.9 [0.0036] |
Примечание
: жирным шрифтом F-критерия выделены статистически значимые уравнения регрессии.|
а) индекс Шеннона от БПК5 |
б) индекс Шеннона от фосфора минерального |
|
в) индекс Пареле от БПК5 |
г) индекс Пареле от азота аммонийного |
|
д) индекс Вудивисса от редокс-потенциала |
е) индекс Вудивисса от концентрации меди |
Рис. 5.13. Графики зависимостей гидробиологических индексов по оси ординат от гидрохимических показателей (уравнения приведены в таб. 5.17)
Выполненные расчеты показывают существенно более слабую корреляционную связь гидробиологических индексов с уровнем загрязнения, чем это обычно декларируется. Низкую статистическую значимость уравнений регрессии следует объяснить, видимо, двумя причинами: объективной и технологической.
Объективная
составляющая заключается в том, что обобщенные индексы H, P и V работоспособны, по нашему мнению, лишь в случае ощутимых различий в степени антропогенного воздействия на сравниваемые экосистемы. В изучаемом регионе уровень химического загрязнения воды относительно однороден, за редкими исключениями (устье р. Чапаевка), которые мало влияют на общую статистическую оценку. Поэтому вариабельность общих индексов определяется в значительной мере природно-географическими факторами и особенностями биотопов, нежели концентрациями химических ингредиентов. Влияние токсического загрязнения на экологию гидробионтов следует оценивать не в "общестатистическом болоте" данных, а по совокупности специально подобранных примеров, полярно разнесенных на шкале "патология – норма", и с учетом всех структурных изменений видовых комплексов биоценозов (о чем пойдет речь в последующих главах).Статистическая надежность уравнений регрессии зависит и от технологии работы с данными: тщательности подбора аппроксимирующей функции и выполнения исходных предпосылок анализа (нормальности и независимости остатков). Приведем несколько комментариев этому тезису:
Однако никакая методологическая тщательность обработки не гарантирует от артефактов в виде распространенного феномена "ложной" корреляции. Например, мы затрудняемся дать какое-либо осмысленное объяснение чрезвычайно достоверной прямо пропорциональной (!) связи индекса Вудивисса и концентрации ионов меди (см. фиг. “е” рис. 5.13).
Мем № 32
: “Несмотря на большое число исследований, рассматривающих зависимость скорости обмена от индивидуального веса, не было встречено случаев, показывающих необходимость или желательность применения для той же цели других функций. Впрочем, сделана попытка опровергнуть какое-то "реальное существование" (?) степенной зависимости R от W на основании того, что в отдельных случаях…данные аппроксимируются не только прямой… Нельзя принимать всерьез эти предельно наивные высказывания” Г.Г. Винберг [1976].В математической части была показана недостаточная обоснованность методов линеаризации при оценке параметров степенного уравнения регрессии. Оценим, насколько практически отличаются между собой коэффициенты степенного (5.85) и логлинейного (5.88) уравнений, оптимальные относительно сумм квадратов невязок (5.86) и (5.87), соответственно.
Воспользуемся для этого выборкой [Умнов, 1976], связывающей величину энергетического обмена с массой тела пескожила Arenicola marina. А.А. Умновым для этой серии наблюдений после логарифмирования было рассчитано линейное уравнение регрессии
log Y = 1.804 + 0.672X .
Поскольку 26 лет назад методы нелинейного программирования были своего рода "вычислительной экзотикой", автор рекомендует использовать найденные коэффициенты для степенной модели, которая после обратного преобразования приобретает вид
Y
= 63.75X 0.672 . (5.89)
В настоящее время любой исследователь может легко вычислить истинные МНК-оценки нелинейной функции (5.84) и получить для данных, представленных в табл. 5.18, оптимальное степенное уравнение энергетического обмена пескожила
Y
= 53.36X 0.785 .(5.90)
Если принять во внимание, что по литературным данным (см. раздел 4.8) для различных групп зообентоса показатель степенного уравнения
k варьируется от 0.75 до 0.895, то отличия уравнений (5.89) и (5.90) можно признать существенными. Достаточно значительным (на 17%) имело место и снижение остаточной суммы квадратов Qe.Из графика на рис. 5.14 легко увидеть, что уравнение (5.89), совпадая с (5.90) в средней части, плохо учитывает расположение экспериментальных точек на "хвостах" кривой.

Рис. 5.14. Графики аппроксимирующих функций (номера по тексту) потребления кислорода от веса тела пескожила
Мем, предваряющий этот блок расчетов, относится к любопытной категории – "указующим мемам". При этом Г.Г. Винберг [1976] признает: “нет оснований считать, что когда данные могут быть переданы степенной функцией, это указывает на некоторый определенный механизм явления”, т.е. на самом деле никакой биофизической закономерности уравнение (5.85) не отражает. Это означает, что с равным правом можно предложить целый ряд иных математических формул, которые будут описывать те же экспериментальные данные с большей степенью адекватности.
Мы бы сочли проявлением собственной "наивности", если бы лишили себя возможности проверить, нет ли иной формы зависимости, которая бы лучше аппроксимировала данные по энергетическому обмену пескожила, чем канонизированное степенное уравнение. Наши поиски не были слишком упорными – первые же тестируемые полиномиальные уравнения 2-й и 3-й степени оказались существенно более адекватными по отношению к экспериментальным данным (коэффициент детерминации в табл. 5.18 рассчитан по формуле (5.82) и учитывает количество регрессоров):
Y = 0.5298X 2 + 15.441X + 93.093 ; (5.91)
Y = -0.2492X 3 + 8.0469X 2 - 46.844X + 229.9. (5.92)
Таблица 5.18
Расчет энергетического обмена в зависимости от индивидуального веса пескожила по различным эмпирическим уравнениям (цифровые обозначения по тексту)
|
Индивидуальный вес, г/экз |
Энергетический обмен, мм 3 О2/час экз |
||||
|
Получены в эксперименте |
Рассчитаны по уравнениям регрессии |
||||
|
(5.89) |
(5.90) |
(5.91) |
(5.92) |
||
|
2.37 |
105.33 |
113.89 |
105.03 |
132.66 |
160.76 |
|
2.82 |
192.63 |
128.01 |
120.38 |
140.85 |
156.20 |
|
3.12 |
177.13 |
137.02 |
130.31 |
146.43 |
154.51 |
|
3.21 |
221.84 |
139.67 |
133.26 |
148.12 |
154.20 |
|
3.22 |
95.9 |
139.96 |
133.58 |
148.31 |
154.18 |
|
3.24 |
107 |
140.54 |
134.23 |
148.68 |
154.12 |
|
3.38 |
202.5 |
144.60 |
138.76 |
151.34 |
153.88 |
|
3.6 |
105.4 |
150.86 |
145.80 |
155.55 |
153.92 |
|
4 |
182.38 |
161.94 |
158.37 |
163.33 |
155.33 |
|
4.65 |
198.2 |
179.19 |
178.23 |
176.35 |
161.01 |
|
4.91 |
167.45 |
185.87 |
186.00 |
181.68 |
164.39 |
|
4.93 |
195 |
186.38 |
186.60 |
182.09 |
164.68 |
|
5.72 |
108.8 |
205.97 |
209.68 |
198.75 |
178.60 |
|
5.95 |
233.13 |
211.51 |
216.27 |
203.72 |
183.57 |
|
7.65 |
190.17 |
250.45 |
263.41 |
242.22 |
230.90 |
|
8.26 |
254.35 |
263.71 |
279.76 |
256.78 |
251.55 |
|
8.5 |
191.88 |
268.84 |
286.12 |
262.62 |
260.07 |
|
10.62 |
416.87 |
312.26 |
340.75 |
316.83 |
341.50 |
|
14.6 |
472.75 |
386.79 |
437.42 |
431.46 |
485.71 |
|
18.76 |
538.34 |
457.82 |
532.52 |
569.22 |
537.81 |
|
Остаточная сумма квадратов отклонений Qe |
66656 |
56935 |
49973 |
42359 |
|
|
Скорректированный коэффициент детерминации R2o, % |
73.7 |
77.6 |
79.1 |
81.2 |
|
Примечание
: жирным шрифтом выделены значения с минимальной ошибкой относительно экспериментальных данных
Согласно принципу множественности моделей В.В. Налимова [1971], список подобных эмпирических зависимостей может быть существенно продолжен.
Окончательная селекция лучших из них целесообразна, вероятно, исходя из совокупных соображений "ошибка регрессии" + "удобство использования". Если под фактором "удобства" понимать визуальное сравнение коэффициентов, оцененных для разных таксономических групп животных, то выбор степенной зависимости в качестве единого стандарта интерпретации и обобщения следует признать обоснованным.
Однако, в случае разработки ряда имитационных моделей материально-энергетического баланса экосистем [Меншуткин, 1971], применение, например, полиномиальных уравнений значительно предпочтительней, поскольку схема расчета их коэффициентов методом линеаризации является статистически корректной и не требует громоздких итеративных алгоритмов нелинейной оптимизации.
| Дальше
|
Назад |
Начало |
Конец |
Список
|