| Дальше
|
Назад |
Начало |
Конец |
Список
|
6.3. Интервальные и бинарные структуры
Мем № 34
Формулировка задачи
Пусть имеется ряд наблюдений показателя Y = (y1, ..., yn), принимающий значения на отрезке [a, b]. Необходимо найти такое разбиение d шкалы Y на k интервалов, при котором наилучшим образом используются дифференциально-диагностические возможности признака Y для поиска закономерности его связи с заданным фактором X.
При градиентном анализе или расчете корреляционных отношений возникают нетривиальные вопросы: каков механизм выделения интервалов и на сколько поддиапазонов следует разбивать область варьирования переменных. Нетрудно заметить, что при выделении только одного интервала (
k = 1) корреляционное отношение h 2y|x = 0. Если же выбрать разбиение на N интервалов таким образом, чтобы в один поддиапазон попало бы ровно по одной точке, то на той же выборке данных h 2y|x становится уже равным 1. Конечно, оба этих разбиения противоречат, если не букве полного корреляционного анализа, то здравому смыслу, однако показывают, что величина корреляционного отношения сильно зависит не только от характера распределения зависимой переменной вдоль оси фактора, но и в значительной мере от способа группировки.При количественном выражении взаимной корреляции признаков выбор числа групп и границ интервалов – центральная проблема, так как этим обуславливается объективность характеристик связи. Субъективным критерием правильности выбора числа классов
k является верная передача типа распределения эмпирических частот данной совокупностью. Если выбрано слишком мало классов, можно потерять характерную картину связи Y с X. При слишком подробном делении на классы можно стушевать реальную картину распределения частот случайными отклонениями. С точки зрения последователей градиентного анализа, акцент делается на "удобство интерпретации результатов" и предлагается всю область варьирования фактора разбивать на пять равных частей [Миркин, Наумова, 1983].“Если имеется система долей, например, распределение количественного показателя с относительными частотами (в долях), то общая энтропия вариационного ряда равна сумме частных энтропий по классам распределения” [Плохинский, 1982]. Таким образом, задачу выбора границ интервалов можно определить как, в некотором смысле, минимизацию совокупной энтропии, получающейся в результате группировки.
Дополнительный смысл постановка этой задачи приобретает, когда для нахождения разбиения на поддиапазоны d некоторой локальной выборки используются свойства распределения другой выборки, сопряженной с анализируемой (т.е. ищется минимум энтропии, основанной на условных вероятностях многомерного распределения нескольких показателей). В этом случае деление на интервалы учитывает реально существующие статистические зависимости факторов и наилучшим образом использует дифференциально-диагностические возможности признака
Y для поиска закономерностей его связи с другим признаком X.Рекомендуемая литература: [Айвазян с соавт., 1983; Алгоритмы и программы.., 1984; Генкин, 1999
].Математический лист
Методы деления количественной шкалы на интервалы
К числу эмпирических способов вычисления числа классов k для выборок умеренных размеров m можно отнести правило Стургеса (Sturgess) [Зайцев, 1984]:
K
= 3.32 lg(m) +1 = 1.44 ln (m) + 1 , (6.32)
(6.32)
т.е. от 5 до 9 на наших примерах. Другие авторы [Хан, Шапиро, 1969; Лакин, 1990] считают, что число классов
k должно быть 12 ± 3, т.е. разброс мнений весьма велик.Поскольку нет единых теоретических оснований для оценки качества группировки, то принципиально допустим любой формальный алгоритм, удовлетворяющий определенным требованиям. Можно выделить следующие основные стратегии разбиения на градации:
Разработаны и практически применяются более строгие способы различных аппроксимаций частотных распределений: оценки Парзена-Надарая [Горелик, Скрипкин, 1984; Фомин, Тарловский, 1986], сглаживание гистограмм [Ивашко, Кузнецов, 1989] и другие оптимизационные стратегии
, когда граничные значения выбираются из условия экстремума некоторого критерия. Такие критерии оптимизации разбиения могут быть двух типов:Примером оптимального решения с использованием внутреннего критерия является минимизация функционала [Браверман, Мучник, 1983]:
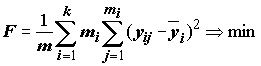 , (6.33)
, (6.33)
где обозначения те же, что и при расчете корреляционных отношений (6.15)-(6.18).
Все методы, использующие внутренние критерии, предполагают локальный анализ закономерности частотного распределения признака раздельно для каждой выборки
X или Y без учета их взаимной статистической обусловленности, что с точки зрения теории информации нельзя считать вполне адекватным.
Использование информационных мер для оптимизации разбиения
Предположим, что каждая величина yi , i = 1,2,…,m, принимающая значения на отрезке [a, b], принадлежит к одному из n классов измерений D1, D2, …, Dn (это могут быть, например, водоемы, в которых проводились измерения, сезонные признаки или классы качества вод).
Введем разбиение d диапазона [a, b] на заранее заданное количество интервалов k, границы которых заранее не определены. Обозначим через pj(y|Ds) частоту попадания значения показателя Y из подмножества {y}Ds в j-й диапазон.
Тогда для двух классов Ds и Dl в качестве наилучшего разбиения диапазона [a, b] выбирается такое, которое максимизирует значение меры дивергенции, введенной С. Кульбаком [1967]:
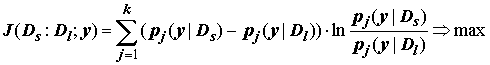 (6.34)
(6.34)
В общем случае
m классов максимизируется величина: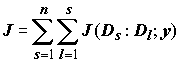 . (6.35)
. (6.35)
Получаемое таким образом разбиение вместе с вероятностями появления значений признака в соответствующих интервалах
pj(y|Ds) называется интервальной структурой [Генкин, 1999].Для двух признаков
Y1 и Y2 , зная разбиения d 1 и d 2 для каждого из них, естественным образом строятся оценки рl(Y1,Y2|Ds) – частоты попадания пары значений анализируемых признаков в прямоугольники со сторонами, равными интервалам соответствующих разбиений. Множество прямоугольников, вместе с оценками вероятностей попадания в них пары значений признаков рl(Y1,Y2|Ds), называется бинарной (матричной) структурой.Таким образом, описываемый методологический принцип анализа различий заключается в том, что сравнению подвергаются не сами наблюдения, а их нормированные частоты попадания в ячейки интервальных или бинарных структур.
Поскольку интервальные и бинарные структуры мало чувствительны к систематическим (а частично и к случайным) ошибкам наблюдений, эти методы нашли широкое применение при обработке клинико-лабораторных признаков. Большой вклад в развитие интервальных методов при решении медико-биологических задач внесли Е.В. Гублер и А.А.
Генкин, воплотившие и развившие эти информационные структуры в среде Оболочки Медицинских Интеллектуальных систем [Генкин, 1999].Рассмотрим принципы формирования интервальных структур и решающих правил при сравнении двух выборок. Дивергенция Кульбака, которая имеет смысл средней информационной меры различия двух эмпирических распределений, для этого случая может быть вычислена по формуле
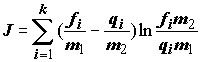 , (6.36)
, (6.36)
где
fi, qi – частоты попадания в i-й интервал примеров сравниваемых выборок, m1, m2 – численность обеих выборок. C.Кульбаком [1967] было показано, что статистика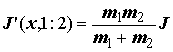 ,(6.37)
,(6.37)
основанная на дивергенции
J, имеет распределение c 2 с (k - 1, 1) степенями свободы, что позволяет использовать ее для проверки нулевых гипотез. Критерий различия двух выборок J’(x, 1:2), использующий информационную меру Кульбака, предлагается [Генкин, 1999] назвать J-критерием, а соответствующий ему уровень значимости обозначать PJ. А.А. Генкиным приводятся формулы, распространяющие использование меры Кульбака на случай сравнения n выборок, однако практических примеров техники такого анализа нам найти не удалось.В.Н. Вапником с соавторами [Алгоритмы и программы.., 1984] представлен более общий алгоритм нахождения наилучшего разбиения, основанный на минимизации шенноновской энтропии и определяющий как границы диапазонов, так и оптимальное число градаций
k.Результаты расчетов
Рассмотрим выборку значений общей численности хищников-хватателей Nh, причем каждой гидробиологической пробе поставлен в соответствие класс качества воды по шестибальной шкале [ГОСТ 17.1.3.07–82; Драчев, 1964]. Найденные границы интервалов разбиения на 5 интервалов с использованием различных стратегий и критериев представлены в табл. 6.7.
Таблица 6.7
Границы интервалов и количество наблюдений в каждой градации при различных стратегиях деления на 5 диапазонов выборки из численностей хищников-хватателей
|
Равная ширина интервалов |
В долях среднеквадратического отклонения |
Минимизация функционала Бравермана –Мучника (6.33) |
Равное количество значений без учета повторов |
Равномерная "заселенность" интервалов |
|||||
|
Градации |
Кол-во |
Градации |
Кол-во |
Градации |
Кол-во |
Градации |
Кол-во |
Градации |
Кол-во |
|
< 6000 |
537 |
от 0 до M |
433 |
< 575 |
467 |
< 104 |
280 |
= 0 |
141 |
|
< 12000 |
1 |
< (M + s ) |
63 |
< 2640 |
63 |
< 260 |
97 |
< 55 |
99 |
|
< 18000 |
0 |
< (M +2s ) |
17 |
< 5900 |
7 |
< 560 |
81 |
< 160 |
104 |
|
< 24000 |
1 |
< (M +3s ) |
8 |
< 18278 |
2 |
< 1280 |
53 |
< 480 |
104 |
|
< 30000 |
1 |
> (M +3s ) |
19 |
< 27820 |
1 |
< 27820 |
29 |
< 27820 |
92 |
Как видно из представленных результатов, выделение границ интервалов с использованием выборок, типичных для гидробиологических данных, представляет собой далеко не тривиальную проблему. Использование традиционных стратегий равной ширины или долей сигмы, а также большинства формальных критериев, приводит к существенно асимметричному разбиению, которое не может продуктивно использоваться в последующем анализе.
Разделим все множество наблюдений из численностей хищников-хвателей
Nh на две выборки: измерения на "чистых" станциях с классом качества вод 3 и менее и измерения на "грязных" станциях. Традиционное сравнение средних с использованием t-критерия Стьюдента не выявляет статистических различий между этими выборками (р = 0.45). Осуществим такое разбиение всей области варьирования значений численности на 5 интервалов, которое обеспечивало бы максимальную расщепляющую способность обоих подмножеств, т.е. наибольшую суммарную разность частот (пересчитанную в доли J) в ячейках таблицы сопряженности. Определение оптимального вектора границ диапазонов осуществлялось нами по алгоритму случайного поиска до тех пор, пока значение информационной меры Кульбака J не перестает возрастать (см. табл. 6.8).В первом столбце табл. 6.8 – интервалы, найденные компьютером, наилучшим образом подчеркивающие различие вариабельности численности хищников в рассматриваемых группах. Во втором и третьем столбцах – частота (в скобках – относительная частота) наблюдений численности из соответствующих интервалов. Справа приводятся средние арифметические, не различающиеся по
t-критерию, тогда как мера Кульбака J' свидетельствует о значимом (pJ < 0.00001) изменении численности Nh в зависимости от уровня гидрохимического загрязнения на станциях наблюдения.Таблица 6.8
Интервальные структуры численности хищников-хватателей при относительно низком (группа А – класс качества воды < 4) и высоком (группа В – класс качества воды ³ 4) уровнях химического загрязнения
|
Градации числен-ности Nh хищников, экз./м2 |
Группа A (класс < 4)N1 = 186 |
Группа В (класс ³ 4)N2 =142 |
Вклад в информа-тивность |
Дивергенция и статистика Кульбака |
Средние значения численности в группах А и В и их отличие по t-критерию |
|
|
0 - 3 |
28 (15.1%) |
118 (33.3%) |
0.263 |
J = 0.307J'(4,1)=37.4 PJ < 0.0001 |
Гр. А |
Гр. В |
|
5 - 10 |
9 (4.8%) |
4 (1.1%) |
0.030 |
406.1 |
390.3 |
|
|
12 - 120 |
62 (33.3%) |
99 (28.0%) |
-0.025 |
t = 0.129tкр = 1.65 р = 0.45 |
||
|
130 - 140 |
7 (3.8%) |
1 (0.3%) |
0.068 |
|||
|
³ 149 |
80 (43.0%) |
132 (37.3%) |
-0.029 |
|||
Анализ соотношения составляющих дивергенции Кульбака (вклада в информативность) свидетельствует о том, что различия между группами на 85% обусловлены малыми значениями численности хищных видов зообентоса (диапазон от 0 до 3), которые в "грязных" условиях среды встречаются значительно чаще.
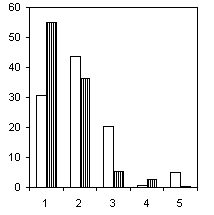
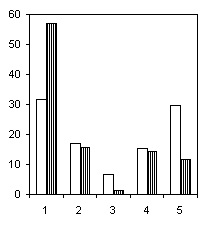
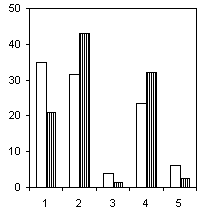
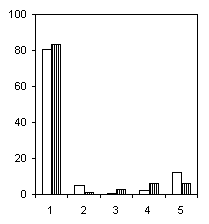
Рассмотрим еще один пример. На гистограммах рис. 6.4 представлено распределение численности некоторых подсемейств и триб хирономид по оптимальным диапазонам разбиения, контрастирующим различия групп наблюдений с разными классами качества воды (группирующий признак тот же, что и в предыдущем примере).
|
Таксономические группы |
Градации диапазонов |
Вклад в информа-тивность |
Распределение относительных частот по интервалам структуры, % |
|
|
начало |
конец |
|||
|
Подсемейство Orthocladiinae, J = 0.507 |
0 |
10 |
0.145 |
|
|
13 |
334 |
0.013 |
||
|
340 |
1440 |
0.192 |
||
|
1480 |
3160 |
0.032 |
||
|
3300 |
22880 |
0.125 |
||
|
Триба Tanytarsini,J = 0.404 |
0 |
0 |
0.15 |
|
|
1 |
40 |
0.001 |
||
|
48 |
72 |
0.086 |
||
|
74 |
230 |
0.001 |
||
|
240 |
14000 |
0.167 |
||
|
Триба Chironomini,J = 0.189 |
0 |
35 |
0.072 |
|
|
40 |
560 |
0.034 |
||
|
570 |
640 |
0.028 |
||
|
660 |
6800 |
0.028 |
||
|
6880 |
24168 |
0.029 |
||
|
Подсемейство Tanypodinae,J = 0.169 |
0 |
240 |
0.001 |
|
|
250 |
280 |
0.049 |
||
|
299 |
350 |
0.039 |
||
|
360 |
540 |
0.041 |
||
|
560 |
18278 |
0.04 |
||
Рис. 6.4. Гистограммы распределения численности по интервалам для различных таксономических групп хирономид
Из всех групп хирономид, которые на рис. 6.4 следуют в порядке убывания информативности, наилучшими индикаторами чистых вод явились виды подсемейства Orthocladiinae, в то время, как наименьшей информационная ценность приходится на подсемейство Tanypodinae. Отчетливая зависимость от уровня загрязнения просматривается и для видов трибы Tanytarsini. Интересной оказалась связь с классом качества для видов трибы Chironomini, частота появления больших численностей которых характерна именно для грязных вод.
С использованием
J-критерия, предложенного А.А. Генкиным, для всех проанализированных таксономических подмножеств видов были установлены статистически значимые (pj < 0.0003) отличия между группами с разным уровнем загрязнения.Поскольку для видов Tanypodinae предыдущие методы ставили под сомнение эту гипотезу, можно предположить, что
J-критерий (впрочем, как и c 2) склонен к гипердиагностике вероятности различий между выборками, особенно, в случае большого их объема.Таким образом, сопряженные таблицы в рамках изложенной технологии оказываются уже не просто набором независимых друг от друга частот появления значений признака в определенных интервалах, а структурой, элементы которой – экологически значимые интервалы проявления жизнедеятельности таксономических групп в различных условиях среды.
Многолетний опыт использования описанного метода обработки при анализе лабораторных и инструментальных признаков отчетливо выявил, по крайней мере, 6 различных типов интервальных структур. Приведем некоторые из них.
Самый простой тип – линейные структуры, когда частоты для одного условия монотонно возрастают (убывают), а для другого – монотонно убывают (возрастают), т.е изменяются разнонаправлено. Более сложны для интерпретации часто встречаемые реципрокные
структуры, в которых нет монотонности, но частоты отрицательно коррелируют. Например, интервальные структуры, у которых частоты для минимальных и максимальных значений статистически неразличимы, а значения центральных частот реципрокны, называются реципрокными в центре (в фитоценологической ординации такие структуры носят названия “клинов”: топоклины, термоклины, галоклины, ценотопоклины и проч.) В некоторых типах структур реципрокность четко выражена только в двух диапазонах изменения признака, справа или слева.| Дальше
|
Назад |
Начало |
Конец |
Список
|