| Дальше
|
Назад |
Начало |
Конец |
Список
|
7.4. Оценка различий многомерных комплексов наблюдений
Формулировка задачи
Пусть в матрице наблюдений X каждый j-й столбец, j = 1, 2,…, m, представлен гидробиологическим показателем, а каждая i-я строка, i = 1,2,…,n, описывает гидробиологическое измерение, выполненное в некотором пространственно-временном аспекте. Предположим, что каждой строке i поставлен в соответствие некоторый качественный признак (фактор), на основании которого общую многомерную выборку можно сгруппировать в частные независимые случайные выборки: если фактор имеет p уровней A1, A2, …, Ap, то при каждом уровне Ak фактора, k = 1,...,p, имеется nk измерений. Необходимо проверить, насколько статистически значимо различаются между собой блоки матрицы X, относящиеся к разным уровням фактора A, и количественно оценить меру таких различий.
Как и в случае дисперсионного анализа, фактор, который оказывает влияние на количественные результаты измерений, имеет принципиально нечисловую природу и может соответствовать географическому объекту, где была взята проба, категории водоема или сезонному периоду.
Рекомендуемая литература: [Урбах, 1963; Дуда, Харт, 1978; Горелик, Скрипкин, 1984; Андреев, 1979а]
Математический лист
Статистические методы
Использование детерминистических методов кластеризации, описанных в разделе 7.3, оправдано в некоторых частных случаях, когда по условию задачи нужно получить простые решения или невозможно использовать вероятностные методы. Преемущества последних заключается в том, что они допускают наличие ошибок и неполноту знаний о сравниваемых объектах и оперируют с плотностью распределения вероятностей переменных.
В общем случае параметрические методы анализа многомерных наблюдений, принадлежащих к разным классам, основываются на формуле условных вероятностей, предложенной в конце XVIII в. малоизвестным священником и прекрасным английским математиком Томасом Байесом:
P
(x) P(Ak/x) = P(Ak) P(x/Ak) , (7.11)
(7.11)
где
P(x) – функция распределения плотности вероятности всех данных в m-мерном пространстве независимо от того, к какому классу они принадлежат; P(Ak) – вероятность наблюдения класса Ak; P(Ak/x) – условная вероятность того, что вектор x принадлежит классу Ak; P(x/Ak) – условная вероятность получения для класса Ak вектора данных x.Формула Байеса позволяет вычислить вероятность справедливости некоторой гипотезы на основании принятых априорных вероятностей. Этот метод в строгом смысле оправдан, если альтернативные гипотезы (в данном случае принадлежность измерения к некоторому классу) основываются на функциях плотности вероятностей, т.е. известны законы распределения случайной величины, которые могут быть оценены по эмпирическим данным.
Как отмечалось выше, в принятой модели данных – таблице наблюдений
X – совокупность n измерений может быть представлена "облаком" n точек в m-мерном пространстве, которое в целом можно охарактеризовать положением и степенью компактности. В большинстве методов многомерного анализа предполагается, что имеет место нормальное распределение случайной величины xij. Это связано с тем, что центральная предельная теорема для одной величины распространяется и на многомерный случай, т.е. последовательность сумм независимых одинаково распределенных случайных векторов сводится к многомерному нормальному распределению N(m , S ) с вектором (m´ 1) из средних m и матрицей (m´ m) ковариаций S .Для определенности рассмотрим задачу разделения двух множеств объектов (множества "Класс 1" и множества "Класс 2"). Очевидно, что два множества будут разделяться тем лучше, чем больше расстояние между их центрами. Кроме того, задача разделения множеств упрощается при условии сужения диаметров этих множеств, если фиксировано расстояние между оболочками и их центрами. Если к тому же многомерный закон распределения значений параметров является нормальным, то для любой пары признаков мы получим два эллипса, как это показано для двух координат
xj и xk на рис. 7.5. Левая часть рисунка соответствует ситуации, когда разделимость двух областей оценивается, как расстояние между центром области "Класс 1" и всеми точками множества "Класс 2". Правая часть соответствует ситуации, когда разделимость двух областей оценивается как расстояние между центром области "Класс 2" и точками "Класс 1". Пунктирные эллипсы на рис. 7.5 соответствуют ситуации, когда одновременно оценивается дисперсия обоих разделяемых областей, что упрощает задачу их разделения при неизменности расстояний между центрами этих областей. Центрам обеих областей соответствуют векторы математических ожиданий значений каждого признака: m(X1) и m(X2) для множеств объектов "Класс 1" и "Класс 2", соответственно.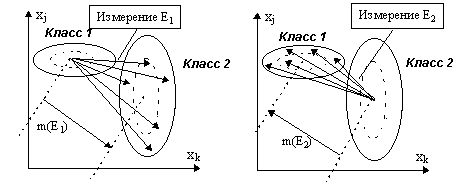
Рис. 7.5. Интерпретация расстояния Махаланобиса для объектов двух классов
Для измерения расстояния от центра области "Класс 1" до точек образа "Класс 2" целесообразно пользоваться квадратичной мерой – выборочным расстоянием Махалонобиса, которое при записи в векторной форме будет выглядеть следующим образом:
(D1)2=(X2-m(X1))T
С1-1 (X2-m(X1)),(7.12)
где (
X2-m(X1))T – транспонированный вектор расстояний между каждой точкой множества "Класс 2" и центром области "Класс 1", (X2-m(X1)) – этот же вектор расстояний по выбранным координатам, но без его транспонирования, С1-1 – обратная ковариационная матрица контролируемых параметров образов "Класс 1".По аналогии, для измерения расстояния от центра области "Класс 2" до точек множества "Класс 1" мера Махалонобиса будет иметь вид:
(D2)2=(X1-m(X2))T
С2-1 (X1-m(X2)),(7.13)
где (
X1-m(X2)) и (X1-m(X2))T – прямой и транспонированный векторы расстояний между конкретным примером "Класс 1" и центром области "Класс 2", С2-1 – обратная ковариационная матрица переменных для множества объектов "Класс 2".В многомерном случае элементы матрицы С, которая является несмещенной оценкой ковариационной матрицы
S , вычисляются по следующей формуле: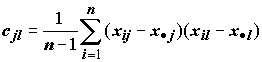 ,(7.14)
,(7.14)
где
j и l – все возможные пары индексов измеряемых признаков, j = 1,2,…,m, l = 1,2,…,m. Выражения в скобках – отклонения значений переменных xij от соответствующего общего среднего x· j. При j = l по формуле (7.14) вычисляются среднеквадратичные отклонения, которые соответствует выборочным дисперсиям отдельных переменных, а при j ¹ l оцениваются ковариации между двумя переменными. Если каждый элемент ковариационной матрицы С разделить на квадратный корень из произведения соответствующих диагональных элементов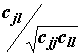 ., то получается рассмотренная в разделе 7.2 корреляционная матрица R.
., то получается рассмотренная в разделе 7.2 корреляционная матрица R.
Обратная матрица С
-1 находится специальными методами линейной алгебры путем определения нетривиального решения матричного уравнения C C-1 = I, где I – единичная матрица (т.е. матрица, состоящая из единиц, расположенных на главной диагонали). Следует обратить особое внимание на то, что вычисление ковариационных матриц С для векторов, состоящих из десятков и сотен переменных – это вполне реализуемая устойчивая техническая задача, имеющая квадратичную сложность. Однако, располагая вычисленными ковариационными матрицами С, поиск обратных матриц (например, по алгоритму Гаусса) является неустойчивой задачей кубической сложности, поэтому реальным является обращение матриц не более 100-го порядка.Структура приведенных выражений для расстояния Махалонобиса между вектором и множеством служит основой для построения обобщеного расстояния Махалонобиса, между образами "Класс 1" и "Класс 2" с векторами средних значений
m(X1) и m(X2), соответственно:D2
= (m(X1)-m(X2))T С-1 (m(X1)-m(X2)) .(7.15)
Приведенная статистическая мера удовлетворяет аксиомам расстояния только в случае равенства ковариационных матриц обоих классов С
1 и С2. Поэтому под С-1 обычно понимают некоторую усредненную величину, например, объединенную выборочную ковариационную матрицу видаС
= [(n1 – 1) C1 + (n2 – 1) C2] / (n1 + n2 – 2).(7.16)
К основным преимуществам обобщенного расстояния Махалонобиса следует отнести учет коррелированности признаков между собой и инвариантность относительно невырожденных линейных преобразований, что избавляет от необходимости нормировки исходной матрицы наблюдений. С использованием расстояния Махалонобиса возможна статистическая проверка гипотез о равенстве двух подмножеств векторов при неизвестной ковариационной матрице. Многомерным аналогом для двухвыборочной t-статистики Стьюдента является двухвыборочная T2-статистика Хоттелинга:
Т2 = (m(X1)-m(X2))T С-1 (m(X1)-m(X2)) n1n2 /(n1 +n2) = D2 n1 n2 /(n1 +n2) .
(7.17)
Eсли гипотеза Ho: m(X1) = m(X2) верна, то величина
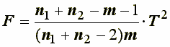 (7.18)
(7.18)
Алгебраический метод
Описанные выше методы многомерной статистики корректно применимы при выполнении ряда условий: мультинормальность распределения значений измеряемых признаков, равенство ковариационных матриц и достаточно большой объем выборок, позволяющий получать хорошие оценки ковариаций. Каждое из этих условий является скорее исключением, нежели обычной ситуацией, с которой имеет дело биолог. Эти обстоятельство побудили исследователей к поиску иных методов решения задачи разграничения двух совокупностей, основанных на некоторых эвристических принципах. Опишем кратко один из таких методов, предложенный В.Н. Котовым и Н.Г. Терентьевой [1989] и использующий понятие “биоквант”, который сами авторы определили как "алгебраический".
Общая формализация самого понятия разграничения казалось бы проста и естественна: две совокупности Х1 и Х2 считаются различными, если в некоторой метрике все внутригрупповые расстояния меньше межгрупповых. И действительно, случаи "идеального" разделения встречаются в практике. Однако объективная реальность имеет дело, как правило, с трангрессирующими совокупностями, где допускается существование общих или промежуточных форм, т.е. где торжествует принцип "неопределенности таксона", характерный для "размытых" множеств.
Более слабое понятие различия можно сформулировать следующим образом: две совокупности Х1 и Х2 считаются различными, если, используя некоторую метрику, в них можно выделить достаточно представительные по численности "скученности точек" Х1* и Х2*, различные в смысле предыдущего определения. Таким образом, биоквантом называются подмножества объектов Х1* и Х2*, для которых в заданном метрическом пространстве все внутригрупповые расстояния меньше всех межгрупповых. Пользуясь общепринятой терминологией, согласно которой максимальное расстояние между элементами множества называется диаметром этого множества, биокванты можно охарактеризовать следующим свойством: “Расстояние между биоквантом Х1* из совокупности Х1 и биоквантом Х2* из совокупности Х2 больше диаметра каждого из этих биоквантов”
Для нахождения биоквантов предложена [Котов, Терентьева, 1989] некоторая эвристическая процедура, основанная на преобразовании матрицы расстояний в стохастическую матрицу и расчете для каждого объекта Х
1 и Х2 специальных оценок включения в биокванты, равных стационарным вероятностям перехода в марковской цепи. После выделения биоквантов принимается или отвергается гипотеза о наличии различий между группами измерений по следующему достаточно условному эвристическому правилу:Результаты расчетов
Сформируем матрицу из 412 наблюдений, относящихся к 10 рекам Самарской области, по которым был проделан наиболее репрезентативный объем экспедиционных исследований. В составе р. Чапаевка, характеризующейся определенной региональной неоднородностью, выделим две группы станций, расположенных в верхнем течении (ст. 1-12) и ниже г. Чапаевска (ст. 13 – 23).
В качестве 8 контролируемых переменных будем использовать три группы признаков:
Для каждой пары групп измерений, относящихся к разным водоемам, рассчитаем обобщенное расстояние по Махалонобису D2, критерий Хоттелинга T2 и соответствующие ему F-критерий и значение вероятности p (см. табл. 7.5).
Таблица 7.5
Матрица оценок различий между многомерными комплексами гидробиологических наблюдений на реках Самарской области
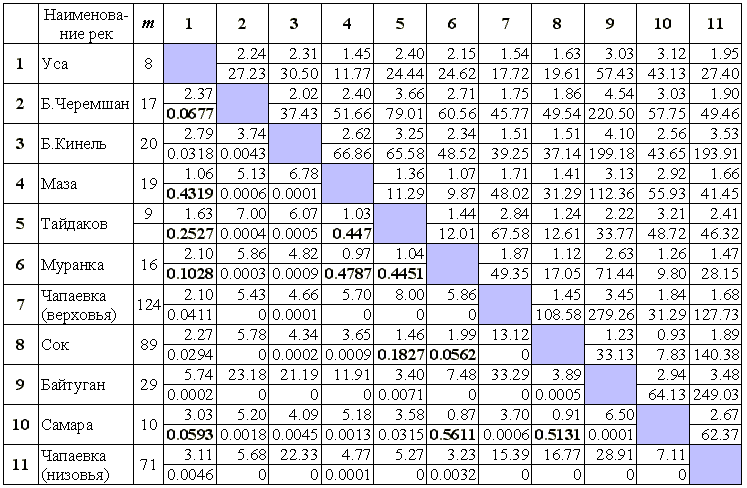
Примечание:
Для каждой пары рек в клетках, расположенных выше главной диагонали - обобщенное расстояние по Махалонобису D2 (вверху) и значения T2-критерия Хоттелинга (внизу); в клеткак, расположенных ниже главной диагонали – F-критерий и соответствующая ему вероятность p.Если величина
p превышает выбранный уровень значимости, то нет оснований отвергать нулевую гипотезу о том, что измерения, выполненные на данной паре водоемов, принадлежат к одной генеральной совокупности. Например, можно считать статистически сходными по данному комплексу признаков реки Маза (4) и Тайдаков (5), Маза и Муранка (6), Тайдаков и Муранка – эти и другие пары вероятностей, превышающие 0.05, отмечены в табл. 7.5 жирным шрифтом.Полученные значения обобщенной меры Махаланобиса,
T2 и F-критериев могут быть интерпретированы как матрицы расстояния между классифицируемыми объектами и обработаны описанными в предыдущем разделе алгоритмами кластерного анализа с целью построения дендрограмм.На рис. 7.6 приведены результаты классификации рек Самарского региона по методу Уорда. Необходимо отметить, что выброчные меры Махалонобиса
D2 зависят от объема n1 и n2 сравниваемых подвыборок, в результате чего при большом количестве измерений, характерных, например, для р. Чапаевка, коэффициенты расстояния оказываются сильно заниженными, что нашло свое отражение в результатах кластеризации на дендрограмме фиг. “а”. Значения критерия Хоттелинга T2 и F-критерия в этих же условиях являются несмещенными оценками, не так сильно зависящими от количества измерений, поэтому дают, по нашему мнению, более адекватные результаты кластеризации (см. фиг. “б” рис. 7.6).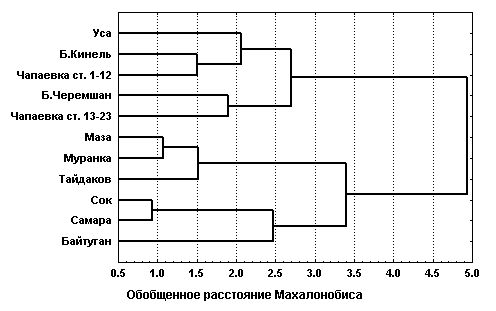
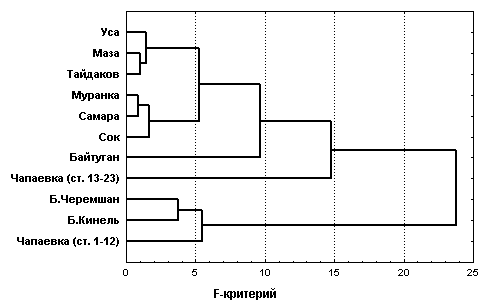
Рис. 7.6. Дендрограммы кластеризации рек Самарской области по методу Уорда с использованием обобщенного расстояния Махалонобиса и критерия Фишера
| Дальше
|
Назад |
Начало |
Конец |
Список
|