| Дальше
|
Назад |
Начало |
Конец |
Список
|
7.5. Задача о снижении размерности многомерного пространства: факторный анализ
Формулировка задачи
Исходными данными является знакомая по предыдущим разделам таблица наблюдений X, в столбцах которой представлены гидробиологические показатели, измеренные в количественной шкале (j = 1,2,…,m), а строки содержат описания экологических объектов в некотором пространственно-временном аспекте (i = 1,2,…,n).
Необходимо найти такое линейное преобразование исходной матрицы
X, которое позволило бы получить сжатое (редуцированное) представление входных данных в виде матрицы F с меньшим числом переменных p (m > p) без существенной потери содержательной информации об экологических объектах.Под факторным анализом понимается совокупность статистических моделей, описывающих и объясняющих наблюдаемые данные с помощью небольшого числа скрытых (латентных) факторов, которые могут быть сконструированы с помощью определенных математических методов. Модели факторного анализа применяются при решении следующих задач:
В экологии факторный анализ можно считать одним из первых серьезных многомерных методов статистики, использованных, в частности, для ординации растительности [
Goodall, 1954]. Имеется обширная литература как по применению факторного анализа вообще [Лоули, Максвелл, 1967; Харман, 1972; Айвазян с соавт., 1974; Дубров, 1978], так и по использованию его в экологических исследованиях [Василевич, 1969; Миркин, Розенберг, 1977б, 1978; Миркин с соавт., 1978а,б; Гелета, Крауклис, 1979; Нинбург, 1985; Колодяжный, 1985; Ястребов, 1991; Красовский, Воробьева, 1998; Сердюцкая, Каменева, 2000].Математический лист
Под моделью факторного анализа понимают представление исходных переменных в виде линейной комбинации факторов F
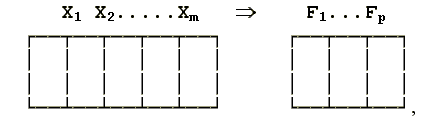
рассчитанных так, чтобы наилучшим способом (с минимальной погрешностью) представить Х
: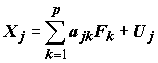
 (7.19)
(7.19)
В этой модели латентные переменные
Fk, k = 1,2,…,p, называются общими факторами, а переменные Uj , j = 1,2,…,m, – специфическими факторами (англ. – unique factor). Значения ajk называются факторными нагрузками.Основное требование к исходным данным для факторного анализа – это то, что они должны подчиняться допущению о многомерном нормальном распределении в совокупности. Для проверки этой гипотезы используют тест "сферичности" распределения данных Бартлетта, где оценивается предположение о диагональности матрицы корреляций. Если эта гипотеза не отвергается (т.е. наблюдаемый уровень значимости превышает 5%) – нет смысла в факторном анализе, поскольку направления главных осей случайны. На практике предположение о многомерной нормальности проверить весьма трудно, поэтому факторный анализ чаще всего применяется без такой процедуры, тем более, что ряд исследователей [Лоули, Максвелл, 1967] считает это допущение излишним.
Однако если предполагается, что все признаки
Xj стандартизованы (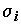 =1, m(Xj) = 0), а факторы F1, F2, …, Fp независимы и не связаны со специфическими факторами Uj, то факторные нагрузки ajk совпадают с коэффициентами корреляции между общими факторами и переменными Xj. Общая дисперсия признака Xj раскладывается при этом на сумму квадратов факторных нагрузок
=1, m(Xj) = 0), а факторы F1, F2, …, Fp независимы и не связаны со специфическими факторами Uj, то факторные нагрузки ajk совпадают с коэффициентами корреляции между общими факторами и переменными Xj. Общая дисперсия признака Xj раскладывается при этом на сумму квадратов факторных нагрузок 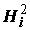 , которая называется общностью, и дисперсию специфического фактора
, которая называется общностью, и дисперсию специфического фактора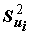 , или специфичность:
, или специфичность:
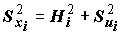
где 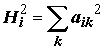 .(7.20)
.(7.20)
Другими словами, общность
представляет собой часть дисперсии переменных, объясненную факторами, а специфичность – часть дисперсии, обусловленную случайными ошибками или переменными, неучтенными в модели. В соответствии с постановкой задачи, необходимо искать такие факторы, при которых суммарная общность максимальна, а специфичность – минимальна.
Основным объектом преобразований в факторном анализе является корреляционная матрица из коэффициентов корреляции Пирсона (иногда – дисперсионно-ковариационная матрица), полученная обычным путем обработки массива данных
X. Выделение общих факторов и сжатие информации в ходе факторного анализа сводится к воспроизведению с той или иной степенью точности исходной корреляционной матрицы, т.е. предполагается, что редуцированная корреляционная матрица получена с использованием тех же объектов, но описанных меньшим числом переменных. Таким образом, следует уточнить, что фактически под сжатием информации в факторном анализе понимается уменьшение размерности корреляционной матрицы, а не самих данных, тем более что восстановить исходные данные по корреляционной матрице нельзя.Поскольку коэффициенты, составляющие корреляционную матрицу, могут вычисляться разным способом, различают следующие техники факторного анализа:
Одним из наиболее распространенных приемов поиска факторов является метод главных компонент. Его основное различие от факторного анализа заключается в том, что главные компоненты Fk связаны с наблюдаемыми переменными Xj линейными функциями преобразования:
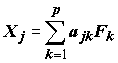
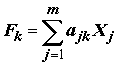 . (7.21)
. (7.21)
Метод главных компонент более прост в расчетах и интерпретации, но одна из главных трудностей его использования – необходимость преобразования исходных данных, представленных в разных единицах измерения, в сопоставимые величины. Традиционным методом преобразования является нормирование по стандартным отклонениям, когда матрица
Z стандартизованных исходных данных определяется по формуле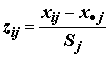 , где x·
j – среднее значение j-го признака; Sj – cтандартное отклонение; j = 1,2,…,m; i = 1, 2,…,n.
, где x·
j – среднее значение j-го признака; Sj – cтандартное отклонение; j = 1,2,…,m; i = 1, 2,…,n.
Для вычисления корреляционной матрицы
R размером m´ m, имеет место простое матричное соотношение: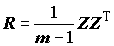 ,(7.22)
,(7.22)
где Т – символ транспонирования.
Основная идея метода главных компонент основана на следующем предположении: чем выше дисперсия вдоль какой-нибудь оси, тем больше информации содержат значения проекций на эту ось. Поэтому вполне естественно предпринять попытку отыскать ось с максимальной дисперсией, которую можно было бы рассматривать как "ординационную" со всеми вытекающими отсюда последствиями. Такая ось называется первой главной компонентой (фактором)
.Поиск всей системы взаимно перпендикулярных осей по методу главных компонент сводится к последовательной процедуре: т.е. вначале ищется первый фактор, который объясняет наибольшую часть дисперсии, затем независимый от него второй фактор, объясняющий наибольшую часть оставшейся дисперсии, и т.д.
Геометрически это выглядит следующим образом (см. рис. 7.7).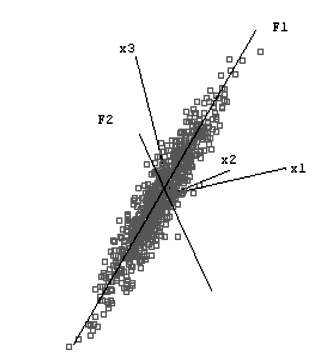
Рис. 7.7. Сжатие признакового пространства с применением факторного анализа
Для построения первого фактора
F1 берется прямая, проходящая через центр координат и облако рассеяния данных. При этом отыскивается такая ось, для которой сумма квадратов расстояний всех точек до перпендикуляра к этой прямой была бы максимальна. Это означает, что этой осью объясняется максимум дисперсии переменных. Найденная ось после нормировки используется в качестве первого фактора. Если "облако" данных вытянуто в виде эллипсоида (имеет форму "огурца"), фактор F1 совпадет с направлением, в котором вытянуты объекты, и по нему с наибольшей точностью можно предсказать значения исходных переменных. Для поиска второго фактора F2 ищется ось, перпендикулярная первому фактору, также объясняющая наибольшую часть дисперсии, не объясненной первой осью. После нормировки эта ось становится вторым фактором. Если данные представляют собой плоский элипсоид ("блин") в трехмерном пространстве, два первых фактора позволяют в точности описать эти данные. Максимально возможное число главных компонент равно количеству переменных.Основная модель метода главных компонент записывается в матричном виде следующим образом:
Z = AF
,(7.23)
где
Z – матрица m´ n стандартизованных исходных данных; A – матрица m´ p факторых нагрузок (факторное отображение); F – матрица p´ n значений факторов; m – количество переменных и n – количество объектов исходной матрицы; p – количество выделенных факторов. Очевидно, что неизвестными являются матрицы A и F.Вычислительные аспекты метода главных компонент сводятся к следующим шагам:
R = L V
,(7.24)
которое в общем случае имеет
m корней l , называемых собственными или характеристическими числами (англ. – eigen value) корреляционной матрицы R, каждому из которых соответствует вектор-столбец V базисных функций. Собственными значениями квадратной матрицы R порядка m называются такие значения l k, при которых система следующих m уравнений имеет нетривиальное решение:RVk
= l kVk ,(7.25)
где
Vk – собственные векторы матрицы R, соответствующие l k.; k = 1,2,…,m.ajk
= vik× ( l k )0.5 , j = 1, 2 ,…, m; k = 1, 2 ,…, p .(7.26)
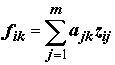 . (7.27)
. (7.27)
Основная проблема расчетов состоит в оценке того, сколько главных компонент необходимо построить для оптимального представления анализируемых исходных факторов. Величина l
k представляет не что иное, как часть суммарной дисперсии совокупности преобразованных данных, объясненную главной компонентой Fk. Если переменные стандартизованы, то l 1>l 2>l 3,… и необходимо иметь в виду, что первые несколько членов разложения дают основной вклад в объяснение вариации величин в исходных данных.Решение о том, когда следует остановить процедуру выделения компонент, зависит главным образом от точки зрения на то, что считать малой долей дисперсии. Это решение достаточно произвольно, однако имеются два критерия: критерий Кайзера (Kaiser) и критерий "каменистой осыпи" Кэттелла (Cattell), которые в большинстве случаев позволяют рационально выбрать число компонент. Но анализ составляющих с малыми величинами собственных значений едва ли целесообразен еще и потому, что они могут оказаться статистически недостоверными из-за ошибок различного происхождения. Ввиду того, что иллюстративной целью факторного анализа часто является получение факторного отображения в графическом виде, обычно ограничивают р = 2 и дают изображение пространства в двумерном срезе, поскольку выполнить это для трех и более выделенных факторов проблематично.
Для интерпретации факторов необходимо приписать каждому из них некоторый содержательный смысл, связанный с предметной областью. Чтобы понять, какая гидробиологическая реальность скрыта в найденных факторах, необходимо провести анализ корреляций факторных нагрузок с исходными переменными. Для повышения интерпретируемости факторов используют метод варимаксного вращения
VARIMAX, позволяющий добиться большей "выразительности" матрицы факторных нагрузок [Харман, 1972]. Его суть состоит в изменении координатных осей, образуемых факторами, с целью получить более контрастные нагрузки так называемой простой факторной структуры. Новые факторы в результате вращения осей ищутся в виде специального вида линейной комбинации имеющихся факторов: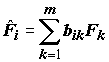 , максимизирующей "дисперсии" квадратов факторных нагрузок для переменных
, максимизирующей "дисперсии" квадратов факторных нагрузок для переменных
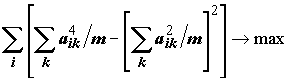 .(7.28)
.(7.28)
Чем сильнее разойдутся квадраты факторных нагрузок к концам отрезка [0,1], тем больше будет значение целевой функции вращения и тем четче интерпретация факторов.
Результаты расчетов
Выполним факторный анализ методом главных компонент с использованием примера, приведенного в разделе 7.2. Матрица парных коэффициентов корреляции Пирсона, рассчитанная по 453 наблюдениям для 19 признаков, отражающих обилие различных групп хирономид, и 3 гидрофизических признаков, представлена в табл. 7.3.
Были проведены две серии расчетов: для общего набора признаков и с использованием только гидробиологических показателей. В первом случае фактор 1, нагрузки для которого представлены в табл. 7.6, достаточно отчетливо можно приписать условиям существования биотопа – температуре, глубине и ширине водоема, кампанию которым, по трудно объяснимым причинам, составили личинки хирономид фитодетритофагов-собирателей из подсемейства Orthocladiinae.
Рассмотрим более подробно факторный анализ структуры хирономидного комплекса (расчет 2 в табл. 7.6). Последовательность выделения главных факторов можно представить в виде графика "каменной осыпи" на рис. 7.8, на котором можно усмотреть два "обвала": при 2 и при 6 отбираемых факторов.
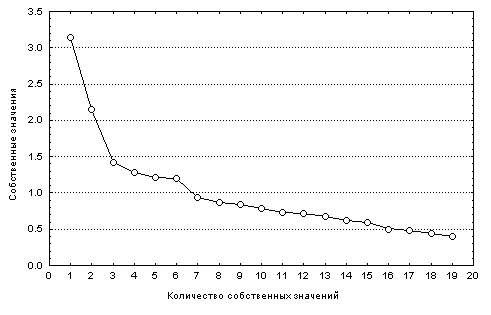
Рис. 7.8. График последовательности собственных значений при выделении главных факторов ("каменистая осыпь" Кэттелла)
Таблица 7.6
Факторные нагрузки по главным компонентам, рассчитанные на основе численности различных подсемейств и трофических групп хирономид
|
Переменная |
Факторы расчета 1 |
Факторы расчета 2 |
|||||||
|
1 |
2 |
3 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
Собственные значения |
3.53 |
2.56 |
1.47 |
3.14 |
2.15 |
1.42 |
1.28 |
1.22 |
1.21 |
|
Объясненная дисперсия, % |
16.04 |
27.67 |
34.37 |
16.52 |
27.85 |
35.33 |
42.07 |
48.48 |
54.83 |
|
Хищ. ChC |
-0.17 |
0.49 |
0.20 |
0.60 |
-0.20 |
-0.04 |
0.05 |
-0.04 |
-0.10 |
|
Хищ . Di |
0.39 |
-0.19 |
0.02 |
-0.05 |
0.01 |
0.02 |
-0.30 |
-0.01 |
0.73 |
|
Хищ . Or |
0.09 |
-0.11 |
0.08 |
-0.03 |
-0.04 |
0.00 |
-0.74 |
-0.15 |
0.03 |
|
Хищ . Pr |
0.41 |
-0.07 |
-0.54 |
-0.11 |
0.04 |
0.09 |
-0.06 |
0.73 |
0.30 |
|
Хищ . Tn |
0.02 |
0.60 |
0.00 |
0.61 |
0.20 |
-0.07 |
0.03 |
0.05 |
0.10 |
|
Вс/Соб ChC |
-0.12 |
0.63 |
0.31 |
0.67 |
0.01 |
-0.27 |
0.06 |
-0.10 |
-0.06 |
|
Вс/Соб Or |
0.25 |
0.06 |
0.60 |
0.00 |
0.07 |
-0.82 |
0.05 |
-0.06 |
0.04 |
|
Детр ChC |
-0.04 |
0.75 |
0.04 |
0.71 |
0.22 |
-0.03 |
-0.06 |
0.03 |
-0.12 |
|
Детр ChT |
0.49 |
0.54 |
0.01 |
0.32 |
0.70 |
-0.22 |
-0.05 |
0.12 |
0.08 |
|
Детр Or |
0.04 |
0.36 |
-0.23 |
0.16 |
0.58 |
0.27 |
0.03 |
-0.11 |
-0.15 |
|
Сест ChC |
0.09 |
0.25 |
0.59 |
0.24 |
-0.03 |
-0.70 |
-0.02 |
-0.10 |
-0.11 |
|
Сест ChT |
0.26 |
-0.07 |
-0.19 |
-0.08 |
0.09 |
0.02 |
-0.77 |
0.20 |
0.02 |
|
Сест Pr |
0.26 |
-0.03 |
-0.43 |
-0.11 |
0.01 |
-0.02 |
0.12 |
0.67 |
0.09 |
|
деТ/филь ChC |
-0.25 |
0.54 |
0.26 |
0.65 |
-0.14 |
-0.12 |
0.03 |
-0.17 |
-0.03 |
|
деТ/филь ChT |
0.31 |
-0.09 |
-0.09 |
0.02 |
-0.07 |
0.00 |
0.08 |
0.20 |
0.71 |
|
Фит/дет ChC |
-0.09 |
0.50 |
-0.03 |
0.51 |
0.12 |
0.22 |
0.04 |
-0.08 |
0.00 |
|
Фит/дет Di |
0.41 |
-0.13 |
0.00 |
-0.17 |
0.35 |
0.06 |
0.17 |
-0.09 |
0.52 |
|
Фит/дет Or |
0.68 |
0.03 |
-0.21 |
-0.23 |
0.71 |
-0.11 |
-0.08 |
0.27 |
0.16 |
|
Фит/дет Pr |
0.17 |
0.14 |
-0.58 |
0.01 |
0.12 |
0.11 |
-0.12 |
0.70 |
-0.19 |
|
Температура воды (дно) |
-0.61 |
0.30 |
0.19 |
||||||
|
Глубина реки |
-0.67 |
-0.12 |
-0.07 |
||||||
|
Ширина реки |
-0.60 |
-0.08 |
-0.04 |
||||||
Примечание:
В таблице использованы следующие условные обозначения трофических групп: “Хищ.” - хищники хвататели; “Вс/Соб” - всеядные собиратели+хвататели; “Детр” - детритофаги собиратели; “Сест” - сестонофаги+детритофаги фильтраторы; “деТ/филь” - детритофитофаги собиратели + фильтраторы; “Фит/дет” - фитодетритофаги собиратели; подсемейств и триб: Or – Orthocladiinae, Tn – Tanypodinae, Di – Diamesinae, Pr – Prodiamesinae, Ch – Chironominae (ChC – Chironomini, ChT – Tanytarsini)По отношению к водным экосистемам величины главных компонент и базисных векторов могут рассматриваться как показатели определенного типа взаимоотношений между совместно обитаемыми видами, или, иначе говоря, определенного типа ассоциирования. Например, первый фактор объединяет почти все трофические группы трибы
Chronomini, к которым добавились хищники Tanypodinae. Второй фактор структурно обозначен фитодетритофагами-собирателями Orthocladiinae и Tanytarsini. Для остальных четырех выделенных нами факторов также можно достаточно адресно подобрать доминирующие группы. Все 6 факторов объясняют около 55% общего статистического разброса, причем на первые два фактора приходится 29%.Кроме табличной формы используются графические методы визуализации результатов факторного анализа в виде двухмерных срезов факторного пространства или трехмерных диаграмм (см. рис. 7.9 и 7.10, соответственно).
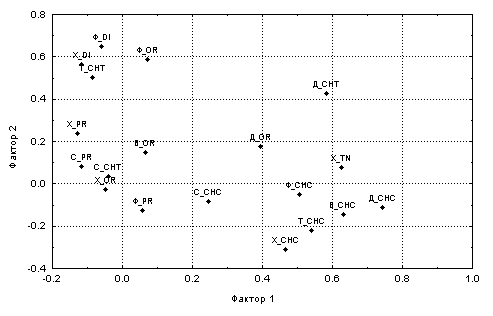
Рис. 7.9. Двухмерный график отображения факторных нагрузок
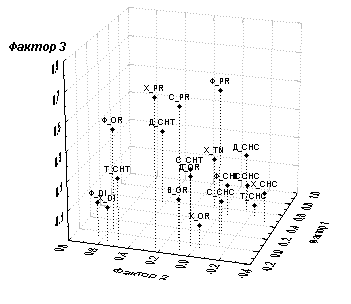
Рис. 7.10. Трехмерный график отображения факторных нагрузок
Используя расчитанные факторные нагрузки как коэффициенты линейного преобразования, можно сформировать редуцированную матрицу исходных данных, где столбцами являются новые факторизованные признаки. Выделение первых двух главных компонент дает возможность выполнить анализ двухмерной визуализации взаимного расположения объектов в свернутом пространстве факторов.
Поскольку выделение сгущений в облаке из 453 точек вызывает некоторые
"изобразительные" трудности, представим на рис. 7.11 расчетные точки, соответствующие групповым средним значений факторов, вычисленным по множеству измерений для каждой малой реки. При таком способе отображения следует иметь в виду, что большинство точек, представленных на рис. 7.11, является в свою очередь трангрессирующими кластерами, диаметр которых может перекрывать значительную часть диапазона варьирования факторов.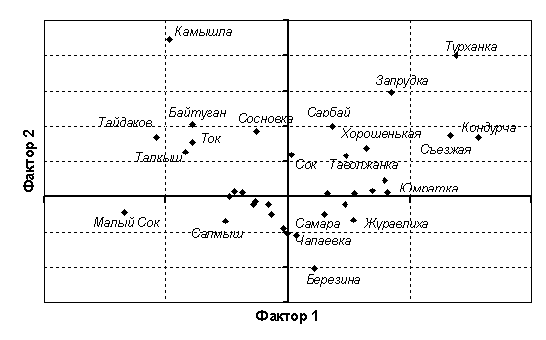
Рис. 7.11. Отображение малых рек Самарской области в пространстве двух главных факторов по результатам отбора проб хирономид
На рис. 7.12 представлено несколько рек из
"срединной" части общего графика и для них пунктиром обозначен доверительный интервал значений факторов (который значительно уже минимаксного интервала, соответствующего диаметру подмножеств). Река Чапаевка при этом была разделена на две части, соответствующие верхнему и нижнему течениям.
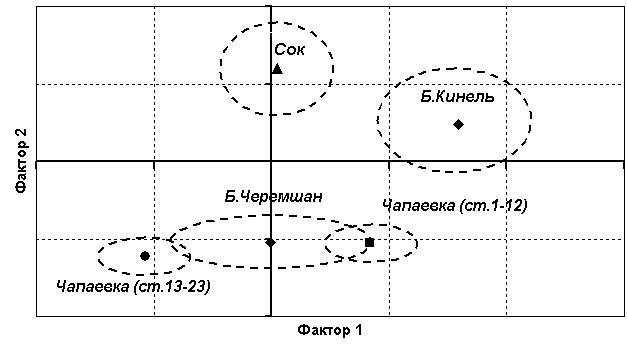
Рис. 7.12. Отображение четырех малых рек Самарской области в пространстве двух главных факторов по результатам отбора проб хирономид
(пунктиром обозначена доверительная область варьирования факторов для каждой реки)
Верхний правый квадрант обоих графиков соответствует рекам, у которых велико как значение фактора 1 (который мы ранее связали с обилием ассоциации хищных хирономид из трибы
Chronomini и подсемейства Tanypodinae), так и фактора 2 (фитодетритофаги-собиратели Orthocladiinae и Tanytarsini).Нижний левый квадрант объединяет объекты с низким обилием всех этих групп. Можно, например, предположить, что хирономидный комплекс р. Сок отличается от р. Б.Черемшан высоким обилием видов, объединяемых фактором 2, а верхнее течение р. Чапаевка по сравнению с нижним течением той же реки характеризуется более высокой численностью видов хирономид при одинаковом относительно низком обилии фитофильных личинок ортокладеин.
| Дальше
|
Назад |
Начало |
Конец |
Список
|