| Дальше
|
Назад |
Начало |
Конец |
Список
|
Глава 8. Задача о классе качества вод: прогноз отклика по многомерным эмпирическим данным
8.1. Модель множественной регрессии
Формулировка задачи
Пусть задано пространство признаков X' размерностью p > 1, точками которого являются конкретные измерения x = {x1, …, xj, …, xp}, где xj – значение j-го гидробиологического показателя в пробе или некоторого параметра среды, сопутствующего наблюдению. Предположим, что в матрице Х' один из столбцов считается объясняемой переменной или откликом y, а некоторое количество остальных признаков m, m < p, m > 1, определены нами как объясняющие или варьируемые переменные. Если массив наблюдений статистически репрезентативен, то можно сформировать обучающую выборку в виде матрицы независимых переменных X ® xij , j = 1,2,…,m, и сопряженного с ней вектора-столбца Y ® yi, где i = 1,2,…,n – количество строк измерений (n > m), для которых все значения численно определены. Если не оговорено противное, то матрица X дополняется столбцом с фиктивной переменной, тождественно равной единице, xi1 ≡ 1, что обеспечит вычисление свободного члена регрессии.
Необходимо сконструировать уравнение, выражающее закон изменения отклика Y в зависимости от конкретных значений независимых переменных X ® xij .
По аналогии с одномерной линейной регрессией (см. раздел 5.5) будем предполагать, что
модель наблюдений имеет вид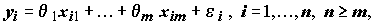
 (8.1)
(8.1)
где
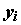 – значение объясняемой переменной в i-м наблюдении;
– значение объясняемой переменной в i-м наблюдении; 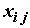 – известное значение j-ой объясняющей переменной в i-м наблюдении;
– известное значение j-ой объясняющей переменной в i-м наблюдении; 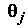 – неизвестный коэффициент при j-ой объясняющей переменной;
– неизвестный коэффициент при j-ой объясняющей переменной; 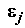 – случайная составляющая ("ошибка") модели для i-го наблюдения.
– случайная составляющая ("ошибка") модели для i-го наблюдения.
Использование множественного регрессионного анализа имеет чрезвычайно широкие возможности для обработки таблиц гидробиологических наблюдений, содержащих, как правило, десятки и сотни потенциальных переменных. В разделе 2.7 была выполнена формальная постановка задачи оценки качества воды, где в "роли" отклика
Y фигурировал некоторый показатель произвольной этиологии. Комбинируя факторы в различных сочетаниях, можно, дав простор фантазии, построить тысячи различных вариантов регрессионных моделей и доказать с их помощью любые, в том числе и диаметрально противоположные гипотезы о механизмах функционирования экосистем.Рекомендуемая литература: [Хальд, 1956; Андерсен, 1963; Себер, 1980; Дрейпер, Смит, 1986; Дюк, 1997; Айвазян, Мхитарян, 1998; С.А. Прохоров, 2001а,б, 2002
].Математический лист
Предположения модели и оценивание по методу наименьших квадратов
Нормальная линейная модель множественной регрессии переменной y с m объясняющими переменными x1, ..., xm основана на следующих предположениях:
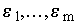 в формуле (8.1) представляют собой случайные величины, независимые в совокупности, имеющие одинаковые нормальные распределения N(0,s
i2) с нулевым математическим ожиданием и дисперсиями σi > 0;
в формуле (8.1) представляют собой случайные величины, независимые в совокупности, имеющие одинаковые нормальные распределения N(0,s
i2) с нулевым математическим ожиданием и дисперсиями σi > 0;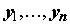
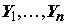 , которые независимы в совокупности, и для которых
, которые независимы в совокупности, и для которых
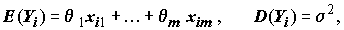
так что
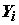 ~
~
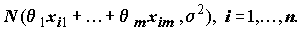 ;
;
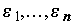 , случайные величины
имеют распределения, отличающиеся сдвигами.
, случайные величины
имеют распределения, отличающиеся сдвигами.Термин “множественная” указывает на использование в правой части модели наблюдений двух и более объясняющих переменных, отличных от постоянного члена.
Оценивание неизвестных коэффициентов модели методом наименьших квадратов (МНК) состоит в минимизации по всем возможным значениям 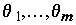 суммы квадратов
суммы квадратов
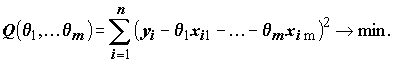 (8.2)
(8.2)
Для поиска значений коэффициентов
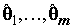 , минимизирующих эту сумму, необходимо решить систему из m нормальных линейных уравнений с m неизвестными, которая в векторно-матричной форме имеет вид:
, минимизирующих эту сумму, необходимо решить систему из m нормальных линейных уравнений с m неизвестными, которая в векторно-матричной форме имеет вид:
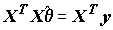 , (8.3)
, (8.3)
где:
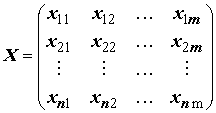 – матрица значений m объясняющих переменных в n наблюдениях; Xт – та же матрица в транспонированном виде;
– матрица значений m объясняющих переменных в n наблюдениях; Xт – та же матрица в транспонированном виде;
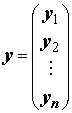
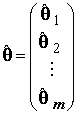 – соответственно, вектор-столбец значений объясняемой переменной в n наблюдениях и вектор-столбец оценок m неизвестных коэффициентов. Система нормальных уравнений (8.3) имеет единственное решение
– соответственно, вектор-столбец значений объясняемой переменной в n наблюдениях и вектор-столбец оценок m неизвестных коэффициентов. Система нормальных уравнений (8.3) имеет единственное решение
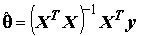
(8.4)
если
матрица XTX не вырождена, т.е. ее определитель отличен от нуля (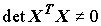 ), что соответствует линейной независимости столбцов матрицы Х.
), что соответствует линейной независимости столбцов матрицы Х.
Обозначив расчетные
(т.е. подобранные – fitted) значения объясняющей переменной по оцененной линейной модели связи как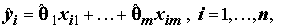 и остаток (residual) для i-го наблюдения как
и остаток (residual) для i-го наблюдения как 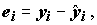 получим остаточную сумму квадратов:
получим остаточную сумму квадратов:
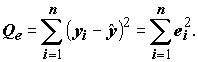 (8.5)
(8.5)
Если рассчитать полную сумму квадратов отклонений
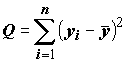 (8.6)
(8.6)
и объясненную моделью (explained) сумму квадратов
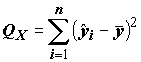 ,(8.7)
,(8.7)
то, как и в случае простой линейной регрессии с
m = 2, все эти три суммы квадратов связаны соотношениемQ = Qx + Qe ,(8.8)
которое представляет собой разложение полной суммы квадратов. Коэффициент детерминации модели регрессии
R2 определяется как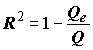 (8.9)
(8.9)
и равен
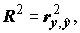 где
где 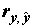 – выборочный множественный коэффициент корреляции между переменными y и
– выборочный множественный коэффициент корреляции между переменными y и 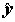 . Значение R2 монотонно возрастает с ростом числа переменных (регрессоров) в регрессии, что зачастую не означает улучшения качества предсказания. Потому правильнее использовать скорректированный (adjusted) коэффициент детерминации, учитывающий число использованных регрессоров:
. Значение R2 монотонно возрастает с ростом числа переменных (регрессоров) в регрессии, что зачастую не означает улучшения качества предсказания. Потому правильнее использовать скорректированный (adjusted) коэффициент детерминации, учитывающий число использованных регрессоров:
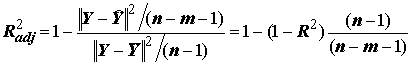 .(8.10)
.(8.10)
Проверка адекватности модели
Определяющим для проверки статистической значимости уравнения является то обстоятельство, что в нормальной линейной модели с несколькими объясняющими переменными оценки коэффициентов 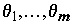 как случайные величины имеют нормальные распределения. Это дает возможность проверить гипотезу
как случайные величины имеют нормальные распределения. Это дает возможность проверить гипотезу 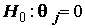 , которая соответствует предположению исследователя о том, что j-я объясняющая переменная не имеет существенного значения для интерпретации изменчивости величины переменной y и может быть исключена из модели. Если гипотеза не отвергается, то отношение оценки
, которая соответствует предположению исследователя о том, что j-я объясняющая переменная не имеет существенного значения для интерпретации изменчивости величины переменной y и может быть исключена из модели. Если гипотеза не отвергается, то отношение оценки 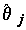 к его стандартному отклонению
к его стандартному отклонению 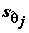 соответствует t-распределению Стьюдента с n - m степенями свободы, а критическое множество для уровня значимости
соответствует t-распределению Стьюдента с n - m степенями свободы, а критическое множество для уровня значимости 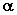 имеет вид
имеет вид
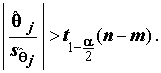 (8.11)
(8.11)
В современных компьютерных программах кроме
t-статистики приводится также Р- значение – вероятность того, что случайная величина, имеющая распределение Стьюдента с (n – m) степенями свободы, примет значение, не меньшее по абсолютной величине, чем наблюденное значение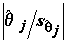 . Если указываемое P-значение меньше выбранного уровня значимости , то это равносильно тому, что значение t-статистики
. Если указываемое P-значение меньше выбранного уровня значимости , то это равносильно тому, что значение t-статистики 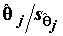 попало в область отвержения гипотезы
попало в область отвержения гипотезы  , т.е.
, т.е. 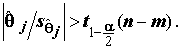 В этом случае параметр
В этом случае параметр 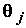 статистически значим и наличие j-й объясняющей переменной в правой части модели существенно для описания наблюдаемой изменчивости объясняемой переменной.
статистически значим и наличие j-й объясняющей переменной в правой части модели существенно для описания наблюдаемой изменчивости объясняемой переменной.
Кроме того, полезно проверить гипотезу об информационной способности всей модели в целом (или, другими словами, гипотезу об общей значимости регрессии в рамках нормальной линейной модели
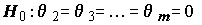 ) c использованием F-статистики, которая основана на отношении регрессионной суммы квадратов Qx к остаточной сумме квадратов Qe :
) c использованием F-статистики, которая основана на отношении регрессионной суммы квадратов Qx к остаточной сумме квадратов Qe :
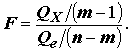 (8.12)
(8.12)
Действительно, чем больше отношение
Qx / Qe , тем больше есть оснований говорить о том, что совокупность переменных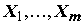 действительно объясняет изменчивость отклика Y. Если выполняются перечисленные выше предположения, то F-статистика, рассматриваемая как случайная величина, имеет при гипотезе H0 стандартное F-распределение Фишера с (m - 1) и (n - m) степенями свободы. В соответствии с этим, гипотеза отвергается при "слишком больших" значениях F, превышающих пороговое значение при заданном уровне α значимости:
действительно объясняет изменчивость отклика Y. Если выполняются перечисленные выше предположения, то F-статистика, рассматриваемая как случайная величина, имеет при гипотезе H0 стандартное F-распределение Фишера с (m - 1) и (n - m) степенями свободы. В соответствии с этим, гипотеза отвергается при "слишком больших" значениях F, превышающих пороговое значение при заданном уровне α значимости:
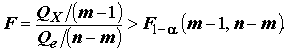 (8.13)
(8.13)
При этом вероятность ошибочного отвержения гипотезы
равна . Статистические пакеты, выполняющие регрессионный анализ, приводят кроме F -статистики соответствующее ей P-значение, т.е. оценивается вероятность 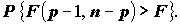 Если Р-значение меньше заданного уровня значимости (равного, например, a
= 0.05), то уравнение регрессии считается информативным или "значимым в целом". Можно также отметить такой неслучайный факт, что при анализе модели простой (парной) линейной регрессии (p = 2) вычисленные Р-значения F-статистик совпадают с Р-значениями t-статистик, используемых для проверки гипотезы
Если Р-значение меньше заданного уровня значимости (равного, например, a
= 0.05), то уравнение регрессии считается информативным или "значимым в целом". Можно также отметить такой неслучайный факт, что при анализе модели простой (парной) линейной регрессии (p = 2) вычисленные Р-значения F-статистик совпадают с Р-значениями t-статистик, используемых для проверки гипотезы 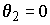 .
.
Переменные, включаемые в модели
"Фиктивные переменные" используются как противоположность "значащим переменным", показывающим уровень количественного показателя, принимающего значения из непрерывного интервала. Как правило, фиктивная переменная – это индикаторная переменная, отражающая некоторую качественную характеристику. Например, сезонные фиктивные переменные принимают разные значения в зависимости от того, какому месяцу или кварталу года или какому дню недели соответствует наблюдение. Часто применяются бинарные фиктивные переменные, принимающие два значения, 0 и 1, в зависимости от определенного условия. Например, в результате моделирования 0 может означать, что наблюдение принадлежит к "грязным" водоемам, а 1 – к "чистым". Фиктивные переменные, будучи экзогенными, не создают каких-либо трудностей при применении МНК и являются эффективным инструментом построения регрессионных моделей и проверки гипотез.В линейной регрессионной модели математическое ожидание зависимой переменной – это линейная комбинация регрессоров с неизвестными коэффициентами, которые и являются оцениваемыми параметрами модели. Такая модель является линейной по виду и в матричной форме ее можно записать как
Y = Xq + e . Однако не обязательно, чтобы влияющие на Y факторы входили в модель линейно – регрессорами могут быть любые точно заданные (не содержащие неизвестных параметров) функции исходных факторов – это не меняет свойств МНК:yi
= q o +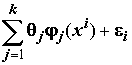 , i = 1, ..., n,(8.14)
, i = 1, ..., n,(8.14)
где j
j ( ), j = 1, ..., m – система некоторых функций.Для применения метода наименьших квадратов важно, чтобы выполнялись два условия:
Линеаризация не должна быть самоцелью – может случиться, что "истинная" модель бывает настолько нелинейной, что приходится пожертвовать удобствами общего МНК и использовать нелинейные методы оценивания параметров.
Основное преимущество учета нелинейности для простых моделей связано с компенсацией гомоскедастичности при расчете параметров уравнения регрессии. В методе наименьших квадратов все наблюдения выступают в одинаковых "весовых категориях", и поэтому в оценках непропорционально мало используется информация от признаков с меньшей дисперсией. В то же время, многие гидробиологические переменные таковы, что размер отклонений, связанных с ними, пропорционально зависит от величины самих переменных и возникающая при этом гетероскедастичность снижает эффективность оценок параметров. Например, логарифмирование численности или биомассы существенно может улучшить адекватность расчетного уравнения.
Расширение переменных уравнения регрессии за счет использования различных функциональных генераций исходных признаков позволяет также уменьшить недоопределенность модели, когда сложность структуры аппроксимирующей функции недостаточна для отображения сложности изучаемого динамического процесса (“Время простых моделей прошло” – У.Р. Эшби). Например, в разделе 2.7 было показано, что огромное большинство процессов в природе может быть описано в виде полиномов высокой степени, являющихся частным случаем обобщенного полинома Колмогорова – Габора (1.13):
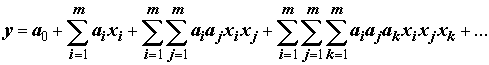 .
.
Поэтому основная задача моделирования сложных систем с использованием регрессионных уравнений заключается в том, чтобы "обнулить" (вычеркнуть) в полиноме Колмогорова – Габора подмножество "лишних" или незначимых коэффициентов и сохранить оптимальное сочетание объясняющих членов (выражаясь образным языком – “отсечь все лишнее от глыбы мрамора, превратив ее в статую”
). Крупные математики и наши современники

Кроме натуральных степеней исходных переменных можно использовать и другие функции от них: ln
X,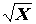 , 1/X , e a
X, тригонометрические преобразования, логистическую функцию 1/(1+e–X), преобразование Бокса-Кокса
, 1/X , e a
X, тригонометрические преобразования, логистическую функцию 1/(1+e–X), преобразование Бокса-Кокса 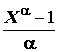 и т.д. В качестве примера использования такого подхода в гидробиологии можно привести работу В.А. Тереховой с соавторами [1998].
и т.д. В качестве примера использования такого подхода в гидробиологии можно привести работу В.А. Тереховой с соавторами [1998].
Методы структурной идентификации моделей.
Обычно исследователь обладает достаточной свободой при выборе функциональной формы модели. Важно лишь, чтобы при этом не нарушались те условия, которые необходимы для хорошей работы применяемых методов оценивания. Но при этом нужно не забывать проводить проверку правильности спецификации модели и исправлять уравнение, когда получена плохая диагностика (например, исключать или добавлять одночлены более высоких степеней в полиномиальную модель).
Принцип множественности моделей утверждает, что для сложных систем по экспериментальным данным нельзя ограничиваться одной единственной моделью. Для каждого объекта, рассматриваемого как некоторый черный ящик, можно найти бесконечное множество уравнений, имеющих одинаковые или почти одинаковые внешние проявления. Однако логика научных исследований требует селекции одной или нескольких моделей регрессии оптимальной или субоптимальной структуры. Для решения этой задачи генерируются определенные наборы уравнений различной сложности и отбираются лучшие из них по некоторому целесообразно заданному критерию регуляризации.
Большинство таких критериев стремится найти компромисс между сложностью и лаконизмом. Иными словами, в уравнение регрессии включается только то минимальное подмножество входных информативных переменных x, которое без существенной потери информации позволяет объяснить имеющийся статистический разброс.
Стандартная пошаговая процедура "включений с исключениями", впервые описанная в работе М.А. Эфроимсона [Efroimson, 1960; Афифи, Эйзен, 1982; Дрейпер, Смит, 1986], и базирующаяся на общей идее метода наименьших квадратов, позволяет с заданной надежностью выбрать из полной матрицы стандартизированных нормальных уравнений наилучшую невырожденную подматрицу, т.е. выбрать модель наиболее оптимальной структуры. Включение и исключение переменных в модель осуществляется с использованием некоторой статистики – t-критерия для проверки равенства нулю частного коэффициента корреляции. Квадрат этого критерия имеет F-распределение и поэтому называется последовательным (или частным) F-критерием Фишера для включения (либо исключения).
Выбор первой переменной для включения в модель осуществляется для признака
xl, который имеет наибольший по абсолютной величине коэффициент парной корреляции с откликом rql. При этом процедура включения выполняется, если справедливо неравенство для последовательного F-критерия: F > Fo, где Fo – наперед заданное исследователем пороговое значение. Процесс расширения количества переменных модели повторяется многократно, пока статистическая значимость включения очередного признака по F-критерию на каждом шаге превышает заданный порог Fо. После очередного расширения модели анализируется взаимная коррелированность отобранных переменных и, если их взаимосвязь существенна, то лишние факторы, вносящие наименьший вклад, из модели исключаются. Более точно, исключению подлежат те переменные, для которых вычисленное значение частного F-критерия меньше Fо. Вычисления прекращаются, если не осталось ни одной переменной, для которой вычисленное значение последовательного F-критерия превысило бы заданный порог.Робастные методы регрессии
Если распределение ошибок в регрессии отличается от нормального, то это не приводит к таким серьезным последствиям, как несостоятельность оценок. Все же на нормальность рекомендуется обращать внимание, т.к. если распределение ошибок имеет "толстые хвосты" или сильно асимметрично, то метод наименьших квадратов может давать не очень точные оценки. Кроме того, отсутствие нормальности означает, что вычисляемые t- и F-статистики не распределены в конечных выборках точно как t и F. Хотя эти статистики остаются состоятельными, но при сильном отклонении от нормальности асимптотическое приближение может быть очень неточным, особенно, если размер выборки мал. Использование, так называемых, робастных методов оценивания позволяет повысить эффективность регрессионного анализа.
В медианной регрессии оценки получаются минимизацией суммы модулей отклонений, а не суммы квадратов отклонений, как в методе наименьших квадратов, что делает расчеты более устойчивыми к "аномальным выбросам" измерений.
В отличие от обычной регрессии, квантильная регрессия оценивает не математическое ожидание зависимой переменной, а одну из квантилей.
Метод инструментальных переменных применяется в случае, когда ошибка в регрессии может быть скоррелирована с некоторыми из регрессоров. Чаще всего его используют для оценивания отдельного уравнения из системы одновременных уравнений. В этом контексте он известен как двухшаговый метод наименьших квадратов.
В линейной регрессии с мультипликативной гетероскедастичностью дисперсия ошибки равна
e(Z(i)w ), где Z – матрица, состоящая из переменных, от которых зависит дисперсия, w – вектор параметров гетероскедастичности.Тобит (цензурированная регрессия) – это регрессионная модель, в которой зависимая переменная является цензурированной, т.е. зависимая переменная преобразовывается, если она меньше (или больше) некоторой границы. Типичным примером является модель с левым цензурированием в нуле, когда вместо наблюдаемого отклика
y*i принимается переменная yi, которая получает значения yi = 0, если y*i < 0 и yi = y*i, если y*i ³ 0. В отличии от тобита, в модели усеченной регрессии наблюдение целиком исключается, если отклик меньше (или больше) некоторой границы.Результаты расчетов:
Приведем несколько характерных примеров расчета уравнений регрессии, но прежде необходимо еще раз обратить внимание на то, что эти результаты мы трактуем как "истину" в некоторой ограниченной "области справедливости", а именно – все полученные выводы характерны для изучаемого нами объекта (малых рек Самарской области) и вытекают из конкретного собранного материала со всеми его неточностями и условностями.
Моделирование среднего веса особи
Одной из важнейших характеристик сообществ зообентоса является его размерная структура, выраженная в изменчивости “средних индивидуальных масс особей Wср” (термин из работы В.А. Яковлева [2001] не вполне корректен, т.к. "средний" показатель не может быть одновременно "индивидуальным"). Показатель Wср предлагается [Яковлев, 2001] считать одним из “фундаментальных свойств водных экосистем”. Автором найдена основополагающая прямo пропорциональная зависимость между разнообразием (индексом Шеннона Н) и Wср, “которая сохраняется даже в антропогенно-нарушенных условиях”. Высказываются гипотезы, что средний вес особи закономерно возрастает, например, от горных ландшафтов к лесистым, от бессточных озер к проточным, от глубоководных участков к мелководьям и т.д.
Будем считать средней массой особи Wср частное от деления суммарной биомассы (мг) на суммарную численность для некоторого подмножества организмов, наблюдаемых в конкретной гидробиологической пробе. Эта масса может быть рассчитана как средняя для вида, трибы, семейства, трофической группы или всего зообентоса в целом. Такое усреднение может показаться неправомочным, как не имеющее гидробиологического смысла, однако можно вспомнить, что весьма представительная теория термодинамики идеальных газов основывается на аналогичном показателе – кажущейся (или приведенной) молекулярной массе компонентов, входящих в газовую смесь, которую никто не считает неестественной. Разумеется, речь в данном контексте будет идти уже не о реальном весе какого-то конкретного организма, а о некотором интегральном показателе гидробиологического сообщества, напрямую зависящем от текущего соотношения видов.
Сформируем пять выборок, содержащих значения средней массы особи W для всего зообентоса в целом по результатам 540 проб наблюдений, а также отдельно для видов хищников-хватателей (384 измерения), семейств Oligochaeta (418 изм.), Chironomidae (473 изм.) и трибы Chironomini (337 изм.), встретившихся в тех же пробах. Будем искать регрессионную зависимость среднего веса особи от следующих восьми переменных:
Тип водоема
XTW был специфицирован по следующей последовательности категорий: 1 – ручьи и родники, 2 – малые реки возвышенностей, 3 – малые равнинные реки, 4 – средние равнинные реки, 5 – устья, 6 – озера и водохранилища.Таблица 8.1
Параметры уравнений регрессии, связывающих средний вес особи (
W) с комплексом варьируемых переменных (обозначения см. по тексту).|
Группа |
M ± m |
Уравнение регрессии |
R2 / F |
| Все виды зообентоса |
53.8 ±
|
W = - 270.6 + 58.1× XNB + 34.2× XH - 13.87× XS - 2.87× XV - 126.8× XP + 4.77× XMS - 30.65× XKk + 21.45× XTW |
14.15 |
|
ln(W) = - 3.86+ 0.671× XNB + 0.38× XH - 0.126× XS - 0.006× XV - 0.885× XP + 0.019× XMS - 0.13× XKK + 0.189× XTW |
33.86 |
||
| Хищники хвататели |
4.66 ±
|
ln(W) = 1 + 0.044× XNB + 0.018× XH - 0.006× XS + 0.071× XV + 0.164× XP - 0.059× XMS - 0.0003× XKK - 0.198× XTW |
6.96 |
| Семейство Oligоhаetae |
2.95 ±
|
ln(W) = -0.55 + 0.139× XNB + 0.056× XH - 0.044× XS + 0.03× XV - 0.006× XP - 0.158× XMS + 0.067× XKK + 0.029× XTW |
8.15 |
| Семейство Chironomidae |
2.01 ±
|
ln(W) = -0.93 + 0.148× XNB + 0.109× XH - 0.046× XS - 0.06× XV + 0.375× XP - 0.036× XMS + 0.065× XKK + 0.033× XTW |
15.53 |
|
Триба Chironomini |
1.52 ±
|
ln(W) = 1.1 + 0.014× XNB + 0.028× XH - 0.02× XS - 0.003× XV + 0.16× XP - 0.113× XMS + 0.066× XKK - 0.149× XTW |
5.26 |
Примечание:
Жирным шрифтом отмечены статистически значимые коэффициенты по t-критерию.По результатам расчетов, представленным в таблице 8.1, можно сделать следующие выводы:
Уместно на этом примере заметить, что полезность признака, как регрессора не всегда соответствует величине t-критерия Стьюдента, поскольку последний исходит из предположения о взаимной независимости переменных и не учитывает их взаимную коррелированность.
Пошаговая регрессия для оценки связи гидрохимических и гидробиологических показателей
Искусство регрессионного анализа заключается не в прямолинейной технике расчета коэффициентов уравнений, а в тщательной селекции наиболее существенных регрессоров и учете нелинейного характера их связи с откликом, что объединяется в понятие “структурной идентификации модели”. Рассмотрим использование пошаговой процедуры в расширенном пространстве переменных на примере анализа связи между гидрохимическими и гидробиологическими показателями.
Сформируем исходный набор признаков из следующих 7 показателей: XH – информационного индекса Шеннона, XV – биотического индекса Вудивисса, XP – олигохетного индекса Пареле, XСI – хирономидного индекса Балушкиной, числа видов XS, логарифмов суммарной численности XN и биомассы XB зообентоса в пробе. Добавим в таблицу признаков столбцы вторичных переменных, которые будем получать за счет всех возможных парных произведений и различных математических функций от всех 7 исходных переменных: XH2, XH× XV , XH× XP , XH× XP XCI ,…, 1/XH , XH0.5, 1/XH0.5 и т.д. Общее число варьируемых переменных после преобразования матрицы данных и включения базисных функций увеличивается с 7 до 55.
Зададимся, согласно рекомендациям А. Афифи и С. Эйзена [1982], пороговым значением для частного F-критерия = 3.5 и, используя пошаговый метод включений с исключениями Эфроимсона, получим следующие модели регрессии для различных гидрохимических показателей:
Yp
= 0.0917 – 0.0337× XS0.5 + 0.012× XB ,т.е. увеличение содержания фосфора сопровождается уменьшением числа видов и увеличением биомассы зообентоса, что характерно для процессов эвтрофирования;
YNH4
= 0.00619 + 0.69 / XS + 0.00107× XS× XN + 0. 074× XP× XN - 0. 239× XH× XP;YO
= 1.096+ 6.58 / XS + 0.132× XH× XCI - 9.22× XP + 1. 32 / (XCI)0.5YFe
= 0.13 - 0.087× XP× XS + 1.39× XP2 + 0.0039× XN× XB .Преимущество пошаговой процедуры, выполнившей подбор информативной комбинации из 55 признаков, заключается не только в компактности получаемых уравнений, но и в существенном повышении уровня их адекватности. Все представленные модели являются достоверными с высоким уровнем значимости, когда как практически все коэффициенты регрессии аналогичных полных линейных уравнений на основе тех же 7 признаков статистически недостоверны по
t-критерию. Читатель может сравнить в табл. 8.2 значения коэффициентов детерминации и F – статистик Фишера для оценки значимости двух типов регрессий: полной линейной и нелинейной с селекцией переменных для моделирования одного и того же отклика.Таблица 8.2
Сравнительные характеристики регрессионных моделей, связывающих гидрохимические и гидробиологические показатели
|
Наименование отклика (гидрохимического показателя) |
Типы регрессионных моделей |
|||||
|
На основе индексов и обобщенных показателей |
На основе относительной численности таксономических групп |
|||||
|
Полная линейная модель |
Нелинейная модель с селекцией переменных |
|||||
|
R2 / r |
F / p |
R2 / r |
F / p |
R2 / r |
F / p |
|
|
Фосфор минеральный |
7.35 |
1.775 |
9.75 |
6.154 |
32.08 |
6.91 |
|
Азот аммонийный |
4.185 |
0.804 |
17.49 |
4.293 |
47.65 |
8.09 |
|
БПК 5 |
5.02 |
1.123 |
29.87 |
6.899 |
43.51 |
10.12 |
|
Железо |
11.6 |
1.675 |
28.26 |
8.27 |
43.75 |
6.03 |
Определяющими параметрами в уравнениях, полученных пошаговой процедурой, являются "натуральные" показатели
XS, XN и XB, а столь популярные в гидробиологических работах индексы в нашем примере играют роль очевидных статистов. Например, биотический индекс Вудивисса вообще оказался не связанным ни с одним из гидрохимических показателей.Связь гидрохимических показателей с обилием таксономических групп
Сформируем матрицу варьируемых переменных из относительных долей таксономических групп зообентоса:
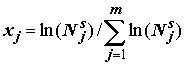 ,(8.15)
,(8.15)
где
Nsj – общая численность особей j-й группы, j = 1,2,…,m; m – число таксономических групп, встретившихся в каждой пробе наблюдений.Группы, как мы это уже ранее делали неоднократно, выделим по двум параллельным градациям – по систематике и трофическому признаку. Генерировать вторичные переменные в данном случае не будем.
Применим пошаговый метод включений с исключениями Эфроимсона для расчета моделей регрессии для тех гидрохимических показателей, что и в предыдущем примере. Ориентируясь на знак коэффициентов рассчитанных уравнений, представленных в табл. 8.3, можно сформулировать гипотезы об увеличении (знак “+”) или уменьшении (знак “–”) удельной доли таксономических групп в сообществе при возрастании соответствующего гидрохимического показателя. Относительную достоверность каждого предположения можно оценить по величине частных
F-критериев, с которыми отдельные признаки включались в модель (пороговое значение в этом случае было равном 2.5). Коэффициенты множественной корреляции и оценки значимости полученных уравнений с использованием статистики Фишера приведены в табл. 8.2.Таблица 8.3
Коэффициенты регрессионных моделей, связывающих гидрохимические показатели и относительную численность групп зообентоса
|
Гидро-химические показатели |
Коэффици-енты уравнения |
Наименования таксономических групп зообентоса, относительные численности которых включены в модель |
Частный F- критерий |
|
Фосфор минеральный (n = 126, m = 66) |
0.143 |
Свободный член |
- |
|
0.7 |
Сестоно-детритофаги фильтраторы / Unionidae |
21.39 |
|
|
- 0.434 |
Хищники хвататели / Tanypodinae |
17.66 |
|
|
- 0.599 |
Хищники хвататели / Limoniidae |
6.66 |
|
|
- 0.3 |
Всеядные собиратели+хвататели / Chironomini |
8.24 |
|
|
- 0.233 |
Сестоно-детритофаги фильтраторы / Bivalvia |
6.71 |
|
|
- 0.846 |
Сестоно-детритофаги фильтраторы / Gastropoda |
2.92 |
|
|
-1.38 |
Сестоно-детритофаги фильтраторы / Simuliidae |
3.67 |
|
|
- 0.77 |
Фитодетритофаги собиратели / Psychodidae |
2.93 |
|
|
Азот аммонийный (n = 90, m = 61) |
0.276 |
Свободный член |
|
|
11.422 |
Хищники хвататели / Megaloptera |
31.63 |
|
|
0.362 |
Детритофаги собиратели / Chironomini |
5.21 |
|
|
- 0. 974 |
Всеядные собиратели+хвататели / Nematoda |
6.56 |
|
|
0.461 |
Детрито-фитофаги / Tanytarsini |
4.68 |
|
|
0. 445 |
Детрито-фитофаги / Chironomini |
3.85 |
|
|
- 0. 797 |
Хищники хвататели / Tanypodinae |
6.28 |
|
|
-1. 277 |
Фитодетритофаги собиратели / Ephydridae |
5.84 |
|
|
- 0.251 |
Детритофаги собиратели / Oligochaeta |
4.72 |
|
|
- 0.445 |
Хищники хвататели / Prodiamesinae |
2.54 |
|
|
БПК 5(n = 100, m = 46) |
3.446 |
Свободный член |
|
|
37.21 |
Хищники хвататели / Megaloptera |
20.46 |
|
|
2.845 |
Детритофаги собиратели / Oligochaeta |
17.25 |
|
|
17.63 |
Всеядные собиратели+хвататели / Nematoda |
14.36 |
|
|
10.25 |
Сестоно-детритофаги фильтраторы / Chironomini |
8.77 |
|
|
3.844 |
Детрито-фитофаги / Chironomini |
10.16 |
|
|
- 4.532 |
Всеядные собиратели+хвататели / Chironomini |
4.32 |
|
|
27.46 |
Сестоно-детритофаги фильтраторы / Gastropoda |
3.91 |
|
|
Железо (n = 71, m = 58) |
0.054 |
Свободный член |
|
|
4.1 |
Детритофаги собиратели / Polychaeta |
15.35 |
|
|
1.3 |
Хищники хвататели / Prodiamesinae |
7.24 |
|
|
2.52 |
Хищники хвататели / Diamesinae |
7.39 |
|
|
1.25 |
Детрито-фитофаги / Chironomini |
7.48 |
|
|
2.67 |
Хищники хвататели / Limoniidae |
5.63 |
|
|
4.01 |
Хищники хвататели / Homoptera |
5.23 |
|
|
0.461 |
Детритофаги собиратели / Oligochaeta |
5.73 |
|
|
0.87 |
Хищники хвататели / Tanypodinae |
2.64 |
Выполненные расчеты со всей очевидностью свидетельствуют о том, что комплекс признаков, составленный из абсолютных или относительных значений обилия и представляющий все таксономические группы гидробионтов, значительно адекватнее связан с факторами среды, чем суммарные гидробиологические показатели или отдельные субъективные индексы. Впрочем, этот практический вывод лишь подтверждает естественное умозаключение: таблица численности и биомассы особей, суммированных по таксономическим группам, уже содержит в полном, хоть и неявном виде, всю информацию, содержащуюся в любом из обобщенных индексов. При этом, обратная информационная трансформация является невозможной, поскольку после расчета любого индекса значительная часть данных о структуре биоценоза становится безвозвратно потерянной.
| Дальше
|
Назад |
Начало |
Конец |
Список
|