| Дальше
|
Назад |
Начало |
Конец |
Список
|
8.2. Регрессия с
качественной зависимой переменнойФормулировка задачи
Пусть в рамках задачи множественной регрессии зависимая переменная Y принимает фиксированные значения из некоторого заранее предопределенного набора, т.е. моделируемому объекту приписывается выбор между двумя и более возможными альтернативами. В частности, модель с бинарной переменной включает отклик, принимающий два значения (обычно 0 и 1), а также регрессоры X, которые содержат факторы, определяющие альтернативный выбор.
Эта задача возникает, как правило, если моделируемый показатель измерен в порядковой шкале, которая принципиально не может быть преобразована в непрерывную числовую последовательность. Пусть, например, рассматривается оценка пола особи: мужской (0) или женский (1). Тогда построенная обычная линейная регрессия будет предсказывать абсурдные значения Y – дробные, отрицательные и больше единицы. Может быть, это как-то и интерпретируется с медицинской точки зрения, но в практике гидробиологических исследований такое будет едва ли возможно.
Для случая с качественной зависимой переменной требуется найти модель, которая порождала бы дискретное распределение E(Y | X), зависящее от X и хорошо описывающие исходные данные. Классическая модель регрессии не подходит для описания этой ситуации, поскольку предполагает, что зависимая переменная имеет непрерывное распределение.
С этой целью рассматривается логистическая регрессия, которая выражает статистическую связь в виде зависимости P{Y=1|X}=f(X), т.е. прогнозируется вероятность события {Y = 1}, обусловленная значениями независимых переменных X1,…,Xp. Геометрически суть задачи состоит в том, чтобы найти одну из возможных гиперплоскостей, которая бы в определенном смысле наилучшим образом разделяла бы две группы наблюдений (соответствующие 0 и 1) в пространстве регрессоров.
Рекомендуемая литература: [Бикел, Доксам , 1983; Справочник по прикладной.., 1989].
Математический лист
Логистическая регрессия выражает модель связи между откликом и переменными в виде формулы
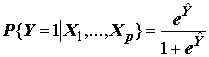 ,
, (8.16)
(8.16)
где
переменная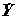 = q
0+q
1X1+…+q
pXp называется логитом. Такая модель с бинарной зависимой переменной, по сути, является функцией логистического закона распределения
= q
0+q
1X1+…+q
pXp называется логитом. Такая модель с бинарной зависимой переменной, по сути, является функцией логистического закона распределения
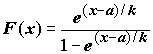 ,(8.17)
,(8.17)
в которой в качестве аргумента используется линейная комбинация независимых переменных.
Наряду с моделью, имеющей логистически распределенное отклонение, используют также близкую ей модель пробит
с нормально распределенным отклонением (см. рис 8.1).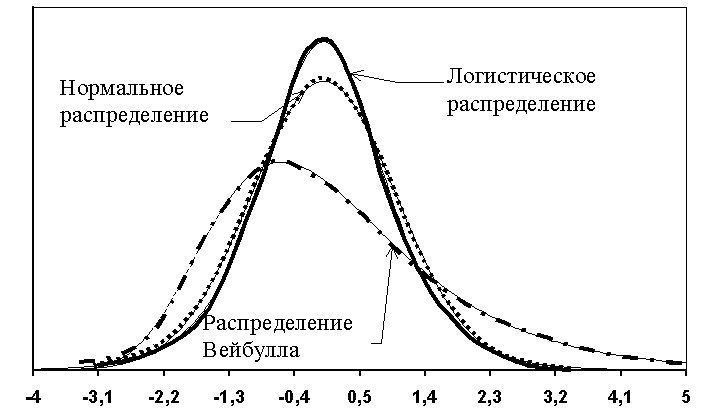
Рис 8.1. Виды распределений, используемых в логистической регрессии
Различить, когда следует применять логит, а когда – пробит, в случае малых выборок невозможно, поскольку оценки коэффициентов q
отличаются множителем, который практически постоянен.Предлагается два вида моделей выбора, которые могли бы порождать интересующие нас распределения зависимой переменной: пороговая модель и модель
, основанная на полезности альтернатив.Пороговая модель предполагает, что прогнозирование отклика основывается на ненаблюдаемой непрерывной переменной
, математическое ожидание которой является линейной комбинацией набора регрессоров X: 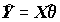 + e
. Отклик Y, являющийся дискретной величиной, связан с следующим образом: если больше некоторой пороговой величины C, то Y = 1, если меньше, то Y = 0. Как обычно предполагается, что ошибки e
i имеют нулевое математическое ожидание, одинаково распределены и независимы. Величину C обычно принимают равной 0.5. Пробит- или логит-уравнение задает задает в этом случае гиперплоскость, которой разделяются две группы точек:
+ e
. Отклик Y, являющийся дискретной величиной, связан с следующим образом: если больше некоторой пороговой величины C, то Y = 1, если меньше, то Y = 0. Как обычно предполагается, что ошибки e
i имеют нулевое математическое ожидание, одинаково распределены и независимы. Величину C обычно принимают равной 0.5. Пробит- или логит-уравнение задает задает в этом случае гиперплоскость, которой разделяются две группы точек: 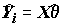 < 0.5 Þ
0 и > 0.5 Þ
1.
< 0.5 Þ
0 и > 0.5 Þ
1.
О качестве модели можно судить по графику оценки
E(Y) по, который в случае "хорошей" модели должен быть "крутой" в нуле. На двух графиках, представленных на рис. 8.2, слева внизу и справа вверху расположены правильно предсказанные точки, а слева вверху и справа внизу — неправильно.
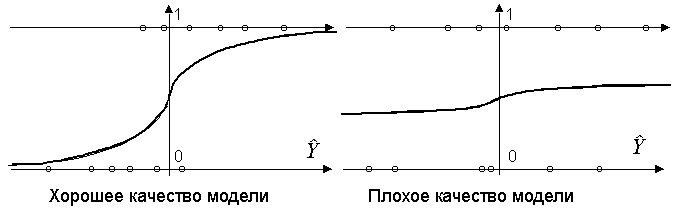
Рис. 8.2. График оценки
E(Y) по для различных моделей с бинарной зависимой переменной
Множественный
логит- или пробит-анализ являются естественным продолжением бинарного и возникают, когда рассматривается выбор между более, чем двумя альтернативами. Упорядоченный логит, развивающий пороговую модель, имеет дело с альтернативами, которые можно расположить в определенном порядке. Например, это могут быть шкала оценок класса качества вод, зоны сапробности и т.д.Будем предполагать, что альтернативы пронумерованы от 0 до S, а переменная Y принимает значение s, если выбрана альтернатива s. Как и в бинарной модели, в основе выбора лежит ненаблюдаемая величина + e
, для ранжирования которой рассчитывается s пороговых значений g
1, g
2,…,g
s. Предполагается, что Y =
0, если меньше нижнего (первого) порогового значения, Y = 1, если попадает в промежуток от первого до второго порогового значения и т. д.; Y = S выбирается, если превышает верхнее пороговое значение, т.е.:
Y
i =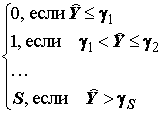 (8.18)
(8.18)
Коэффициенты пробита и логита обычно оценивают методом максимального правдоподобия, рассмотрение теоретических аспектов которого выходит за рамки нашего изложения
(подробно см. [Цыплаков, URL]). Статистика отношения правдоподобия, которая распределена асимптотически как χ2 с m –1 степенями свободы, где m – количество параметров в исходной модели, используется для построения показателя качества модели, аналогичного F-статистике для линейной регрессии, т.е. для проверки гипотезы о том, что коэффициенты при всех регрессорах, кроме константы, равны одновременно нулю. Для моделей с бинарной зависимой переменной можно сконструировать и некий аналог коэффициента детерминации — псевдо-R2: Однако для логистической регрессии, на наш взгляд, существует наиболее естественный критерий качества – вероятность ошибки при оценке прогнозируемых альтернатив. Понятно, что "хорошая" модель должна давать высокий процент правильных предсказаний.Если категории прогнозируемого отклика не упорядочены (например, сравниваются наблюдения для различных водоемов), то предполагается, что выбор делается на основе функции полезности альтернатив
u(Y, X). Для бинарной модели, если u(1, X) > u(0, X), то выбираем 1, а если u(0, X) < u(1, X), то выбираем 0. Для множественного логита Yi выбирается равным s, если us(Zi) > ut (Zi) " s ¹ t. При выборе вида функции полезности обычно делают одно из двух упрощающих допущений:us = Zs b + e
s.При этом также принимается, что ошибки e
s имеют стандартное распределение Вейбулла F (X) = e –e –X (см. рис.8.1).Результаты расчетов
Бинарная логистическая регрессия на основе показателей обилия групп
Сформируем выборку для построения бинарной логистической модели следующим образом:
Полученное уравнение логистической регрессии оказалось значимым с позиций статистики отношения правдоподобия –
χ2(50) = 225.9, p » 0.0, а коэффициент детерминации псевдо-R2 составил 33.6%. Верхняя часть списка коэффициентов регрессии, отсортированного по убыванию t-статистики, представлена в табл. 8.4. Большинство рассчитанных коэффициентов имеют отрицательный знак, т.е. чем меньше обилие гидробионтов этих семейств, тем больше шанс, что проба взята из водоема “грязной” категории. Достоверная связь обратного характера наблюдается только для организмов Oligochaeta и Odonata.Таблица 8.4
Коэффициенты логистической регрессионной модели, связывающей категорию качества вод и обилия таксономических групп зообентоса
|
Наименования таксономических групп зообентоса |
Коэффициенты логита |
Стандартная ошибка |
t -статистика |
Р -значение |
|
Ephemeroptera |
-0.291 |
0.066 |
-4.409 |
0.000 |
|
Oligochaeta |
0.147 |
0.047 |
3.120 |
0.002 |
|
Триба Tanytarsini |
-0.154 |
0.065 |
-2.373 |
0.018 |
|
Amphipoda |
-0.490 |
0.208 |
-2.352 |
0.019 |
|
Coleoptera |
-0.222 |
0.098 |
-2.267 |
0.024 |
|
Crustacea |
-0.274 |
0.124 |
-2.208 |
0.028 |
|
Odonata |
0.213 |
0.108 |
1.974 |
0.049 |
|
Gastropoda |
-0.093 |
0.061 |
-1.525 |
0.128 |
|
Diptera |
-0.329 |
0.216 |
-1.523 |
0.128 |
|
Подсемейство Diamesinae |
0.141 |
0.100 |
1.416 |
0.158 |
|
Dreissenidae |
-0.094 |
0.068 |
-1.380 |
0.168 |
|
Limoniidae |
-0.125 |
0.094 |
-1.335 |
0.183 |
|
Megaloptera |
0.142 |
0.108 |
1.318 |
0.188 |
|
Psychodidae |
-0.255 |
0.199 |
-1.282 |
0.201 |
|
Nematoda |
0.113 |
0.091 |
1.248 |
0.213 |
|
Simuliidae |
-0.135 |
0.113 |
-1.197 |
0.232 |
|
Hemiptera |
-0.131 |
0.110 |
-1.195 |
0.233 |
|
Hidracarina |
0.215 |
0.192 |
1.119 |
0.264 |
|
Rhagionidae |
-0.201 |
0.180 |
-1.118 |
0.264 |
|
Число видов в пробе S |
-0.047 |
0.044 |
-1.068 |
0.286 |
|
Триба Chironomini |
0.059 |
0.055 |
1.060 |
0.290 |
Гистограмма распределения примеров выборки по шкале прогнозируемой вероятности класса 1 (“грязно”) представлена на рис. 8.3. Если принять в качестве порогового значения Р = 0.5, то к классу “грязных” объектов относят значения
Xi , для которых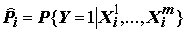 > 0.5, и тогда общая ошибка предсказания по уравнению регрессии составит менее 20%. Это правило оптимально с точки зрения минимизации числа ошибок, но не всегда верно с точки зрения исследования связи и поэтому порог зачастую сдвигают в сторону класса с минимальной априорной вероятностью встречаемости.
> 0.5, и тогда общая ошибка предсказания по уравнению регрессии составит менее 20%. Это правило оптимально с точки зрения минимизации числа ошибок, но не всегда верно с точки зрения исследования связи и поэтому порог зачастую сдвигают в сторону класса с минимальной априорной вероятностью встречаемости.

Рис. 8.3. Гистограмма распределения измерений по шкале прогнозируемой вероятности класса 1 - “грязно” (каждому символу на гистограмме соответствует около5 объектов исходной выборки)
Множественный пробит-анализ по обобщенным показателям
Используем упорядоченный пробит-анализ для непосредственной оценки значения класса качества водоемов в виде числа от 1 до 6. Сформируем выборку из тех же 520 измерений, но в качестве девяти варьируемых переменных будем использовать различные обобщенные гидробиологические показатели и традиционные "интегральные" индексы, перечисленные в табл. 8.5.
С чисто статистической точки зрения было рассчитано вполне благополучное уравнение упорядоченного пробита: критерий
χ2(9) для статистики отношения правдоподобия составил 257.1 при p @ 0.0, коэффициент детерминации псевдо-R2 равен 42.3%.Таблица 8.5
Коэффициенты модели упорядоченного пробита, связывающей класс качества вод и обобщенные показатели зообентоса
|
Наименования индексов и обобщенных показателей |
Коэффициенты пробита |
Стандартная ошибка |
t -статистика |
Р -значение |
|
1 Константа уравнения |
2.42 |
0.276 |
8.76 |
0.0 |
|
2 Индекс Шеннона |
0.1117 |
0.064 |
1.73 |
0.08 |
|
3 Число видов в пробе |
- 0.0348 |
0.0125 |
-2.78 |
0.0056 |
|
4 Общая численность (ln экз/м 2) |
0.011 |
0.044 |
0.249 |
0.803 |
|
5 Общая ,биомасса (ln мг/м 2) |
0.0056 |
0.0246 |
0.228 |
0.812 |
|
6 Доля хищных видов (численность) |
0.00108 |
0.00455 |
0.238 |
0.81 |
|
7 Доля хищных видов (биомасса) |
-0.00459 |
0.00348 |
-1.318 |
0.189 |
|
8 Биотический индекс Вудивисса |
- 0.285 |
0.0318 |
-8.958 |
0.0 |
|
9 Олигохетный индекс Пареле |
0.7679 |
0.0894 |
8.584 |
0.0 |
|
10 Хирономидный индекс Балушкиной |
0.0289 |
0.0166 |
1.738 |
0.083 |
Однако анализ уровня значимости коэффициентов пробит-уравнения, представленных в таблице 8.5, показывает, что вполне достоверно связаны с классом качества лишь число видов в пробе, биотический индекс Вудивисса (обратная зависимость) и олигохетный индекс (прямая зависимость).
Упорядоченный пробит представляет собой вероятностную модель, согласно которой попадание в группу, соответствующую каждому классу качества водоема представляет собой случайное событие. Вероятность
P(k|xi1,xi2,…,xip) принадлежности i-го измерения к k-му классу (вернее, вероятность попадания в интервал между границами классов) вычисляется по усеченному нормальному распределению, и при этом предполагается, что к расчетному значению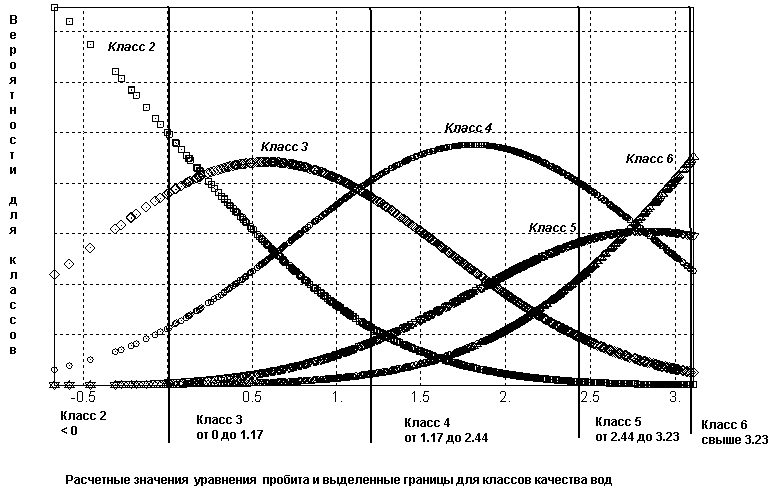
Рис. 8.4. График вероятностей прогнозирования класса качества вод и граничные значения для уравнения упорядоченного пробита
Результаты достоверности оценки классов качества представим в виде таблицы сопряженности “Факт – Прогноз” (табл. 8.6), где по главной диагонали проставлены частоты правильной оценки групп измерений, а в остальных клетках – имеющиеся ошибки оценки.
Таблица 8.6
Результаты прогнозирования класса качества вод по модели упорядоченного пробита
|
Классы качества вод |
Фактические |
Итого прогноз |
Правильный прогноз, % |
Ошибка на два и более класса, % |
|||||
|
2 |
3 |
4 |
5 |
6 |
|||||
|
Прогнозируемые |
2 |
15 |
10 |
2 |
0 |
0 |
27 |
55.56 |
7.41 |
|
3 |
26 |
53 |
38 |
5 |
0 |
122 |
43.44 |
4.1 |
|
|
4 |
11 |
61 |
139 |
56 |
45 |
312 |
44.55 |
17.95 |
|
|
5 |
0 |
0 |
0 |
0 |
0 |
0 |
- |
- |
|
|
6 |
1 |
4 |
8 |
26 |
20 |
59 |
33.90 |
22.03 |
|
|
Итого факт |
53 |
128 |
187 |
87 |
65 |
520 |
43.65 |
14.6 |
|
Качество выполненного прогноза по модели упорядоченного пробита нельзя назвать вполне удовлетворительным, особенно, в области классов загрязненных вод 5 и 6. В частности, оценка класса 5 вообще не реализуема по представленным данным наблюдений. Действительно, ни для одного из измерений кривая вероятностей, соответствующая на рис. 8.4 классу 5, не проходит выше кривых остальных вероятностей.
| Дальше
|
Назад |
Начало |
Конец |
Список
|