| Дальше
|
Назад |
Начало |
Конец |
Список
|
8.4. Задача о “классобности” видов: алгоритм распознавания, основанный на вычислении биоиндикационых индексов
Формулировка задачи
Пусть задано пространство признаков X размерностью m > 1, соответствующее некоторому списку видов гидробионтов. Точками этого пространства являются конкретные гидробиологические измерения x = {x1,…, xi,…,xm}, где xi – значение обилия i-го вида в пробе.
Как и в случае дискриминантного анализа, определены P классов {у1, у2, …, yp}, к которым могут относиться всевозможные измерения х из Х, причем содержательный смысл используемой системы классификации имеет произвольный характер, включающий любые градации сапробности, токсобности, классов качества вод, типов водоемов, природно-климатических зон и т.д.
Необходимо на основе обучающей выборки определить набор формальных решающих правил, позволяющих для произвольного измерения х из Х указать класс качества вод yk, к которому оно принадлежит.
Математический лист
Сформулируем метод классифицирования измерений x, основанный на следующих эвристических процедурах:
F(R , xr) Þ
t ,
которая обеспечивает минимум ошибок классификации для широкого набора тестовых примеров
xr.Элементы матрицы
R будем называть индикаторными валентностями (value of indication) вида i в классе k. Рассмотрим три версии расчета индикаторных валентностей и последующей классификации, основанные на следующих различных концепциях:Алгоритм 1, использующий формулы вычисления сапробных валентностей.
Как было описано в разделе 4.4, оценка зон сапробности по показательным организмам методом Зелинки и Марвана основывается на следующих предпосылках:
Поскольку метод классификации водоемов по сапробности является единственным практическим способом количественной водной биоиндикации, понятно стремление исследователей-гидробиологов, накопивших значительный массив экспедиционных данных, провести самостоятельные расчеты индикаторных валентностей с учетом региональных особенностей бентофауны, характера загрязнений и типологии водоемов. В разделе 4.4 была приведена формула расчета сапробных валентностей с использованием численности N и встречаемости Di гидробионтов в основных зонах сапробности (o-p), предложенная П.А. Цимдинем [1979]. Если сделать естественное предположение, что численность вида-индикатора представляет собой среднее значение численности для всех j измерений в k-й зоне, j = 1, 2,…, nik, то формула приобретает тривиальный вид отношения групповых средних к глобальной средней:
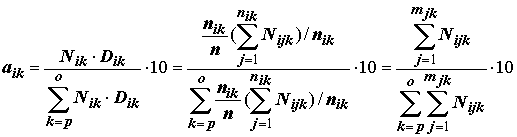 ,(8.32)
,(8.32)
где
nik – встречаемость i-го вида в k-й зоне, Dik = nik / n, n – общее число измерений.Индикаторные веса
Ji оцениваются по Сладечеку, ориентируясь на характер распределения сапробных валентностей по зонам. Например, индикаторный вес J = 5 присваивается "хорошим" индикаторам, если все 10 баллов сапробной валентности распределены в одной зоне сапробности. Если валентности равномерно распределяются по ступеням, то такие виды считаются индифферентными или "плохими" индикаторами и получают небольшой балл.Сформированные индикаторные валентности
aik используются на втором этапе для прогнозирования класса водоема по комбинации видов, встретившихся в произвольно взятой пробе. Для этого, в соответствии с методом Зелинки и Марвана, для каждой k-й зоны (k = 1, 2,…, p) вычисляются средневзвешенные валентности tk по численностям видов Ni (i = 1,…, np) экзаменуемого измерения с учетом индикаторных весов Ji: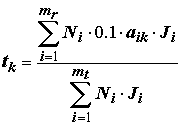 ,(8.33)
,(8.33)
где
mr – количество видов в тестируемой пробе.В предыдущих разделах нами было показано, что для вариационных рядов обилия бентосных организмов наиболее характерно логнормальное распределение, в связи с чем логарифмирование численности особей в пробе существенно нормализует распределение значений
Ni и обеспечивает корректное вычисление статистических характеристик: средней, дисперсии и проч. Поэтому альтернативными вариантами формул для aik и tk являются: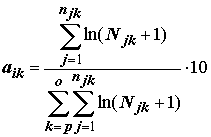 ;
; 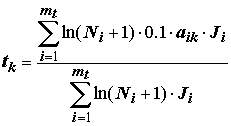 (8.34)
(8.34)
Рассчитав для тестируемого примера средневзвешенные валентности
tk, имеющие смысл оценок принадлежности пробы к классам качества вод, мы можем избрать одну из двух стратегий классифицирования.Первая стратегия – наиболее простая и традиционно рекомендуемая математической теорией распознавания образов – предлагает отнести объект к классу, набравшему максимальную оценку, что соответствует минимальному среднему риску ошибки (см., например, формулу 8.20).
Вторая стратегия основывается на аналогии с расчетом индекса сапробности Пантле-Букка. И.К. Тодерашем [1984] предложена формула пересчета средневзвешенных сапробных валентностей {
tx, tо, tb , ta , tp} в индекс сапробности по Ротшайну (см. раздел 4.4), которая имеет следующий вид:SR
= 0× tx,+ 1× tо + 2 × tb + 3× ta + 4× tp .(8.35)
По величине индекса
SR судят о принадлежности к зоне сапробности.Алгоритм 2 – оценка индикаторных индексов по частоте встречаемости
Традиционным для гидробиологии является анализ видовой встречаемости, когда для исследователя имеет значение только факт наличия вида в пробе. Такой подход, например, широко используется в кластерном анализе с использованием коэффициентов сходства по Жаккару, Съёренсену и т.п. Поэтому представляется целесообразным выполнить расчет индикаторных индексов для отдельных видов на основе частот их встречаемости в пробах различных классов.
Сформируем матрицу гидробиологических наблюдений X в альтернативной шкале измерений, положив все ее элементы равными 1, если значение численности i-го вида в j-й пробе не меньше некоторого заданного порога (Nij ³ q ), и 0 в противном случае. Эта операция позволяет нам абстрагироваться от абсолютных величин обилия видов, нестационарных по своей природе, и использовать в качестве байесовских оценок условных вероятностей более устойчивые и унифицированные значения частот встречаемости.
На первом этапе с использованием примеров обучающей выборки, для которых известны значения классов качества вод у1, у2, …, yp , сформируем:
(8.36)(8.37)
(8.38)где
n – общее количество примеров обучающей выборки;Сформированные оценки вероятностей используются на втором этапе для прогнозирования или экзамена – определения класса водоема по комбинации видов, встретившихся в произвольно взятой пробе.
Решающее правило, как и в предыдущем случае, представляет собой функциональный преобразователь, на выходе которого по априорным вероятностям и измерению
xr вычисляется вектор t результативных оценок t1, t2,…,tp. Суждение о принадлежности пробы xr к водоему k-й категории может быть вынесено, например, если tk – наибольшая оценка из t1, t2,…,tp. Простейшим вариантом расчета оценок tk является усреднение значений условных вероятностей для всех mr видов, встретившихся в тестируемом измерении: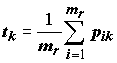 ,(8.39)
,(8.39)
т.е. вероятность принадлежности пробы к
k-му классу есть средняя вероятность класса k для всех видов, найденных в пробе.Формула "простых средних вероятностей", традиционная для многих работ в этом направлении [Джурс, Айзенауэр, 1977; Авидон с соавт., 1978], часто дает вполне удовлетворительную точность. Однако ряд теоретико-вероятностных предположений заставляют усомниться в конечной оптимальности аппроксимации первого порядка. Поэтому другим вариантом усреднения вероятностей
pik является использование известного углового преобразования Фишера [Урбах, 1964], при котором частотные оценки вероятностей имеют ошибку, почти не зависящую от самих вероятностей. Используемая при этом функция arcsin (2P - 1) ведет себя почти так же, как используемая в байесовских подходах функция ln(P/(1-P)), но, в то же время, при P, близких к 0 или 1, не вырождается, устремляясь в бесконечность, а ограничена ± p /2. На этих принципах основана работа компьютерной системы PASS [Poroikov et al., 2000], прогнозирующей спектр биологической активности химических соединений по их структурным формулам (адрес Интернет-версии: http://www.ibmh.msk.su/PASS). Тогда результирующие оценки принадлежности к классам некоторого тестируемого измерения xp выражаются через условные вероятности pik и априорные вероятности классов pk следующим образом: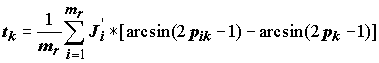 ,(8.40)
,(8.40)
где
Ji’ – индикаторный вес вида i, который мы интерпретировали как величину, обратную "шенноновской" энтропии распределения вероятностей по классам: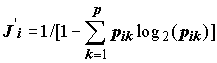 . (8.41)
. (8.41)
По нашему мнению, именно энтропия Н, а не субъективно назначаемые баллы Сладечека, в явном виде характеризует равномерность распределения индикаторных валентностей по классам.
Алгоритм 3 – расчет валентностей с использованием методов оптимизации
Сделаем основные исходные предположения относительно природы индикаторных валентностей Rik, оценивающих сродство (т.е. резистентность или экологическую значимость) i-го вида гидробионтов в k-м классе качества вод. Будем считать, что их величина является некоторой сложной математической функцией F от следующих факторов:
Rik
= F ( ni , vk, Ji, k, aik ) , (8.42)
где:
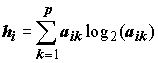 ;(8.43)
;(8.43)
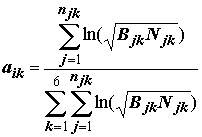 .(8.44)
.(8.44)
По аналогии с функцией желательности, примем мультипликативную модель обобщенных оценок, в которой будут учтены все пять перечисленных факторов:
Rik
= aik (ni) a (n/nk) b [3.33/(hi +1)] g k l , (8.45)
где a
, b , g и l – параметры модели, т.е. некоторые специально подобранные коэффициенты, 3.33 – константа, равная максимально возможному значению энтропии Шеннона при распределении валентностей по p классам (p = 5).Для экзамена (т.е. определения класса водоема по комбинации видов, встретившихся в произвольно взятой пробе), как и в предыдущих версиях алгоритма, будем рассчитывать оценки принадлежности к классам по следующей формуле:
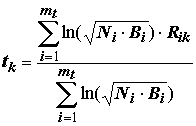 ,(8.46)
,(8.46)
и относить экзаменуемый вектор наблюдений к тому классу, которому соответствует максимальная оценка
tk из всех вычисленных.Очевидно, что значения компонентов матрицы валентностей
R, а, следовательно, и достоверность процесса распознавания, зависит от величин настроечных коэффициентов a , b , g и l , которые регулируют долю участия каждого из пяти перечисленных факторов в формировании оценок Rik. Поэтому естественна постановка следующей оптимизационной задачи: “необходимо найти такие a , b , g и l , которые сводят к минимуму число ошибок классификации при экзамене всех m примеров обучающей выборки в режиме скользящего контроля: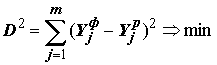 , (8.47)
, (8.47)
где
Yjф и Yjp – расчетные и фактические значения класса качества вод”.Решение этой экстремальной задачи не может быть представлено в аналитическом виде или, по крайней мере, сведено к системе конечных линейных уравнений. Поэтому минимизация функционала D2 может быть выполнена только специальными численными методами нелинейного программирования. Для нахождения оптимальных значений коэффициентов a , b , g и l воспользуемся модифицированным симплексным методом Нелдера-Мида [Банди, 1988; Гайдышев, 2001]. Этот метод, обеспечивающий достаточно быструю сходимость к экстремуму, не использует производные, что выгодно отличает его от других градиентных методов оптимизации. Основная идея симплекс-метода заключается в том, что по известным значениям целевой функции D2 в вершинах выпуклого многогранника (симплекса) вычисляется вектор градиента, в направлении которого требуется сделать следующий шаг, чтобы получить наибольшее уменьшение критерия D2. По новым точкам строится следующий симплекс и т.д., то есть, образно выражаясь, многогранник постепенно "перекатывается, двигаясь под горку" и, при этом, каждый раз находится наилучшее направление движения. Модификация Нелдера-Мида предполагает автоматическое изменение размеров ребер симплекса, что обеспечивает ему эффективное преодоление "оврагов" и быстрое движение по пологим спускам.
Результаты расчетов
Сформируем матрицу Х (n = 542 , m = 546), содержащую информацию о 542 гидробиологических пробах, взятых на малых реках Самарской области. Элементами матрицы наблюдений являются значения численностей особей по 546 видам макрозообентоса, причем, диапазон частот встречаемости различных видов варьируется от 1 до 226 (pj = nj / n = 0.00184 ¸ 0.417). Каждое измерение отнесем к одному из классов качества вод по гидрохимическим показателям от 2 до 6 (p = 5). Априорные вероятности классов pk = nk / n варьируются от 0.103 для класса 2 до 0.356 для класса 4.
Алгоритм 1.
Используем формулу П.А. Цимдиня (8.32) и методы анализа сапробных валентностей для прогнозирования класса качества воды. Индикаторные веса будем вычислять по приближенной формуле, связывающей Ji с мерой энтропии по Шеннону Н:Ji = 0.75H3 - 2.8H2 + 0.63H
+ 5 , где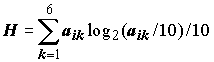 (8.48)
(8.48)
и дающей хорошую аппроксимацию весов по Сладечеку (коэффициент детерминации
R2 = 0.943).Для некоторых видов зообентоса рассчитанные значения индикаторных весов
Ji и индикаторных валентностей aik для классов качества воды (k = 2, 3, 4, 5, 6) представлены в табл. 8.12. Для первых пяти видов дана более подробная информация, позволяющая провести детальный анализ механизма расчета.Таблица 8.12
Значения индикаторных валентностей (
ak) для классов качества воды и индикаторные веса J, рассчитанные для некоторых видов зообентоса
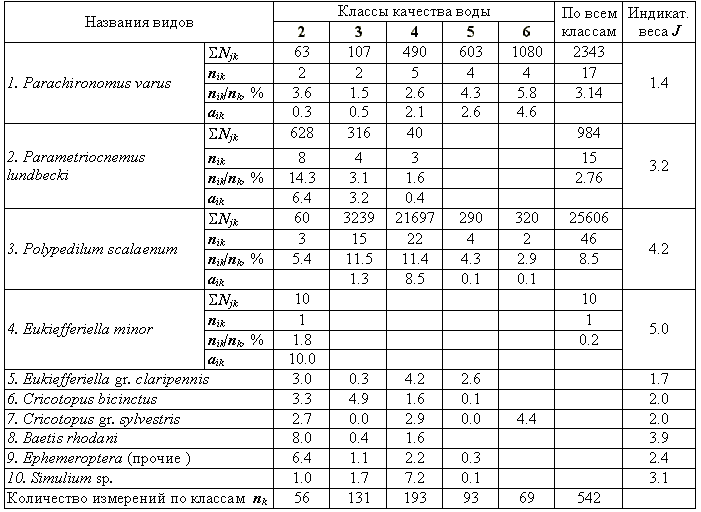
Можно отметить следующие свойства оценок
aik, вычисленных по формуле (8.32), не комментируя степень их позитивности или негативности:Рассмотрим методику классификации на примере данных, полученных на ст. 5 р. Сок (см. табл. 8.13). Индикаторные валентности и индикаторные веса для всех 7 видов зообентоса, найденных в этой пробе, указаны в табл. 8.12. Согласно данным гидрохимического анализа эта станция отнесена к 2 классу качества вод.
Таблица 8.13
Расчет по формуле (8.33) обобщенных индикаторных валентностей
tk на примере классификации данных экспедиционных наблюдений на ст. 5 р. Сок ( 30 июля 1999 г.)
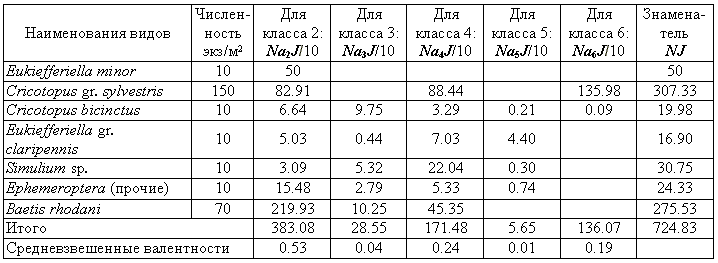
Если ориентироваться на максимальные значения обобщенных индикаторных валентностей
tk, представленные в табл. 8.13, то при экзамене безошибочно выбираются t2 = 0.53 и 2 класс качества.Чтобы использовать формулу индекса сапробности в редакции И.К. Тодераша, необходимо предварительно обозначить параллель между зонами сапробности и классами качества вод по ГОСТ 17.1.3.07–82, для чего воспользуемся табл. 4.7 раздела 4.6, где это соответствие установлено: ×
t2 = × tо для олигосапробной, t3 = tb для b -мезосапробной, t4 = ta для a -мезосапробной и × t5 = tp для полисапробной зон. Подставив рассчитанные средневзвешенные сапробные валентности в формулу (8.35), получим для станции 5 р. Сок индекс сапробности:SR
= 1× 0.53 + 2× 0.04 + 3× 0.24 + 4× 0.01 + 5× 0.19 = 2.25,согласно которому также уверенно, но уже ошибочно (!), тестируемый водоем относится к классу 3 (т.е. b -мезосапробной зоне с диапазоном индекса сапробности
SR от 1.5 до 2.5).Для проверки работоспособности метода и отдельных его модификаций проведем оценку класса качества воды для всех 542 измерений зообентоса, использованных для обучения. Расчеты проведем тремя различными методами классифицирования, приведенными в п.п. 1.1-1.3 табл. 8.14.
Таблица 8.14
Сравнительный анализ адекватности различных методов вычисления оценок индикаторных валентностей и техник распознавания
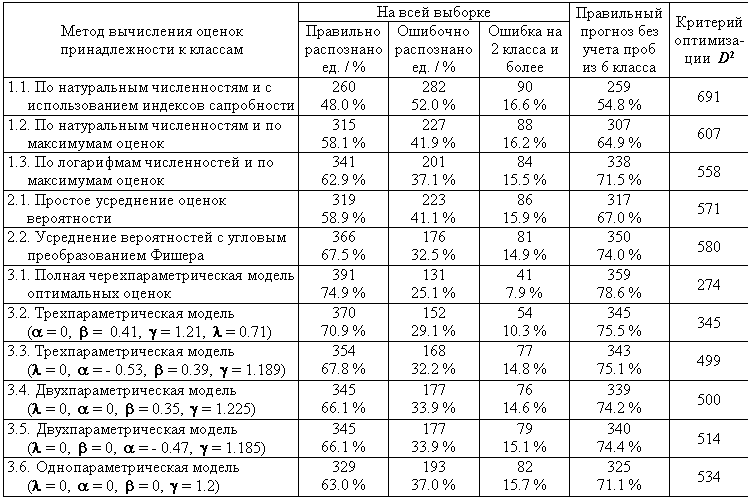
Примечение:
правильный прогноз соответствует верной оценке нужного класса качества из 5 возможных альтернатив, т.е. случайный процесс угадывания соответствует вероятности 20%.По результатам расчета можно сделать следующие выводы:
Алгоритм 2
. Используем в качестве индикаторных индексов оценки вероятности встречаемости видов. Результаты экзамена примеров обучающей выборки для двух вариантов: по формуле "простых средних вероятностей" и с использованием углового преобразования Фишера приведены в пунктах 2.1 и 2.2 табл. 8.14.Расчеты показывают, что вероятностные оценки индикаторных индексов, полученные на основе частот встречаемости видов и не учитывающие абсолютные значения численностей организмов, оказались существенно лучше оценок индикаторных валентностей, рассчитанных с использованием формулы, включающей натуральные значения численностей (пункты 1.1 и 1.2 табл. 8.14). Это – лишнее подтверждение известного тезиса о некорректности сопоставления средних значений без учета закона статистического распределения выборок.
Алгоритм 3
. Выполним расчет индикаторных валентностей, обеспечивающих минимум ошибок классификации. В качестве начальных приближений для полной моделиRik
= aik (ni)a (n/nk)b [3.33/(hi +1)]g klвыберем, по априорным соображениям, наиболее ожидаемые значения a
= 0.2, b = 0, g = 1 и l = 0.5. В ходе симплекс-процедуры по методу Нелдера-Мида было просчитано 160 вариантов матрицы R размерностью 546´ 5 и для каждого варианта найдено число ошибок классификации D2, пока, наконец, не было найдено оптимальное решение: a = - 0.52, b = 0.41, g = 1.21, l = 0.68, т.е. расчетная формула приобрела вид:Rik
= {aik (n/nk)0.41 [3.33/(hi +1)]1.21 k0.68} / ni0.52 .Значения полученных коэффициентов l
, b и g полностью подтверждают наши исходные предпосылки, в то же время как отрицательная величина коэффициента a приводит к нетрадиционному для статистики, но важному для биологии выводу о том, что основными индикаторами состояния экосистем являются редкие виды.Поскольку переусложнение расчетной модели так же вредно, как и ее недоусложнение, оценим степень вклада каждого из перечисленных выше параметров. Для этого выполним серию расчетов матрицы оптимальных оценок
R по моделям разной степени сложности: по полной четырехпараметрической модели и по упрощенным моделям, в которых поочередно элиминировались один или несколько факторов, т.е. значения параметров a , b или l априори принимался равным нулю.Полученные результаты представлены в табл. 8.14 строками 3.1-3.6. Серия расчетов с исключением из общей формулы для валентностей
R отдельных факторов дает уверенное основание полагать, что все компоненты модели (8.45) являются информативными для прогноза класса качества вод, поскольку снижение эффективности распознавания при элиминации любого из коэффициентов оказывается весьма существенным. Однопараметрическая модель оценок 3.6, учитывающая только такой фактор, как уровень доминантности индикаторных валентностей (т.е. индикаторный вес Ji в понимании Зелинки-Марвана), методически полностью соответствует модели 1.3 и отличается от нее лишь использованием комбинированного показателя обилия (N× B)0.5 вместо численности экземпляров зообентоса N.Принципиальное отличие рассчитанных индикаторных валентностей от традиционных валентностей Зелинки-Марвана заключается в том, что для последних вводится жесткое условие нормировки – сумма сапробных валентностей должна быть равна 10. Нам представляется, что введение этого условия не связано с каким-то другим содержательным смыслом, кроме стремления непременно пересчитывать оценку по валентностям во вторичные по идеологии и нерезультативные по технике индексы сапробности Пантле-Букка. Достаточно отказаться от этого условия, чтобы получить другую, гораздо более привлекательную возможность – сравнивать между собой отдельные виды по их индикаторной значимости в данной зоне сапробности или водоемах определенного класса качества. Если сопоставить для отдельных видов характер распределения вычисленных нами значений
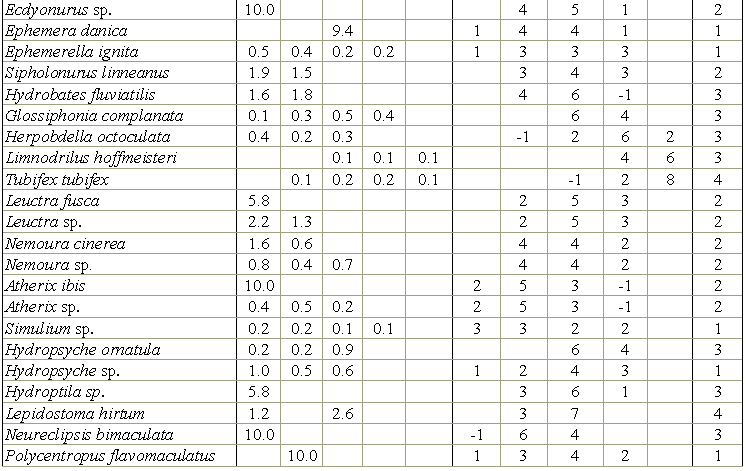
Rik по классам и сапробных валентностей, взятых из литературных источников (см. табл. 8.15) то можно усмотреть неплохое соответствие оценок для чистых водоемов, в то время как виды, объявленные классическими полисапробами, в наших региональных условиях оказались эврибионтами и не набрали высокой индикаторной значимости.Таблица 8.15
Вычисленные нами оценки валентностей для классов качества вод и сапробные валентности для некоторых видов зообентоса
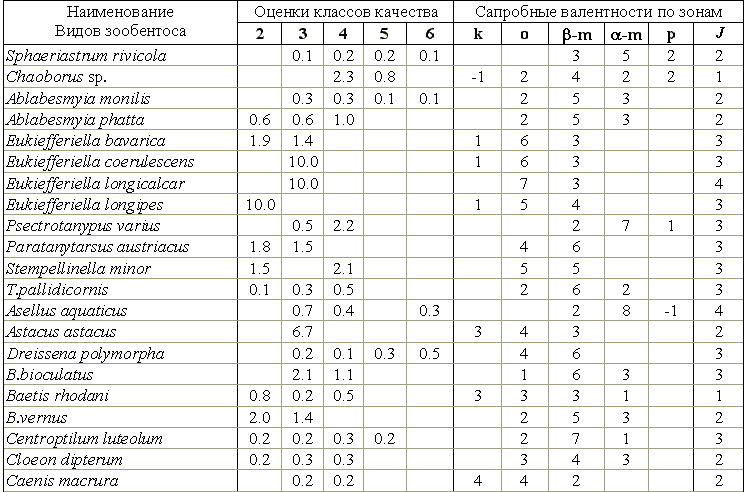
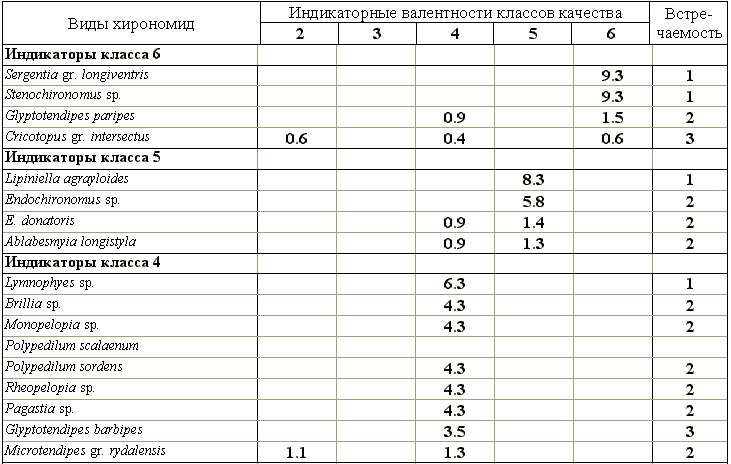
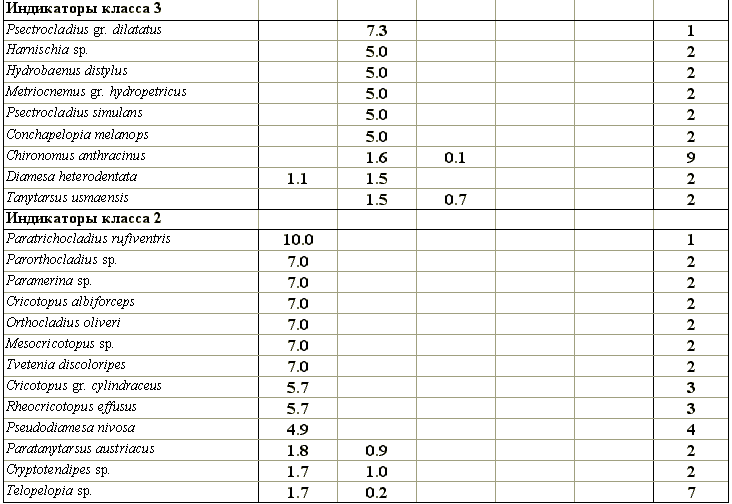
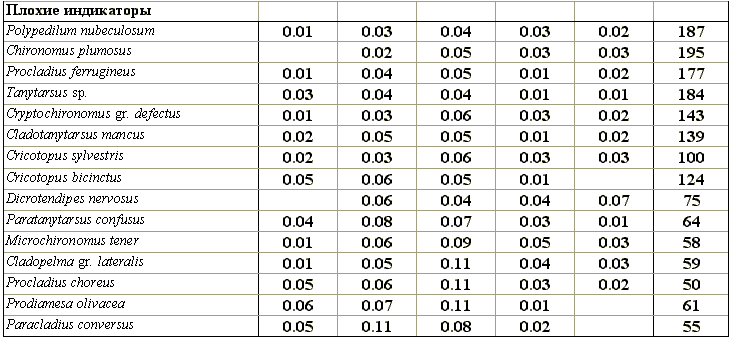
Не имея технической возможности представить полный список всех 546 видов зообентоса, приведем в табл. 8.16 индикаторные валентности для некоторых видов хирономид, сгруппировав их по отводимой им роли в отдельных классах качества вод. Нетрудно прийти к выводу, что наибольшей индикаторной значимостью обладают редко встречающиеся виды.
Таблица 8.16
Индикаторные валентности некоторых видов хирономид, характерные для отдельных классов качества воды малых и средних рек Самарской области
Доля правильной классификации качества вод, достигнутая описанными эвристическими методами распознавания с использованием видов зообентоса в качестве алфавита признаков, оказалась существенно выше, чем при аналогичных расчетах методами упорядоченного пробита и дискриминантного анализа на основе обобщенных гидробиологических индексов (см. разделы 8.2 и 8.3). В дополнение к этому, полученные результаты могут быть серьезно улучшены за счет чисто математических операций.
Во-первых, для повышения достоверности и эффективности вычисляемых индикаторных индексов необходимо предварительно провести тщательный ручной или автоматизированный отбор гидробиологических измерений для включения в обучающую выборку. Расчет индикаторных валентностей предпочтительней проводить не на всем массиве наблюдений, а на некотором "опорном" подмножестве надежных примеров, где сведены до минимума случайные ошибки измерений и влияние таких посторонних факторов, как сезонность, неудачный выбор места отбора пробы и т.д. Мы этого в нашей работе не сделали из принципиальных соображений, желая оценить общий уровень и степень влияния "шума", неизбежно сопровождающего гидробиологические измерения. Зато проведенный тщательный анализ ошибок экзамена показал, что не менее 100 проб из 542 вообще не могут быть правильно классифицированны ни компьютером, ни человеком.
Во-вторых, качество любой процедуры классификации определяет выбор информативного комплекса видов-индикаторов. Ввиду сложности гидробиологических объектов часто возникает тенденция непременно учесть в анализе все наблюдаемые виды, независимо от их реальной индикаторной значимости. Оптимальные классификационные процедуры всегда преследуют иную цель – добиться наибольшего эффекта наименьшим числом признаков, для чего большое внимание уделяется выбору наиболее информативного пространства переменных. Среди существующих способов предварительного отбора признаков можно упомянуть метод минимизации дивергенции, аппроксимацию функции распределения видового обилия в разных классах качества вод, метод максимизации кластеризуемости и т.д., о чем частично шла речь в главе 7.
В заключение затронем такую важную проблему как интерпретация и способ использования рассчитанных оценок индикаторных валентностей. По укоренившейся в гидробиологии традиции, полученные индексы рекомендуется использовать "As is" (т.е. "как они есть") для практического определения классов качества вод исследователям из других регионов. Мы полагаем, что оценки, полученные нами, работоспособны только для определенного типа водоемов (малых и средних равнинных рек) и в определенных ландшафтно-географических условиях. Неэффективность концепции "всемирных" сапробных валентностей, пригодных для водоемов любого типа или местоположения, стала очевидной еще 30 лет назад и было бы иллюзией надеяться на ее возрождение в ином информационном качестве. В то же время, развитие вычислительной техники, корпоративных баз данных и Интернет-технологий создают предпосылки для динамического формирования обучающей выборки и расчета "контекстно-зависимых" валентностей, оптимальных в условиях тестируемого комплекса измерений. В этом разделе мы ставили своей целью показать, какими математическими средствами и приемами может быть решена эта задача.
Наконец, как отмечалось выше, любая естественно-научная теория должна выполнять, как минимум, две функции: "объяснения" и "прогнозирования" наблюдаемых феноменов [Розенберг, 1988; Розенберг с соавт., 1999], причем для сложных систем объединение в одной модели этих функций невозможно. Индикаторные валентности, выборочно приведенные в табл. 8.16, были рассчитаны нами исключительно для выполнения конкретной задачи – обеспечить минимум ошибок прогноза класса качества воды и изначально не предназначались для "объяснения" (например, формирования каких-либо научных гипотез о роли того или иного вида в общей системе классификации водоемов).
| Дальше
|
Назад |
Начало |
Конец |
Список
|