| Дальше
|
Назад |
Начало |
Конец |
Список
|
Глава 9. На пути к интеллектуальным
биоиндикационным системам
9.1. Классификация наблюдений с использованием
иерархических деревьев решенийФормулировка задачи
Пусть в таблице произвольных гидробиологических наблюдений X размерностью m >1 один из признаков, измеренный в порядковой шкале, определяет класс объекта и может принимать значения из некоторого фиксированного набора {у1, у2, …, yk, …, yp}. Необходимо на основе обучающей выборки сформировать дерево классификации (дерево решений), содержащее совокупность логических условий, позволяющих для произвольного измерения х из Х указать класс качества yk , к которому оно может принадлежать.
Еще в XVII столетии великий ученый Готфрид Лейбниц ("Новые опыты о человеческом разуме", 1704 г.) пытался раскрыть тайну "Всеобщего Искусства Открытия". Он утверждал, что одной из двух частей этого искусства является комбинаторика – перебор постепенно усложняющихся комбинаций исходных данных. Второй частью является эвристика – свойство догадки человека. На языке нашего времени эта часть соответствует модели мышления человека, включающей в себя процессы генерации эвристик (догадок, изобретений, открытий).
В разделе 6.4 нами описывались простейшие детерминационные правила, как особый математический объект, восходящий к силлогистике Аристотеля, и представляющий суждение вида “Если A, то B” (или сокращенно A → B), где A, B – соответственно, объясняющий и объясняемый признаки. Например, еще Наполеон Бонапарт утверждал "Ля вибрасьен са моле гош этюн гранд синь!" (“Дрожание моей левой икры – есть великий признак”, цит. по проф. Выбегалло). Но, поскольку любая связь такого рода вероятностна, то подобный диагноз не должен основываться на одном суждении. Так дрожание перед Аустерлицем не означает, что с тем же постоянством икра дрожала и перед Йеной (ошибка диагноза 1 рода). И совсем уж непонятно, почему она дрожала перед Ватерлоо (ошибка диагноза 2 рода).
В разделе 8.6 был описан алгоритм "Кора", где непротиворечивые логические высказывания формировались как коньюнкции подмножеств бинарных признаков. Универсальным методом поиска подобных решений является метод полного перебора и, обладай мы бесконечным запасом времени и ресурсов, то можно найти решение любой задачи. Здесь имеется в виду не конструирование нового знания, а, прежде всего, "выбор" наиболее правдоподобных вариантов. Можно отметить другой универсальный метод ускорения полного перебора — быстрое отсечение ложных (или вероятно ложных) ветвей перебора на основе использования алгебр логики.
Простейшие (одномерные) логические правила типа "если A, то В" мы рассматривали в разделе 6.4, когда описывали детерминационный анализ. Более широкие возможности предоставляют системы анализа на основе деревьев решений (Tree Analyzer), которые позволяют свести исходную матрицу данных X к набору простых правил, представленных в виде иерархической структуры – дерева. Этот метод моделирования сочетает мощный аналитический аппарат генерации решений с простотой использования технологии и интуитивно понятными конечными результатами.
Рекомендуемая литература: [Breiman et al., 1984; Коршунов, 1995; Loh, Shih, 1997; Деревья классификации.., URL]. Интересные методические материалы и Интернет-конференция по теме находятся также на сайте лаборатории BaseGroup Labs – http://www.basegroup.ru.
Математический лист
Деревья решений – один из методов автоматического анализа данных, основные идеи которого восходят к работам П. Ховленда (Р. Hoveland) и Е. Ханта (Е. Hunt) конца 50-х годов XX в. Их итогом явилась основополагающая монография [Hunt et al., 1966], давшая импульс развитию этого направления.
Построение деревьев классификации – один из наиболее важных приемов, используемых при проведении "добычи данных и разведывательного анализа" (Data Mining), реализуемый как совокупность методов аналитической обработки больших массивов информации с целью выявить в них значимые закономерности и/или систематические связи между предикторными переменными, которые затем можно применить к новым совокупностям измерений.
Деревья решений представляют собой последовательные иерархические структуры, состоящие из узлов, которые содержат правила, т.е. логические конструкции вида "если … то …". Конечными узлами дерева являются "листья", соответствующие найденным решениям и объединяющие некоторое количество объектов классифицируемой выборки. Это похоже на то, как положение листа на дереве можно задать, указав ведущую к нему последовательность ветвей, начиная от корня и кончая самой последней веточкой, на которой лист растет.
Есть целый ряд причин, делающих деревья классификации более гибким средством, чем традиционные методы анализа:
Область применения деревья решений в настоящее время широка, но все задачи, решаемые этим методом, могут быть объединены в три следующие группы:
На сегодняшний день существует значительное число алгоритмов, реализующих построение деревьев решений, из которых наибольшее распространение и популярность получили следующие:
Основная идея построения деревьев решений из некоторого обучающего множества Х, сформулированная в интерпретации Р. Куинлена, состоит в следующем.
Пусть в некотором узле дерева сконцентрировано некоторое множество примеров Х*, Х*Ì Х. Тогда существуют три возможные ситуации.
Описанная процедура построения дерева решений сверху вниз, называемая схемой "разделения и захвата" (divide and conquer), лежит в основе многих современных методов построения деревьев решений. Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction).
При построении алгоритмов индукции деревьев решений особое внимание уделяется следующим ключевым вопросам:
Правило разбиения: каким образом следует выбрать признак?
Для построения дерева c одномерным ветвлением, находясь на каждом внутреннем узле, необходимо найти такое условие проверки, связанное с одной из переменных j, которое бы разбивало множество, ассоциированное с этим узлом на подмножества. Общее правило для выбора опорного признака можно сформулировать следующим образом: “выбранный признак должен разбить множество Х* так, чтобы получаемые в итоге подмножества Х*k , k = 1, 2, …, p, состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество чужеродных объектов из других классов в каждом из этих множеств было как можно меньше”.
Были разработаны различные критерии, например, теоретико-информационный критерий, предложенный Р. Куинленом:
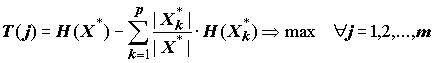 ,
, (9.1)
(9.1)
где
H(Х*) и H(Х*k ) – энтропия подмножеств, разбитых на классы, рассчитанная по формуле Шеннона.Алгоритм CART использует, так называемый, индекс Джини (в честь итальянского экономиста Corrado Gini), который оценивает "расстояние" между распределениями классов
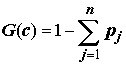 , (9.2)
, (9.2)
где
c – текущий узел, а pj – вероятность класса j в узле c.Большинство из известных алгоритмов являются "жадными алгоритмами": если один раз был выбран атрибут и по нему произведено разбиение на подмножества, то алгоритм не может вернуться назад и выбрать другой атрибут, который дал бы лучшее разбиение. И поэтому на этапе построения дерева нельзя сказать даст ли выбранный атрибут, в конечном итоге, оптимальное разбиение.
Правило остановки: разбивать дальше узел или отметить его как лист?
В дополнение к основному методу построения деревьев решений были предложены следующие правила:
Этот список эвристических правил можно продолжить, но на сегодняшний день не существует таких, которые имели бы глобальную практическую ценность. Многие из них применимы в каких-то частных случаях и, поэтому, к их использованию следует подходить с достаточной осторожностью.
Правило отсечения: каким образом ветви дерева должны отсекаться?
Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые имеют много узлов и ветвей. Такие "ветвистые" деревья очень трудно понять, а ценность правила, справедливого скажем для 1-3 объектов, крайне низка и в целях анализа данных практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, не вполне идеально классифицирующее обучающую выборку, но обладающее способностью столь же хорошо прогнозировать результат для тестовой выборки
.К сожалению, достаточно непросто конкретно определить, что же такое дерево классификации "подходящего размера", кроме общего тезиса о том, что оно должно уметь использовать ту информацию, которая улучшает точность прогноза, и игнорировать ту информацию, которая прогноза не улучшает. Для решения вышеописанной проблемы часто применяется так называемое "отсечение ветвей" (pruning), которое происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом. Если под точностью дерева решений понимается отношение правильно классифицированных объектов, то нужно отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки.
Классификация новых примеров
После индукции дерева решений его можно использовать для распознавания класса нового объекта. Обход дерева решений начинается с корня дерева. На каждом внутреннем узле проверяется значение объекта Xт по атрибуту, который соответствует алгоритму проверки в данном узле, и, в зависимости от полученного ответа, находится соответствующее ветвление, и по этой дуге осуществляется движение к узлу, находящему на уровень ниже и т.д. Обход дерева заканчивается, как только встретится узел решения, который и дает название класса объекта Xт.
Результаты расчетов
Сформируем обучающую выборку, состоящую из 117 наблюдений, признаками которой являются значения индексов Вудивисса, Шеннона, Пареле, Балушкиной, а также число видов в пробе, средние значения численности и биомассы, концентрация минерального фосфора и тип водоема (значения от 1 до 5 в зависимости от ширины русла и скорости течения). В качестве целевой переменной будем использовать класс качества вод от 2 до 6.
Получим два дерева решений: "компактное" дерево с использованием жестких процедур отсечения ветвей и упрощения правил и "полное" дерево, где единственным условием было концентрация в одном узле не менее 2 примеров обучающей выборки. "Компактное" дерево, представленное на рис. 9.1, состоит только из 8 узлов, в основе логических правил которых лежит всего 3 исходных признаков из 9.

Рис. 9.1. Дерево решений, построенное для классификации качества вод с использованием
процедур отсечения ветвей и упрощения.В частности, двигаясь от корня, мы, вместе с 7 измерениями попадаем в узел B, если индекс Вудивисса больше 6.75, либо, в противном случае, с остальными измерениями поступаем в узел А. Из узла B, используя дополнительное условие по типу водоема, осуществляется переход на два листа C и D. Двигаясь же по основной ветви от узла А мы, в конце концов, приходим к узлу G, где сосредотачиваются все плохо распознаваемые примеры в количестве 63 измерений. Всем этим объектам присваивается класс 4, причем в 44 случаях это было выполнено ошибочно. Таким образом, исполнив свою объясняющую роль интерпретации существенных факторов, "компактное" дерево показало посредственные результаты в прогнозировании (38.4% ошибок).
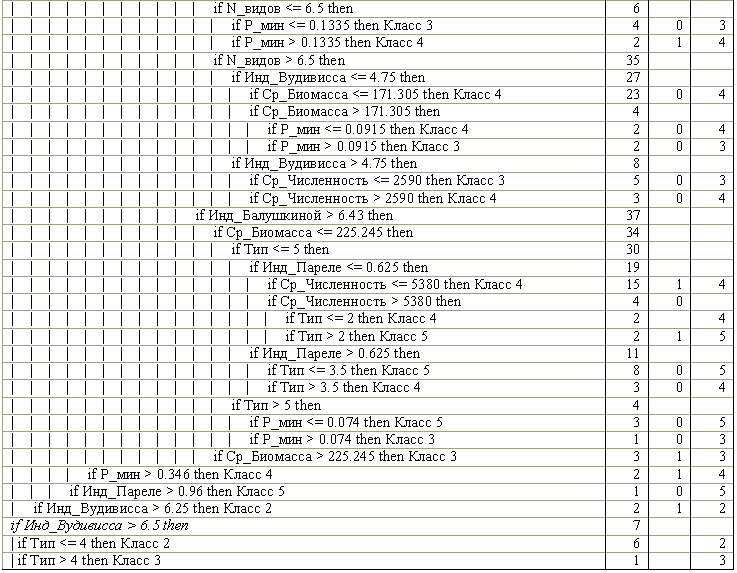
Полное дерево, построенное без применения излишне жестких мер по обрезанию ветвей, использует все 9 предикторных переменных и гораздо сложнее в интерпретации, поскольку состоит из 54 узлов, из которых 28 являются "листьями" (см. табл. 9.1). Однако громоздкость сформированных правил компенсируется великолепными интерполяционными свойствами: на обучающей выборке зафиксировано только 9 ошибок классификации, что составляет 7.6%.
Таблица 9.1
Дерево решений, построенное для классификации качества вод без использования
процедур отсечения ветвей и упрощения
| Дальше
|
Назад |
Начало |
Конец |
Список
|