| Дальше
|
Назад |
Начало |
Конец |
Список
|
9.2. Генетический алгоритм селекции информативных переменных
Формулировка задачи
Пусть для решения произвольной задачи регрессии или классификации имеется множество измерений в пространстве варьируемых переменных размерностью m > 1. Необходимо заданный набор признаков разбить на две категории: информативные переменные, существенные для решения поставленной задачи, и незначимые переменные, несущие мало дополнительной информации для нахождения искомой зависимости.
Важным условием применения любых статистических методов является объективно существующая связь между известными входными значениями и неизвестным откликом. Эта связь может носить случайный характер, искажена шумом, но она должна существовать. Известный афоризм “garbage in, garbage out” (“мусор на входе – мусор на выходе”) нигде не справедлив в такой степени, как при использовании методов самоорганизации и нейросетевого моделирования. Это объясняется, во-первых, тем, что итерационные алгоритмы направленного перебора комбинаций параметров нейросети оказываются весьма эффективными и очень быстрыми лишь при хорошем качестве исходных данных. Однако, если это условие не соблюдается, число итераций быстро растет и вычислительная сложность оказывается сопоставимой с экспоненциальной сложностью алгоритмов полного перебора возможных состояний. Во-вторых, сеть склонна обучаться, прежде всего, тому, чему проще всего обучиться, а, в условиях сильной неопределенности и зашумленности признаков, это – прежде всего артефакты и явления "ложной корреляции".
Отбор информативных переменных в традиционной регрессии и таксономии осуществляют путем "взвешивания" признаков с использованием различных статистических критериев. Так в главе 8 нами были описаны пошаговые процедуры, основанные, в той или иной форме, на анализе коэффициентов частных корреляций или ковариаций. Однако трудность проблемы формирования наиболее информативного подмножества признаков обусловлена тем, что после отбрасывания одного признака соотношение значимостей остальных анализируемых переменных в общем случае изменяется. Прямой путь решения этой задачи заключается в полном переборе всех Сmm-p сочетаний переменных, что требует гигантского объема вычислений. Поэтому для этих целей используют различные секвенциальные (последовательные) процедуры, не всегда приводящие к результату, достаточно близкому к оптимальному. Элегантный автоматизированный подход к выбору значимых входных переменных может быть реализован с использованием генетического алгоритма, который можно считать "интеллектуальной" формой метода проб и ошибок.
Рекомендуемая литература: [Goldberg, 1989; Скурихин, 1995; Васильев, Ильясов, 1999].
Математический лист
Генетический алгоритм, позаимствованный у природных аналогов, является наиболее ярким представителем эволюционных методов (см. раздел 2.8) и представляет собой мощное поисковое средство, эффективное в различных проблемных областях.
Принципы эволюционной теории, заложенные Чарльзом Дарвиным в работе "Происхождение видов", сводятся к двум основным выводам:
Именно эти принципы отбора наилучших объектов являются ключевой эвристикой всех эволюционных математических методов, позволяющих зачастую уменьшить время поиска решения на несколько порядков по сравнению со случайным поиском. Механизм естественного отбора связывается здесь с некоторой функцией оптимальности 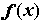 , определяющей сравнительную ценность произвольного варианта, а изменчивость привносится путем специальных модификаций фрагментов бинарного кода.
, определяющей сравнительную ценность произвольного варианта, а изменчивость привносится путем специальных модификаций фрагментов бинарного кода.
Генетический алгоритм был разработан Дж. Холландом (J. Holland) в 1975 г. в Мичиганском университете. В дальнейшем Д. Голдберг (D. Goldberg) выдвинул ряд гипотез и теорий, помогающих глубже понять природу эволюции, а К. ДеДжонг (C. DeJong) предложил оптимальный вариант подбора параметров алгоритма для повышения общей эффективности работы.
Канонический генетический алгоритм характеризуется следующими особенностями.
, определяющая эффективность каждой найденной комбинации признаков. Формируемое решение кодируется как вектор х, который называется "хромосомой" и соответствует битовой маске, т.е. двоичному представлению набора исходных переменных. В хромосоме выделяются части вектора – "гены", изменяющие свои значения в определенных позициях – "аллелях". 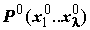 потенциальных решений – совокупность решений на конкретной итерации, состоящая из некоторого количества хромосом
потенциальных решений – совокупность решений на конкретной итерации, состоящая из некоторого количества хромосом  , число которых задаётся изначально и в процессе перебора обычно не изменяется.
в популяции декодируется в форму, необходимую для последующей оценки, и ей присваивается значение эффективности m
(xi) в соответствии с вычисленной функцией оптимальности. Кроме того, каждой хромосоме присваивается вероятность воспроизведения P(xi), i = 1,...,, которая зависит от эффективности данной хромосомы. Существуют различные схемы отбора, самая популярная из них – пропорциональный отбор:
, число которых задаётся изначально и в процессе перебора обычно не изменяется.
в популяции декодируется в форму, необходимую для последующей оценки, и ей присваивается значение эффективности m
(xi) в соответствии с вычисленной функцией оптимальности. Кроме того, каждой хромосоме присваивается вероятность воспроизведения P(xi), i = 1,...,, которая зависит от эффективности данной хромосомы. Существуют различные схемы отбора, самая популярная из них – пропорциональный отбор:
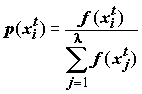 .
. (9.3)
(9.3)
Операция воспроизведения на шаге 4
служит для создания следующей популяции на основе предыдущей при помощи операторов кроссинговера и мутации, которые имеют случайный характер. Каждой хромосоме промежуточной популяции Xti в случае необходимости подбирается партнёр и созданная хромосома помещается в результирующую популяцию.Оператор кроссинговера
производит скрещивание хромосом и обмен генетическим материалом между родителями для получения потомков. Этот оператор служит для исследования новых областей пространства и улучшения существующих (эволюционное приспособление). Простейший одноточечный кроссинговер производит обмен частями, на которые хромосома разбивается точкой кроссинговера, выбираемой случайно.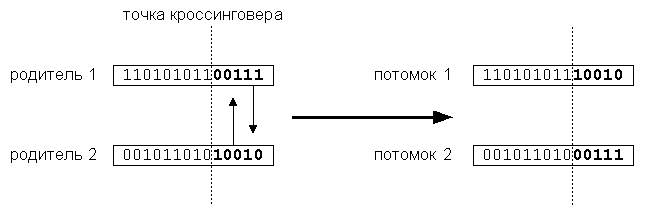
Двухточечный кроссинговер обменивает кусок строки, попавшей между двумя точками. Предельным случаем является равномерный кроссинговер, в результате которого все биты хромосом обмениваются с некоторой вероятностью.
Оператор
мутации применяется к каждому биту хромосомы с небольшой вероятностью (pi » 0.001), в результате чего бит (аллель) изменяет значение на противоположный.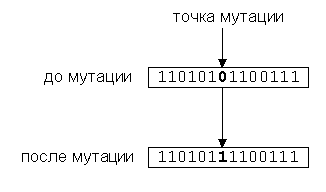
Мутация нужна для расширения пространства поиска ("эволюционное исследование") и предотвращения невосстановимой потери бит в аллелях
.Существует также оператор воспроизведения, называемый “инверсией”, который заключается в реверсировании аллелей между двумя случайными позициями, однако для большинства задач он не имеет практического смысла и поэтому мало эффективен
.Для исследования эффективности генетических алгоритмов используется понятие “шаблона
”. Шаблоны представляют собой гиперплоскости различной размерности в l-мерном пространстве и определяются с помощью элементов множества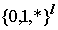 , где l – длина хромосомы в битах, * – в данной позиции может быть любой бит. Генетический алгоритм обрабатывает шаблоны, и производит выборку значительного числа гиперплоскостей из областей с высокой приспособленностью, причем в течение одного поколения популяции оценивается
, где l – длина хромосомы в битах, * – в данной позиции может быть любой бит. Генетический алгоритм обрабатывает шаблоны, и производит выборку значительного числа гиперплоскостей из областей с высокой приспособленностью, причем в течение одного поколения популяции оценивается 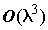 структур. Это и отличает эволюционные процессы от различных эвристических и случайно-поисковых методов, в которых единственное решение развивается само по себе, а предыдущий опыт не используется.
структур. Это и отличает эволюционные процессы от различных эвристических и случайно-поисковых методов, в которых единственное решение развивается само по себе, а предыдущий опыт не используется.
Решение, получаемое при помощи генетического алгоритма, по своему характеру субоптимально, но это не мешает применять метод для поиска глобальных экстремумов в широком классе задач оптимизации многоэкстремальных функций.
Результаты расчетов
Используем для последующего анализа выборку из 520 измерений, где в качестве варьируемых переменных представлены общее число видов X1 = N и показатели обилия отдельных таксонов зообентоса (для хирономид – подсемейств и триб); Xj = ln((NsjBsj)0.5), Nsj и Bsj – суммарные по видам численность и биомасса j-й таксономической группы в пробе, j = 2, 3, …, 51. В предыдущей главе эта выборка уже использовалась нами при описании логистической регрессии и дискриминантного анализа (см. разделы 8.2 и 8.3). В качестве прогнозируемого отклика была взята категория качества воды в альтернативной шкале “Чисто” (2 и 3 класс) / “Грязно” (4 – 6 класс).
Функцию оптимальности получаемых решений определим как статистику, связанную с качеством прогноза отклика на примерах обучающей выборки и полученную с помощью моделей вероятностных и обобщенно-регрессионных нейронных сетей. Сети этих типов выбраны потому, что для них общее время обучения и оценки относительно мало. Кроме того, эти сети очень сильно страдают от присутствия неинформативных входных переменных, а потому являются хорошим детекторами их обнаружения.
Выполним экзамен большого числа комбинаций входных переменных с помощью функции описанного типа. Каждый возможный вариант набора входных переменных можно представить в виде битовой маски по одному биту на каждую переменную (см. табл. 9.2). Ноль в соответствующей позиции означает, что эта исходная переменная не включена во входной набор, а единицы соответствуют базовому набору признаков. Начальная популяция хромосом на итерации 1 была сформирована нами случайным образом, хотя для этого возможно использование специальных простых правил.
Таблица 9.2
Результаты эволюционного процесса формирования информативного набора переменных с использованием генетического алгоритма (m (xi) – оценка эффективности хромосомы)
|
№ итераций |
m (xi) |
Битовые маски хромосом |
|
1 |
2.0001 |
10000011011001011010100111010010110100010001011110 |
|
2 |
2.0093 |
11101010010110010100000101100001110010110010011010 |
|
3 |
2.0049 |
10010101100100010011110111001111111110001001101011 |
|
4 |
2.0124 |
11100000110011000100011101010010110000010001011110 |
|
5 |
2.0154 |
11000111001101101101101111010010110101010001010110 |
|
6 |
2.0076 |
00011010010110010100010101100001110010111011000111 |
|
7 |
2.0078 |
00011010010111010100010101100001110010010010000111 |
|
… |
… |
… |
|
97 |
2.0063 |
10010011101100010001101011110110111000001101100011 |
|
98 |
2.0070 |
10111001110101000100101001001001000101001101110010 |
|
99 |
2.0149 |
10111001101100000100101001001001000101101001000010 |
|
100 |
2.0042 |
01111000111100000110001101000010111101101001000010 |
|
Наилучшее найденное решение: |
||
|
2.0450 |
11011010111111100010001001110000110101101110101010 |
|
Емкость популяции индивидуумов в нашем случае была установлена l = 100, а процесс эволюции продолжался на протяжении 100 поколений (т.е. цикл отбор-порождение-оценка был повторен 100 раз и при этом построено и оценено 10000 версий нейронных сетей). Генетический алгоритм в поисках оптимального набора генов следил за популяциями хромосом, оценивая эффективность m
(xi) каждой из них с помощью стандартного отклонения от регрессии при обучении обобщенно-регрессионной нейронной сети одинаковой конфигурации с коэффициентом сглаживания, равном 0.3. По значениям ошибки производился отбор лучших вариантов масок, которые комбинировали друг с другом с помощью искусственных генетических операций скрещивания и мутаций, интенсивностью которых можно было управлять (скорость мутации была выбрана 1, а скорость скрещивания – 0.3).В соответствии с найденным наилучшим решением, все подмножеств видов зообентоса можно разбить на две примерно равные категории: 27 групп информативных индикаторов качества воды (первые три уровня в табл. 9.3) и 22 группы организмов, малозначимых для нейросетевого моделирования (в той же таблице внизу). Следует еще раз подчеркнуть, что отнесение какого-либо класса или семейства к малоинформативной категории вовсе не означает отсутствие фактической биологической зависимости обилия организмов этого таксона от уровня загрязнения. Это может быть, например, объяснено его сильной корреляцией с какой-либо другой значащей группой, вследствие чего пришлось пожертвовать одним из таксонов, объявив его малоценным для статистической обработки.
Иногда бывает полезно уменьшить размерность задачи даже ценой некоторой потери точности, поскольку это повышает иллюстративность и улучшает способность нейросетевой модели к обобщению. Можно создать дополнительный стимул к исключению лишних переменных, назначив специальный штраф за элемент. Это число будет умножаться на количество элементов и результат будет прибавляться к уровню ошибки при оценке качества сети. Назначим штраф за элемент, равный 0.002, и повторим эволюционный процесс. В этих условиях из 50 исходных переменных будет отобрано в качестве информативных только четыре признака, представленных первыми двумя уровнями в табл. 9.3: обилие семейств Ephemeroptera, Oligochaeta, а также подсемейства Orthocladiinae и трибы Tanytarsini семейства Chironomidae. Если же увеличить штраф за элемент до 0.005, то выбирается только один значимый признак – обилие организмов семейства Ephemer
optera. Таким образом, варьируя параметрами генетического алгоритма можно эшелонировать весь список переменных по уровню их связи с целевой функцией, что и нашло свое отражение в табл. 9.3.Таблица 9.3
Результаты селекции информативного набора переменных с использованием генетического алгоритма
|
Уровень информативности |
Таксономические группы зообентоса |
|
Наилучшие биоиндикаторы |
Ephemeroptera |
|
Хорошие биоиндикаторы |
Oligochaeta, Chironomidae (подсемейство Orthocladiinae и триба Tanytarsini) |
|
Информативные группы |
Amphipoda, Bivalvia, Chaoboridae, Ceratopogonidae, Coleoptera, Dermaptera, Dreissenidae, Gastropoda, Hidracarina, Limoniidae, Megaloptera, Nematoda, Odonata, Plecoptera, Polychaeta, Psychodidae, Ptychopteridae, Simuliidae, Tabanidae, Trichoptera, C hironomidae (подсемейства Diamesinae, Prodiamesinae, Tanypodinae и триба Chironomini) |
|
Группы, незначимые для прогноза качества воды |
Arachnoidae, Collembola, Crustacea, Culicidae, Cylindrotomidae, Diptera, Dolichopodidae, Diplura, Dixidae, Ephydridae, Hemiptera, Hirudinea, Homoptera, Hydrida, Muscidae, Nematocera, Rhagionidae, Stratiomyidae, Tipulidae, Unionidae |
| Дальше
|
Назад |
Начало |
Конец |
Список
|