| Дальше
|
Назад |
Начало |
Конец |
Список
|
9.4. Нейросетевое моделирование: многослойный персептрон
Формулировка задачи
Пусть в таблице произвольных гидробиологических наблюдений X размерностью m >1 один из признаков, измеренный в порядковой шкале, определяет класс объекта и может принимать значения из некоторого фиксированного набора {у1, у2, …, yk, …, yp}.
Необходимо, используя таблицу Х, как обучающую выборку, решить общую задачу распознавания образов, т.е. разработать модель предсказания для произвольного объекта значения целевого признака, выраженного в порядковой шкале или шкале наименований.
В предыдущих главах мы неоднократно обращались к поставленной задаче, решая ее методами регрессионного и дискриминантного анализа (разделы 8.2 - 8.3), с использованием эвристических и линейных алгоритмов распознавания (разделы 8.4 - 8.5), а также на основе иерархических деревьев решений (раздел 9.1). При этом неоднократно отмечалось, что традиционная параметрическая статистика требует для адекватного прогноза либо очень большого объема известных данных, либо очень сильных предположений о виде функций распределения. Поэтому естественным является желание иметь единую парадигму построения различных эмпирических моделей, решающих задачи предсказания и классификации, которая бы удовлетворяла следующим условиям:
Как отмечалось в разделе 2.8, большинству перечисленных требований удовлетворяет подход, основанный на применении искусственных нейронных сетей (ИНС).
Рекомендуемая литература: [Горбань, 1990, 1998а,б; Уоссермен, 1992; Горбань, Россиев, 1996; Васильев с соавт., 1997; Царегородцев, Погребная, 1998; Дьяконов, Круглов, 2001; Нейронные сети.., 2001].
Математический лист
Структура искусственного нейрона
Многие современные НС сконструированы из формальных нейронов, отдалённо напоминающих свой биологический прототип. Структура нейрона имеет вид, представленный на рис. 9.2, при следующих обозначениях:
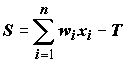 ;
; (9.11)
(9.11)
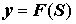 .(9.12)
.(9.12)
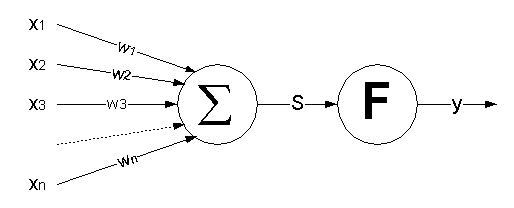
Рис. 9.2 Структура искусственного нейрона
Вид функции активации может иметь различное математическое выражение, выбор которого определяется характером решаемых задач. Например, функция активации может быть:
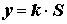 ;(9.13)
;(9.13)
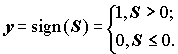
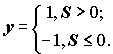 ;(9.14)
;(9.14)
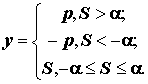 ;(9.15)
;(9.15)
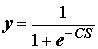 , (9.16)
, (9.16)
где С
> 0 – коэффициент ширины сигмоиды по оси абсцисс: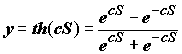 ;(9.17)
;(9.17)
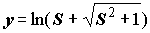 (9.18)
(9.18)
(данная функция характерна тем, что имеет диапазон
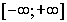 с точкой перегиба в начале координат, усиливает очень слабые сигналы и ослабляет очень сильные);
с точкой перегиба в начале координат, усиливает очень слабые сигналы и ослабляет очень сильные);
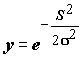 , (9.19)
, (9.19)
где
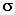 – среднеквадратичное отклонение нормального распределения, характеризующее ширину функции, S в этом случае определяется как расстояние между входным и весовым вектором:
– среднеквадратичное отклонение нормального распределения, характеризующее ширину функции, S в этом случае определяется как расстояние между входным и весовым вектором: 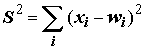 .
.
Вид некоторых функций активации представлен на рис. 9.3.
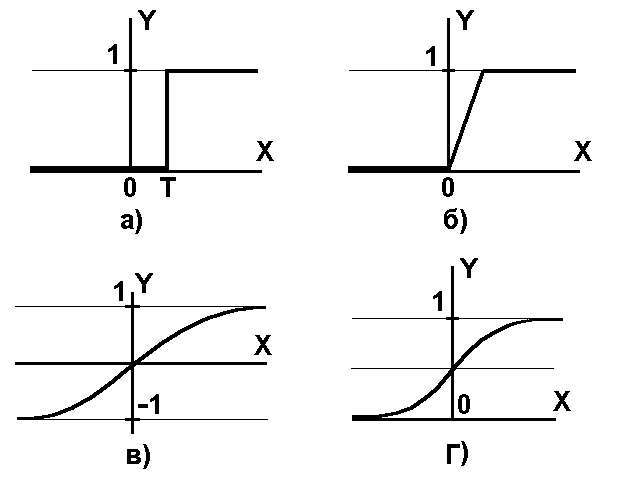
Рис. 9.3. Вид функций активации: а) функция единичного скачка; б) линейный порог (гистерезис); в) гиперболический тангенс; г) сигмоид
Одной из наиболее распространенных функций активации является нелинейная функция с насыщением - так называемая логистическая функция или сигмоид (9.16). При уменьшении коэффициента С сигмоид становится более пологим, вырождаясь в пределе при С = 0 в горизонтальную линию на уровне 0.5. При увеличении С сигмоид приближается по внешнему виду к функции единичного скачка с порогом T в точке x = 0.
Из выражения для сигмоида очевидно, что выходное значение нейрона лежит в диапазоне [0,1].
Популярность сигмоидной функции определяют следующие ее ценные свойства:
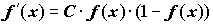 , (9.20)
, (9.20)
что дает возможность использовать широкий спектр оптимизационных алгоритмов.
Следует также отметить существование других типов формальных нейронов (сигма-пи нейроны и стохастические нейроны, нейроны с поправочным блоком), учитывающих другие свойства биологического прототипа. Наиболее интересны голографические нейроны, используемые в голографической парадигме ИНС.
Структура многослойного персептрона
Теоретическое обоснование нейросетевого моделирования базируется на теореме А.Н.Колмогорова, доказавшего, что любую непрерывную многомерную функцию на единичном отрезке [0;1] можно представить в виде конечного числа одномерных [Головко, 1999]:
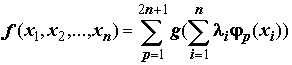 ,
,
где
g и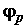 непрерывные и одномерные функции,
непрерывные и одномерные функции, 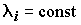 . Отсюда с помощью любой многослойной ИНС всего с двумя перерабатывающими слоями можно с любой точностью аппроксимировать любую многомерную функцию на единичном отрезке.
. Отсюда с помощью любой многослойной ИНС всего с двумя перерабатывающими слоями можно с любой точностью аппроксимировать любую многомерную функцию на единичном отрезке.
На сегодняшний день существует много разновидностей нейронных сетей, характерных для различных типов задач, которые можно классифицировать по следующим признакам:
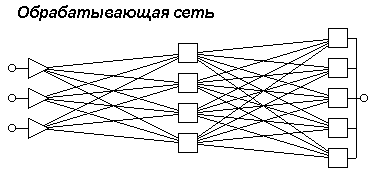
Рассмотрим возможности обучения ИНС на примере многослойного персептрона с прямым распространением информации. Характер связей сети для нашего случая будет выглядеть, как показано на рис 9.4:
Нейроны регулярным образом организованы в слои, причем элементы некоторого слоя связаны только с нейронами предыдущего слоя, и информация распространяется от предыдущих слоёв к последующим. Входной слой, состоящий из чувствительных (сенсорных)
S-элементов, на который поступают входные сигналы Хi, никакой обработки информации не совершает и выполняет лишь распределительные функции. Каждый S-элемент связан с совокупностью ассоциативных элементов (А-элементов) первого промежуточного слоя, а А-элементы последнего слоя соединены с реагирующими элементами (R-элементами).
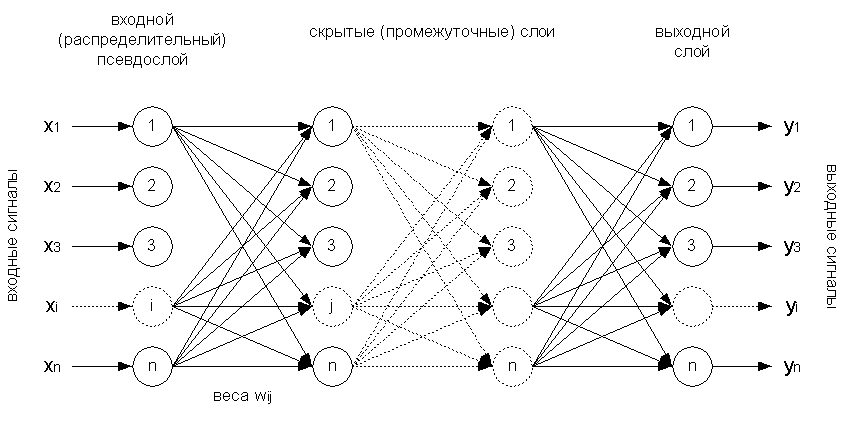
Рис. 9.4. Структура многослойного персептрона
Взвешенные комбинации выходов
R-элементов составляют реакцию системы, которая указывает на принадлежность распознаваемого объекта определенному образу. Если распознаются только два образа, то в персептроне устанавливается один R-элемент, который обладает двумя реакциями – положительной и отрицательной. Если образов больше двух, то для каждого образа устанавливают свой R-элемент, а выход каждого такого элемента представляет линейную комбинацию выходов A-элементов.Выбор количества слоёв и типа активационной функции влияет на способность сети решать те или иные задачи. Однослойная сеть способна формировать линейные разделяющие поверхности и легко сводится к рассмотренному нами в разделе 8.5 методу обобщенного портрета. Линейная модель является хорошей точкой отсчета для сравнения эффективности различных многослойных сетей с нелинейными функциями активации, позволяющими, как показано выше, аппроксимировать любые выпуклые многомерные функциональные зависимости.
Уточним механизм моделирования разделяющих поверхностей многослойным персептроном. Уровень активации каждого нейрона представляет собой простую линейную функцию Х-ов, т.е. берется взвешенная сумма подающихся на вход сигналов с добавлением к ней порогового значения. Эта активация затем преобразуется с помощью заданной функции
. Если в качестве функции активации использовать сигмоидную кривую, имеющую S-образную форму, то комбинация линейной функции нескольких переменных и скалярной логистической функции 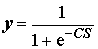 приводит к характерному профилю "сигмоидного склона", который выдает элемент первого промежуточного слоя.
приводит к характерному профилю "сигмоидного склона", который выдает элемент первого промежуточного слоя.
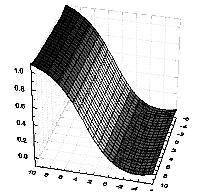
На приведенном рис. 9.5а соответствующая поверхность изображена в виде функции двух входных переменных. При изменении весов
w1…wn и порогов Т может меняться как ориентация всей поверхности отклика, так и крутизна склона (большим значениям весов соответствует более крутой склон). Элемент с большим числом входов выдает многомерный аналог представленной поверхности.|
|
|
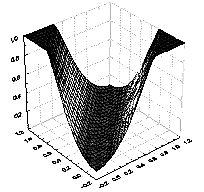
Рис. 9.5. Вид простейшей разделяющей поверхности сигмоидного типа для одного нейрона (фиг. а) и персептрона с одним промежуточным слоем (фиг. б)
В многослойной сети подобные функции отклика комбинируются друг с другом с помощью последовательного взятия их линейных комбинаций и применения нелинейных функций активации. На рисунке 9.5б изображена типичная поверхность отклика для сети с одним промежуточным слоем, состоящим из двух элементов, и одним выходным элементом. Две разных сигмоидных поверхности объединены в одну поверхность, имеющую форму буквы “
U”.Обучение многослойного персептрона
После того, как определено число слоев и число элементов в каждом из них, нужно найти значения весовых коэффициентов w1,...,wn и порогов для каждого составляющего нейрона, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Для того, чтобы оценить, насколько верное решение сделала ИНС, определяется среднеквадратичная ошибка сети как разница между эталонным и выходным вектором:
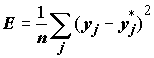 , (9.22)
, (9.22)
где
Y*j – известное выходное значение для примеров обучающей выборки. Процесс обучения сети заключается в многократной подгонке коэффициентов w1,...,wn к имеющимся выборочным данным с использованием различных алгоритмов нелинейной оптимизации.Здесь оказывается очень полезным понятие поверхности ошибок. Каждому из
N свободных параметров модели (весов и порогов) соответствует одно измерение в многомерном пространстве. Пусть (N+1)-е измерение соответствует ошибке сети Е. Для всевозможных сочетаний значений весов соответствующие им значения ошибок представляют собой множество точек, образующих поверхность ошибок. Тогда цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку. В случае линейной модели с суммой квадратов в качестве функции ошибок поверхность ошибок представляет собой параболоид – гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом, который достаточно легко локализовать. В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и имеет локальные минимумы, плоские участки, седловые точки и длинные узкие овраги (см. рис. 9.6).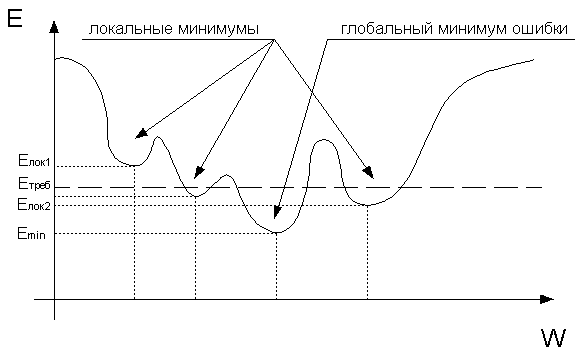
Рис. 9.6. Интерпретация поверхности ошибок нейронной сети
Аналитическими средствами найти в таких условиях глобальный минимум невозможно, поэтому процесс обучения ИНС, по сути дела, заключается в исследовании этой поверхности. Отталкиваясь от случайной начальной конфигурации весов и порогов, алгоритм оптимизации начинает передвижение к минимуму, используя на каждом шаге вектор градиента (т.е. направления кратчайшего спуска). Можно сказать, что процесс ведет себя как слепой кенгуру – каждый раз прыгает в направлении, которое ему кажется наиболее привлекательным. В общем случае результат обучения ИНС может соответствовать субоптимальному решению, т.е. не глобальному оптимум, а решению, которое нас устроит. В самом деле, если Елок2 < Етребуемое, то такое решение вполне приемлемо. Другое дело, когда веса попадают в область локального минимума (такого как Елок1) и при этом Елок>Етребуемое, а величины шага обучения не хватает чтобы выйти оттуда.
Самый известный алгоритм обучения сети – так называемый, алгоритм обратного распространения (back propagation) [Нейронные сети.., 2001]. В основу метода легли прямой ход вычисления выходных значений, вычисление ошибки последнего слоя и рекурсивное обратное распространение.
Для выходного слоя определение ошибки
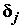 нейрона j тривиально:
нейрона j тривиально:
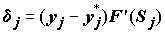
и напоминает систему поощрений-наказаний, используемую при обучении однослойных сетей. Для каждого предыдущего слоя ошибка определяется рекурсивно через ошибку следующего слоя:
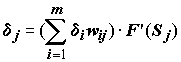 ,
,
т.е. для каждого
j-го нейрона ошибки следующего слоя как бы распространяются к нему обратно сквозь соответствующие веса. Этот механизм обратного распространения дополнен традиционными для многих градиентных методов оптимизации процедурами оценки вектора кратчайшего спуска, изменения величины шага пропорционально крутизне склона и проч. Существуют также современные алгоритмы обучения сетей второго порядка, такие как метод сопряженных градиентов и метод Левенберга-Маркара, которые во многих задачах работают на порядок быстрее [Bishop, 1995].Переобучение и обобщение
Основная задача моделирования состоит в подборе сети, адекватно прогнозирующей совершенно новые наблюдения. С. Бишоп [Bishop, 1995] пишет: “Минимизация ошибок на обучающем множестве, которое не бывает ни идеальным, ни бесконечно большим, - это совсем не то же самое, что минимизация “настоящей” ошибки заранее неизвестной модели явления”. Сеть с небольшим количеством весов может оказаться недостаточно гибкой, чтобы смоделировать имеющуюся зависимость. Однако, слишком большое количество нейронов и слоев позволяет моделировать очень сложные функции, но это часто приводит к переобучению сети, когда модель будет давать совершенно правильные ответы, но только на тех примерах, которым её обучили.
Выбор нейросети “правильной” сложности сводится к двум рецептам: использование контрольных выборок и экспериментирование. Механизм контрольной кросс-проверки заключается в том, что некоторая часть обучающих наблюдений резервируется, т.е. подгонка коэффициентов модели и поиск минимума ошибки сети по ним не осуществляется. Эти измерения, как и в алгоритмах МГУА, используются только для независимого контроля результата и называются контрольной выборкой. Если разбиение на обучающее и контрольное множества было выполнено однородно, то, по мере того как сеть обучается, ошибка обучения и ошибка на контрольном множестве будут одновременно уменьшаться. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть стала чересчур точно аппроксимировать данные и наступает фаза переобучения. В этом случае следует уменьшить число А-элементов или слоев сети.
Описанные проблемы с локальными минимумами и выбором размера сети приводят к тому, что в практической работе с ИНС приходится экспериментировать с большим числом различных вариантов конфигурации.
Понижение размерности входных переменных
Цель задачи заключается в таком преобразовании входных данных, чтобы та же информация была бы записана с помощью меньшего числа переменных. Мы уже обсуждали эту проблему, когда знакомились с методом главных компонент (см. раздел 7.5). Следует подчеркнуть, что один из основных недостатков традиционного факторного анализа состоит в том, что это преобразование является линейным и может улавливать только линейные направления максимальной вариации. Поэтому рассмотрим другой подход к решению этой проблемы: нелинейный вариант метода главных компонент, основанный на применении автоассоциативных сетей.
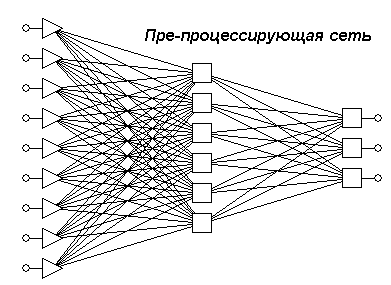
Автоассоциативная сеть – это сеть, предназначенная для воспроизведения на выходе своих же сигналов. У такой сети число выходов совпадает с числом входов, а все нейроны имеют особое свойство. Если число элементов промежуточного слоя сделать меньше числа входов/выходов, то это заставляет сеть "сжимать" информацию, представляя ее в меньшей размерности. Трехслойная автоассоциативная сеть сначала линейно преобразует входные данные в меньшую размерность промежуточного слоя, а затем снова линейно разворачивает их в выходном слое. Можно показать, что такая сеть на самом деле реализует стандартный алгоритм анализа главных компонент. Для того, чтобы выполнить нелинейное понижение размерности, нужно использовать пятислойную сеть (см. рис. 9.7). Ее средний слой служит для уменьшения размерности, а соседние с ним слои, отделяющие его от входного и выходного слоев, выполняют нелинейные преобразования.
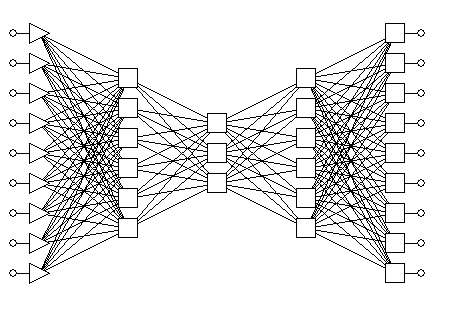
Рис. 9.7. Автоассоциативная сеть для понижения размерности признакового пространства с девяти до трех
Если из автоассоциативной сети удалить два последних слоя, то получается сеть для пре-процессирования, с помощью которой генерируется версия входных данных в уменьшенной размерности.
Результаты расчетов
Прогнозирование альтернативной переменной
Построим нейронную сеть для классификации двух категорий качества вод "Чисто" / "Грязно" на базе многослойного персептрона с использованием обучающей выборки из 520 примеров, описанной в разделах 8.2, 8.3 и 9.2. Входами сети являются значения обилия 27 таксономических групп зообентоса, отобранных в результате генетического алгоритма (см. раздел 9.2), а также количество видов в пробе. По условиям работы всех алгоритмов построения сетей данные подвергаются препроцессингу – предварительному масштабированию исходных значений входов в единую шкалу: в нашем случае используем известную формулу минимакса, в результате чего каждый преобразованный признак варьируется на интервале [0,1].
Примем стандартную модель персептрона с 28 входами, одним выходом и одним промежуточным слоем, состоящем из 14 А-нейронов, т.е. полусумме числа входных и выходных элементов (см. рис. 9.8). Выполним обучение сети в трех вариантах:
Для каждого из вариантов обучение проведем в двух режимах: без использования контрольного множества и с применением кросс-проверки на контрольном множестве. В первом случае сеть обучается на всех 520 примерах, а во втором случае 120 примеров выделяются в качестве внешнего дополнения и используются для независимого контроля качества сети.
Построенная сеть в нашем случае для каждого произвольного вектора Х выдает на выходе некоторое значение апостериорной вероятности на интервале от 0 до 1. Для конкретной классификации примеров используются два задаваемых доверительных уровня: порог принятия (т.е. минимальное значение выхода, при котором наблюдение будет считаться принадлежащим классу 1) и порог отвержения (т.е. максимальное значение выхода, относящее измерение к классу 0). В нашем примере мы задали эти пороги равными 0.55 и 0.45 соответственно. Все вектора, предъявленные сети и имеющие отклик внутри диапазона доверительных уровней, классифицируются как неопределенные.
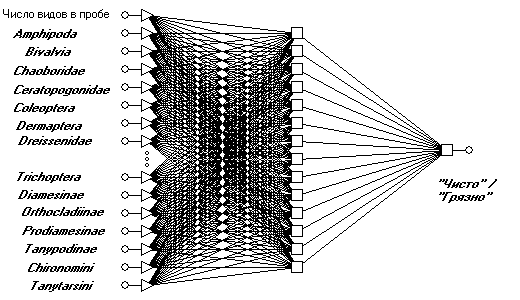
Рис. 9.8. Схема многослойного персептрона для оценки категории качества воды по обилию групп зообентоса
Результаты моделирования по традиции для всех задач классификации оценим как долю ошибочных опознаний на обеих выборках (см. табл. 9.5, где приведены данные только для режима с кросс-проверкой).
Таблица 9.5
Результаты использования модели персептрона с одним промежуточным слоем для оценки категории качества воды
|
Вид функции активации нейронов |
Оценка качества сети |
Результат прогноза |
Обучающая выборка |
Контрольное множество |
||||
|
Класс "Чисто" |
Класс "Грязно" |
Правильный прогноз, % |
Класс "Чисто" |
Класс "Грязно" |
Правильный прогноз, % |
|||
|
Линейная функция |
Средне-квадрати-ческая ошибка |
"Чисто" |
136 |
5 |
94.4 |
28 |
7 |
75.6 |
|
"Грязно" |
7 |
271 |
98.1 |
7 |
53 |
84.1 |
||
|
Отказ |
1 |
0 |
2 |
3 |
||||
|
Итого |
144 |
276 |
96.9 |
37 |
63 |
81.0 |
||
|
Логистическая (сигмоидная) функция |
Средне-квадрати-ческая ошибка |
"Чисто" |
140 |
0 |
97.2 |
33 |
7 |
89.2 |
|
"Грязно" |
3 |
276 |
100 |
3 |
55 |
87.3 |
||
|
Отказ |
1 |
0 |
1 |
1 |
||||
|
Итого |
144 |
276 |
99.0 |
37 |
63 |
88.0 |
||
|
Логистическая (сигмоидная) функция |
Простая энтропия |
"Чисто" |
141 |
0 |
97.9 |
34 |
4 |
91.9 |
|
"Грязно" |
2 |
276 |
100 |
2 |
58 |
92.1 |
||
|
Отказ |
1 |
0 |
1 |
1 |
||||
|
Итого |
144 |
276 |
99.3 |
37 |
63 |
92.0 |
||
На основе выполненных расчетов можно сделать следующие очевидные выводы:
Нейронную сеть вследствие ее принципиальной многомерности обычно интерпретируют как "черный ящик", поскольку визуальный или статистический анализ коэффициентов усиления и порогов, как это делается, например, в множественной регрессии, для всех структурных связей графа представляет собой весьма утомительную процедуру, не гарантирующую достоверных выводов. Тем не менее, при желании, можно заглянуть "внутрь" этого ящика и попытаться выяснить роль каждого скрытого элемента, создаваемый ими потенциал активации и прочие нейронные характеристики (в рамках нашего изложения мы этого желания не испытали).
Сети для множественной классификации
Построим нейронную сеть для непосредственной оценки значения класса качества водоемов в виде числа от 1 до 6. Сформируем выборку из тех же 520 измерений, но в качестве девяти варьируемых переменных будем использовать различные обобщенные гидробиологические показатели и традиционные "интегральные" индексы зообентоса.
Архитектура выбранного персептрона с одним промежуточным слоем представлена на рис. 9.9. Сеть имеет 5 выходов, соответствующих каждому из присутствующих в обучающей выборке классов качества воды. При правильном распознавании на одном из выходных элементов появляется высокое значение активации при незначительной ее величине на остальных четырех.
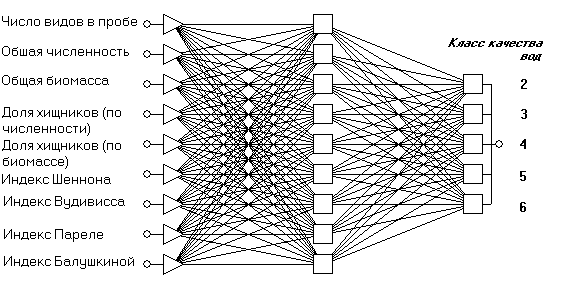
Рис. 9.9. Нейронная сеть для прогнозирования пяти классов качества воды
Нами использовалась в выходном слое специальная функция активации (Softmax), представляющая собой взвешенную и нормированную на единицу сумму экспонент. Можно показать, что если входные данные представляют собой выборку из какого-либо экспоненциального распределения, то выходы софтмакс-элементов можно трактовать как вероятности (напомним, что самым известным примером экспоненциального распределения является нормальное). Например, если для измерения на ст. 1 р. Байтуган активации выходных нейронов сети оказались равными {0.314, 0.503, 0.142, 0.028, 0.018 }, то с вероятностью 0.503 можно предположить, что это измерение было взято из водоема 3 класса качества, а с вероятностью 0.817 – из водоема 2-3 классов.
Хотя анализ весовых коэффициентов и активностей отдельных фрагментов сети представляется неблагодарной деятельностью, методы нейросетевого моделирования позволяют оценить относительную значимость влияния отдельных исходных переменных на отклик, т.е. выполнить анализ чувствительности сети по ее входам. Этот анализ дает возможность идентифицировать неинформативные переменные с низкой чувствительностью, которые могут благополучно игнорироваться в последующих просчетах. Разумеется, подобные заключения должны приниматься со всей осторожностью, поскольку никакой анализ чувствительности не гарантирует абсолютную точность и надежность оценок "полноценности" переменных в модели. Например, в литературе приводится много примеров взаимного влияния и обусловленности исходных факторов, когда ни одна из переменных по отдельности не несет существенную информацию (классы будут выглядеть совершенно перемешанными), но, учитывая всю совокупность признаков, классы можно легко разделить.
Чувствительность каждой входной переменной измеряется в терминах ошибки сети: т.е. вычисляется прирост общей погрешности предсказания, если бы анализируемая переменная была бы исключена на входе. Более удобно для анализа отношение двух ошибок: ошибки сети без использования
j-й переменной к аналогичной ошибке при ее наличии. Если это отношение равно или менее 1, то анализируемая переменная либо не участвует в работе нейросетевой модели вообще, либо даже мешает ее работе, снижая общую эффективность. Иногда стоит удалять переменные даже с чувствительностью несколько более чем 1.0, и переквалифицировать сеть с целью достижения ее большей компактности и надежности. Значения прироста ошибки d j и отношения чувствительности h j для переменных, использованных в рассматриваемом примере, представлены в табл. 9.6. Подробные выводы легко может сделать сам читатель; мы же выскажем только предположение, что странная "рокировка" ролей общей биомассы и индекса Шеннона при переходе от стадии обучения к контролю объясняется не только случайными причинами.Таблица 9.6
Анализ чувствительности входных переменных модели многослойного персептрона для прогнозирования класса качества вод
|
Анализируемые входные переменные |
Обучающая выборка |
Контрольная выборка |
||||
|
Ранг |
d j |
h j |
Ранг |
d j |
h j |
|
|
Биотический индекс Вудивисса |
1 |
0.377 |
1.095 |
1 |
0.381 |
1.078 |
|
Олигохетный индекс Пареле |
2 |
0.355 |
1.030 |
2 |
0.369 |
1.045 |
|
Общая биомасса (ln ), мг/м 3 |
3 |
0.351 |
1.018 |
7 |
0.354 |
1.003 |
|
Число видов в пробе |
4 |
0.350 |
1.016 |
3 |
0.357 |
1.012 |
|
Хирономидный индекс Балушкиной |
5 |
0.348 |
1.010 |
8 |
0.354 |
1.003 |
|
Общая численность (ln), экз/м 3 |
6 |
0.348 |
1.009 |
5 |
0.356 |
1.007 |
|
Доля хищников (по численности) |
7 |
0.347 |
1.007 |
9 |
0.353 |
0.999 |
|
Доля хищников (по биомассе) |
8 |
0.347 |
1.006 |
6 |
0.356 |
1.007 |
|
Индекс Шеннона |
9 |
0.346 |
1.003 |
4 |
0.356 |
1.008 |
Результаты достоверности оценки классов качества представим в виде таблицы сопряженности "Факт/Прогноз" (табл. 9.7), где по главной диагонали проставлены частоты правильной оценки групп измерений, а в остальных клетках – имеющиеся ошибки прогноза отдельно для обучающей выборки и контрольной последовательности.
Несмотря на всю математическую мощь нейронных сетей, эффективность распознавания класса качества вод с использованием персептрона лишь незначительно превысила достоверность дискриминантного анализа (см. раздел 8.3) и уступила методу, основанному на видовых индикаторных индексах (раздел 8.4). Очевидно, что здесь был достигнут порог насыщения для уровня информативности "интегральных" показателей зообентоса, превысить который невозможно никакими интеллектуальными ухищрениями. Модель на данном наборе признаков сделала все, что могла и дальнейшие резервы повышения эффективности – в расширении признакового пространства с привлечением данных о видовой структуре. Это подтверждает и тот уникальный для методов распознавания факт, когда ошибка классификации на контрольной выборке оказалась меньше, чем на обучающей последовательности.
Таблица 9.7
Результаты прогнозирования класса качества вод по модели многослойного персептрона
|
Классы качества вод |
Фактические |
Итого прогноз |
Правильный прогноз, % |
Ошибка на два и более класса, % |
|||||
|
2 |
3 |
4 |
5 |
6 |
|||||
|
Прогноз по обучающей выборке |
2 |
18 |
10 |
3 |
0 |
0 |
31 |
58.06 |
9.67 |
|
3 |
13 |
52 |
24 |
6 |
0 |
95 |
54.47 |
6.31 |
|
|
4 |
11 |
25 |
77 |
15 |
17 |
145 |
53.10 |
19.31 |
|
|
5 |
0 |
10 |
14 |
36 |
15 |
75 |
48.0 |
13.3 |
|
|
6 |
1 |
2 |
6 |
6 |
9 |
24 |
37.5 |
37.5 |
|
|
Итого факт |
43 |
99 |
124 |
63 |
41 |
370 |
51.89 |
13.5 |
|
|
Прогноз по контрольной выборке |
2 |
7 |
3 |
2 |
0 |
0 |
12 |
58.33 |
16.6 |
|
3 |
2 |
15 |
14 |
3 |
1 |
35 |
42.86 |
11.42 |
|
|
4 |
1 |
8 |
40 |
6 |
7 |
62 |
64.52 |
12.9 |
|
|
5 |
0 |
2 |
5 |
13 |
11 |
31 |
41.94 |
6.45 |
|
|
6 |
0 |
1 |
2 |
2 |
5 |
10 |
50.00 |
30.0 |
|
|
Итого факт |
10 |
29 |
63 |
24 |
24 |
150 |
53.33 |
12.66 |
|
Задача о понижении размерности
Чтобы осуществить нелинейное понижение размерности исходной матрицы наблюдений для прогнозирования класса качества вод, используемой в предыдущем примере, выполним следующие действия:
|
|
|
Рис. 9.10. Последовательность двух сетей для понижения размерности признакового пространства
В нашем конкретном случае достоверность распознавания по полученной двухуровневой сетевой модели несколько снизилась по сравнению с обычным персептроном, представленным на рис. 9.9. Однако общий смысл перехода в пространство небольшой размерности состоит не столько в том, чтобы повысить эффективность прогноза, сколько в попытке дать какое-то разумное объяснение имеющимся внутренним механизмам анализируемых явлений. Один из способов это сделать – проанализировать двух- или трехмерную визуализацию классифицируемых объектов в осях главных факторов (см. рис. 9.11). Изучив на полученной "картинке" сильно трангрессирующее облако точек, принадлежащих разным классам качества воды, мы, по крайней мере, поняли, какая трудновыполнимая задача была поставлена перед методами распознавания.
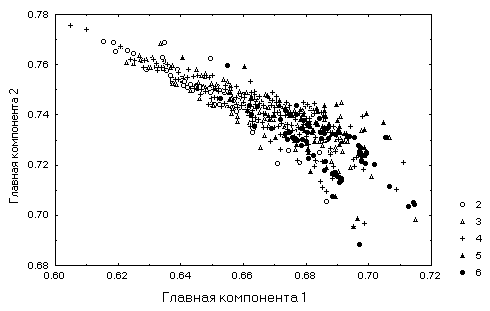
Рис. 9.11. Изображение в пространстве двух главных компонент облака точек, соответствующих различным классам качества воды
| Дальше
|
Назад |
Начало |
Конец |
Список
|