| Дальше
|
Назад |
Начало |
Конец |
Список
|
9.5. Решение задачи регрессии с помощью нейросетей
различной архитектурыФормулировка задачи
Пусть в таблице произвольных гидробиологических наблюдений X размерностью m >1 откликом Y является один из любых признаков, измеренных в количественной шкале.
Необходимо решить задачу регрессии, целью которой является оценка по матрице входных переменных параметров функции выходной переменной, принимающей непрерывный диапазон числовых значений.
Математический лист
(продолжение раздела 9.4) Нейронные сети наиболее часто используемых архитектур выдают выходные значения в некотором определенном диапазоне (например, на отрезке от 0 до 1 в случае логистической функции активации). Для задач классификации это не создает никаких трудностей. Однако для задач регрессии особую важность имеет масштаб и диапазон существования выходных значений, поскольку на передний план выходят проблемы, связанные с эффектом экстраполяции.Как показано в главе 1.5, простейшей из масштабирующих функций, сводящей переменные сети к "приемлемому" диапазону, является минимаксная функция: она находит минимальное и максимальное значение переменной по обучающему множеству и выполняет линейное преобразование так, чтобы значения лежали в нужном диапазоне, как правило, на отрезке [0,1]. Если эти действия применяются только к измерениям обучающей выборки, то есть гарантия, что результаты преобразования попадут в область возможных выходных значений сети. Сеть может быть обучена, но выход сети будет находиться в определенных границах, пересечение которые будет пресекаться.
Это обстоятельство можно считать достоинством, если бы не проблема экстраполяции: если продолжать кривую вправо по числовой оси, то выход ее за лимитируемые пределы неизбежен, даже если мы еще достаточно близко отошли от диапазона обучающих векторов. Чтобы избежать этого, сужают целевой диапазон минимаксной масштабирующей функции, например, делают его от 0.25 до 0.75, создавая некоторый запас. Интересно заметить, что на среднем участке сигмоидная кривая "почти линейна", поэтому другой путь для учета экстраполяции - использование линейного выходного слоя.Задачи регрессии методами нейросетевого моделирования
можно решать с помощью сетей различных типов: многослойного персептрона, линейной сети, радиальной базисной функции и обобщенной регрессионной сети. Линейная модель по сути ничем не отличается от обычной линейной регрессии, но на языке нейронных сетей представляется сетью без промежуточных слоев, которая в выходном слое содержит только линейные элементы (то есть элементы с линейной функцией активации). Обучить линейную сеть можно с помощью стандартного алгоритма линейной оптимизации.В предыдущем разделе было описано, как многослойный персептрон моделирует функцию отклика с помощью функций "сигмоидных склонов". Столь же естественным является подход, основанный на разбиении пространства окружностями или, в общем случае, гиперсферами, которые задаются своим центром и радиусом. Поверхность отклика такого радиального элемента представляет собой гауссову функцию колоколообразной формы, с вершиной в центре и понижением к краям (см. рис. 9.12). Наклон гауссова радиального элемента можно менять подобно тому, как можно менять наклон сигмоидной кривой в персептроне.
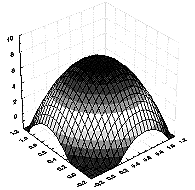
Рис. 9.12. Вид функции радиального элемента
Сеть, построенная на радиальных базисных функциях (RBF), имеет промежуточный слой из радиальных элементов, каждый из которых воспроизводит гауссову поверхность отклика. Поскольку эти функции нелинейны, то для моделирования любой произвольной функции отклика нет необходимости использовать более одного промежуточного слоя – достаточно лишь взять оптимальное число радиальных элементов. RBF-сети имеют как ряд достоинств (компактность, быстрая обучаемость), так и недостатков. Например, с "групповым" представлением пространства модели связано неумение сетей RBF экстраполировать свои выводы за область известных данных: при удалении от обучающего множества значение функции отклика быстро падает до нуля.
В предыдущем разделе, говоря о задачах классификации, мы упомянули о том, что выходы сети можно интерпретировать как оценки вероятности того, что элемент принадлежит некоторому классу, и сеть, фактически, "учится" оценивать функцию плотности вероятности. Аналогичная интерпретация может иметь место и в задачах регрессии – выход сети рассматривается как ожидаемое значение модели в данной точке пространства входов, связанное с плотностью вероятности совместного распределения входных и выходных данных.
Задача оценки плотности вероятности имеет давнюю историю в математике и относится к области байесовой статистики. Возможный подход к оценке плотности вероятности основан на ядерных оценках Парзена [Parzen, 1962], связывающих ансамбли близко лежащих точек с некоторым доверием к уровню плотности, которое по мере отдаления убывает и стремится к нулю. В методе ядерных оценок в точке, соответствующей каждому наблюдению, помещается некоторая простая функция (например, гауссова функция), затем все они складываются, и в результате получается оценка для общей плотности вероятности. Если обучающих примеров достаточное количество, то такой метод дает достаточно хорошее приближение к истинной плотности вероятности.
Аппроксимация плотности вероятности с помощью ядерных функций является методологической основой для вероятностных
(PNN) и обобщенно-регрессионных (GRNN) нейронных сетей. В этих сетях в точку расположения каждого обучающего наблюдения помещается гауссова ядерная функция. Окончательная выходная оценка сети получается как взвешенное среднее выходов по всем обучающим наблюдениям, где величины весов отражают расстояние от этих наблюдений до той точки, в которой производится оценивание. Таким образом, более близкие точки вносят больший вклад в оценку.Первый промежуточный слой сети GRNN состоит из радиальных элементов, а второй промежуточный слой содержит элементы, которые помогают оценить взвешенное среднее и состоит из двух нейронов. Обобщенно-регрессионная сеть обучается почти мгновенно, но может получиться большой и медленной. Как и сеть RBF, сеть GRNN не обладает способностью эффективно экстраполировать данные.
Результаты расчетов
Моделирование индивидуального веса особи
Выполним синтез различных нейронных сетей для прогнозирования зависимости среднего веса особей семейства хирономид от восьми различных переменных, подробно описанных в разделе 8.1:
В составе общей таблицы наблюдений, состоящей из 473 измерений, выделим обучающую выборку из 400 объектов, а остальные примеры используем для контроля. Средние значения выходной переменной составили для обучающей и контрольной выборок, соответственно, 1.78 и 3.24 мг, стандартные отклонения – 2.70 и 6.71.
С помощью "интеллектуального генератора" построим 50 нейронных сетей различного типа и архитектуры, из которых отберем наилучшие модели, т.е. имеющие наименьшую ошибку на контрольном множестве. Будем попутно исключать при этом из числа входных переменных признаки, имеющие низкую чувствительность. Основные результаты расчетов представлены в табл. 9.8.
Таблица 9.8
Результаты прогнозирования среднего веса особи с использованием нейронных сетей различного типа (в числителе – показатель для обучающей выборки, в знаменателе – для контрольной последовательности)
|
Наименование показателей |
Трехслойный персептрон |
Линейная модель |
Радиальные базисные функции RBF |
Обобщенно-регрессионная модель GRNN |
|
Характеристики сети: количество элементов входного и скрытого слоев |
Входных – 6 |
Входных – 4 |
Входных – 6 |
Входных – 8 |
|
Перечень входных переменных, исключенных из модели |
6 , 8 |
1, 3, 5, 7 |
4, 6 |
- |
|
Средняя абсолютная разность расчетных и фактических значений |
3.08 |
1.49 |
1.48 |
1.42 |
|
Стандартное отклонение ошибки сети |
2.58 |
2.65 |
2.62 |
2.49 |
|
Отношение стандартного отклонения ошибки сети к стандартному отклонению отклика |
0.955 |
0.980 |
0.970 |
0.922 |
|
Коэффициент корреляции расчетных и фактических значений |
0.297 |
0.199 |
0.242 |
0.464 |
Эти результаты позволяют сделать два достаточно общих вывода:
Однако, как основной вывод, следует признать, что между средним весом особей и представленным комплексом переменных существует достаточно слабая статистическая зависимость, которую не удалось существенно улучшить с использованием различных методов нейросетевого моделирования. Например, на обучающей выборке лишь GRNN-модель оказалась чуть лучше (коэффициент корреляции 0.464 против 0.394) обычной линейной регрессионной модели, представленной в таблице 8.1 раздела 8.1.
Доля общей вариации индивидуального веса, объясненная любой из протестированных сетей табл. 9.8, составляет от 3 до 5%. В то же время, если на той же выборке в качестве выходной переменной принять, например, индекс Шеннона, то доля объясненной дисперсии даже при моделировании трехслойным персептроном составит от 42.3 % на обучающей выборке до 38.6 % на контрольной последовательности. Коэффициент корреляции Пирсона в тех же условиях изменяется от 0.817 до 0.790 соответственно, что следует оценить как весьма высокий показатель применительно к гидробиологическим моделям.
Анализ связи между гидрохимическими и гидробиологическими показателями
Ранее нами были приведены примеры построения регрессионных моделей по методу "включений с исключениями" Эфроимсона (раздел 8.1) и моделей МГУА на основе алгоритма многорядной селекции (раздел 9.3). В этих примерах оценивалась взаимосвязь между некоторыми гидрохимическими параметрами качества воды (концентрациями ионов железа, аммонийного азота, минерального фосфора и БПК) и 7 основными гидробиологическими показателями обилия и индексами: XH – информационного индекса Шеннона, XV – биотического индекса Вудивисса, XP – олигохетного индекса Пареле, XСI – хирономидного индекса Балушкиной, числа видов XS, логарифмов суммарной численности XN и биомассы XB зообентоса в пробе.
Для прогнозирования каждого из указанных гидрохимических показателей в ходе перебора многих вариантов была построена наилучшая нейросетевая модель со следующими параметрами:
Несмотря на известную теоретическую проблематичность корректного сравнения математических моделей, имеющих разную параметричность, количество степеней свободы и проч. [Брусиловский, Розенберг, 1981; Розенберг, 1989], мы сочли возможным предложить читателю некоторый анализ эффективности моделирования всеми протестированными методами. Как и в другой нашей работе [Розенберг с соавт., 1994], сопоставление моделей-претендентов проведем по системе критериев, представленных в табл. 9.9.
Таблица 9.9
Оценка эффективности различных моделей-претендентов прогнозирования гидрохимических показателей по совокупности критериев (сокращения: МШР – модель пошаговой регрессии, МГУА – модели самоорганизации, ИНС – нейросетевые модели)
|
Химический компонент |
Тип модели |
Средне-квадрати-ческая ошибка |
Средний модуль ошибки |
Макси-мальный модуль ошибки |
Критерий регуляр-ности |
Коэффи-циент корреляции |
Критерий Дарбина-Уотсона |
|
Железо |
МШР |
0.317 |
0.242 |
1.09 |
0.847 |
0.532 |
1.83 |
|
МГУА |
0.322 |
0.237 |
1.08 |
0.840 |
0.440 |
2.04 |
|
|
ИНС |
0.293 |
0.205 |
1.27 |
0.781 |
0.628 |
2.18 |
|
|
Аммонийный азот |
МШР |
0.230 |
0.169 |
1.04 |
0.908 |
0.418 |
1.37 |
|
МГУА |
0.237 |
0.177 |
1.09 |
0.907 |
0.364 |
1.147 |
|
|
ИНС |
0.233 |
0.171 |
1.11 |
0.920 |
0.395 |
1.22 |
|
|
Минеральный фосфор |
МШР |
0.0756 |
0.0575 |
0.269 |
0.950 |
0.312 |
0.981 |
|
МГУА |
0.0730 |
0.0567 |
0.241 |
0.932 |
0.372 |
1.072 |
|
|
ИНС |
0.0665 |
0.0485 |
0.234 |
0.836 |
0.551 |
1.33 |
|
|
БПК 5 |
МШР |
1.70 |
1.19 |
5.96 |
0.837 |
0.546 |
1.11 |
|
МГУА |
2.00 |
1.44 |
5.46 |
0.969 |
0.247 |
0.925 |
|
|
ИНС |
1.71 |
1.28 |
4.95 |
0.828 |
0.561 |
1.22 |
Примечание.
Жирным шрифтом выделены "наилучшие" с точки зрения эффективности значения критериев.В целом, определенные преимущества в "соревновании" методов прогнозирования оказались на стороне моделей ИНС. Однако даже в ходе перебора более четырехсот версий различных сложных нейросетей, не удалось найти модель для прогноза концентрации аммонийного азота, лучшую, чем простенькое уравнение регрессии. В некоторых случаях с позиций различных критериев эти оценки могут разойтись: например, для прогноза БПК, если принять во внимание коэффициент корреляции, лучшей оказалась модель ИНС, но меньшую среднюю ошибку доставляет уравнение регрессии.
Резерв повышения надежности моделей прогнозирования гидроэкологических показателей видится нам в объединении отдельных моделей в
"коллектив", суммарная эффективность которого практически всегда оказывается значительно выше любого из его членов. Структурные связи в коллективе выбираются таким образом, чтобы положительные свойства той или иной модели (метода) дополняли друг друга, а отрицательные – компенсировались [Растригин, Эренштейн, 1981]. Системы коллективного распознавания и прогнозирования значительно более устойчивы к не вполне объяснимым "провалам", которые свойственны отдельным индивидуальным методам (см., например, модель МГУА для БПК5 в табл. 9.9). Конкретные методы и примеры объединения отдельных прогнозов в работоспособный коллектив были описаны ранее [Брусиловский, Розенберг, 1983; Брусиловский, 1987; Розенберг с соавт., 1994].
| Дальше
|
Назад |
Начало |
Конец |
Список
|