| Дальше
|
Назад |
Начало |
Конец |
Список
|
1.6. Информационные системы экологического мониторинга
Региональные эколого-информационные системы
Действующая система экологического мониторинга, выполняемого как научными учреждениями, так и федеральными контролирующими органами, малоэффективна не только по причине низкой технической оснащенности, но и, в значительной мере, в силу игнорирования современных методов управления данными и комплексной математической обработки результатов многомерных наблюдений. Остается невостребованным и с каждым годом теряется богатейший материал по гидрохимии природных водных систем, накопленный в течение десятилетий региональными службами Госкомгидромета. Очевидно, что кроме традиционных малоинформативных сводок о доле показателей, превышающих ПДК, эти данные могли бы с успехом использоваться для построения как локальных моделей сезонной и многолетней динамики водоемов, так и обобщенных моделей рационального эколого-экономического развития территориальных комплексов.
Построение любой модели экосистемы начинается, как правило, с организации оперативного и непротиворечивого доступа к массивам первичных данных экспедиционных исследований.
Полная компьютерная система, предназначенная для поддержки аналитической деятельности любого проекта (финансового, социального, экологического) должна состоять из следующих семи ступеней функционального анализа данных [Бершадский с соавт., 1999]:
Определим эколого-информационную систему (ЭИС) как региональную автоматизированную экспертную систему по экологии и природоохранной деятельности, которая включает всю располагаемую совокупность данных мониторинга и состоит из трех основных компонентов:
Приведенное нами выделение подсистем ЭИС основано на традиционной классификации компонентов программного обеспечения, разрабатываемого как российскими, так и ведущими мировыми производителями. Современные тенденции развития компьютерной технологии делают нерациональными трудозатраты каждого конкретного пользователя на разработку собственных версий СУБД, ГИС или ППП, поскольку на рынке программного обеспечения существуют многочисленные варианты соответствующих пакетов и инструментальных сред, различающихся только функциональностью, техникой внутренней реализации и стоимостью. Некоторые названия таких программных компонентов приведены ниже:
Большинство перечисленных продуктов имеют внутренние языки программирования и инструментальные средства визуализации информации, импорта/экспорта данных, поэтому технология создания ЭИС сводится к выбору наиболее подходящих программных продуктов, их приобретению и последующей адаптации с целью создания действительно интегрированной системы.
На сегодняшний день одной из самых трудно решаемых проблем при разработке интеллектуальных приложений, подобных ЭИС, является формализация предметной области в виде N-мерной информационной модели. По определению, любая модель ограничена, т.к. отбрасываются незначительные детали и выделяется суть. Именно тут и проявляется первая из проблем – оценить что важно для решения поставленной задачи, а что нет?
Согласно терминологии, принятой в теории информатики, база данных – это “идентифицируемая совокупность взаимосвязанных данных, предназначенных для многоцелевого использования” [ГОСТ 14.413-80]. По теории реляционных баз данных имеется обширная литература, как изданная традиционным "бумажным способом" [Дейт, 1998; Пушников, 1999 и др.], так и представленная на страницах Интернет (например, on-line библиотека Центра Информационных Технологий – http://www.citforum.ru). Применительно к региональным ЭИС, под базой данных будем понимать реализованную с помощью технических средств динамическую информационную модель территории, отражающую пространственно-временную структуру, состояние и взаимосвязи между отдельными элементами моделируемой экосистемы. Разрабатываемый в Институте экологии Волжского бассейна РАН пространственно-распределенный банк экологических и экономических данных [Моисеенкова, Шитиков, 1989; База эколого-экономических.., 1991; Rozenberg, Shitikov, 1993; Розенберг с соавт., 1995; Rozenberg, 1995] включает в себя следующую иерархию баз, образно интерпретируемую как "экологическая матрешка":
Естественно, что при создании таких ансамблей баз данных ключевое место уделяется процессам агрегирования информации в ходе ее прохождения от максимально детализованных баз нижнего уровня к комплексным базам высшего уровня. Одной из типичных баз нижнего уровня является специализированная база гидробиологических данных региона (ограниченного в этом случае малыми реками Самарской области), которую мы рассмотрим в качестве примера [Экологическое состояние.., 1997; Зинченко, Шитиков, 1999].
Состав и структура гидробиологической базы данных
Разработанная информационная система предназначена для ведения и оперативной выборки гидробиологических, гидрохимических и гидрологических данных, необходимых для комплексного анализа структурных деформаций, проходящих в изучаемой экосистеме под влиянием антропогенных воздействий, и сравнительной оценки роли гидробионтов в самоочистительных процессах водотоков. База данных объединяет гидробиологические наблюдения, проведенные на 34 малых реках разного типа и уровня антропогенной нагрузки, расположенных в степной и лесостепной зонах Самарской области (см. схему на рис.1.8).
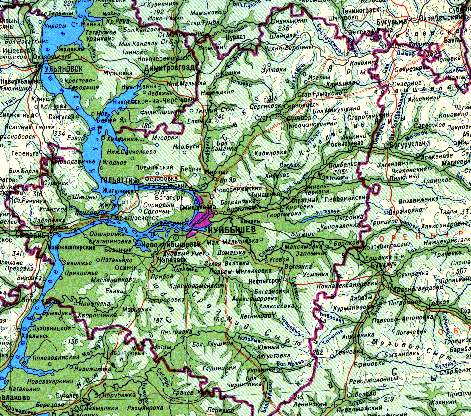
Загрузить схему малых рек Самарской области...
Почти все современные СУБД основаны на реляционной (relational) модели управления базами данных, которая использует следующую терминологию:
Рассматриваемая база гидробиологических данных представляет собой совокупность реляционных таблиц в формате СУБД (MS Access 97), где каждое отдельно взятое наблюдение (гидрохимический показатель или параметр обилия каждого вида в конкретной гидробиологической пробе) информационно связано со спецификацией водоема, координатами и характеристиками точки отбора проб (географический аспект), а также датой проведения экспедиции (временной аспект).
Обобщенная информационная модель базы данных, представленная на рис 1.9, состоит из двух типов таблиц: таблиц-справочников условно-постоянного назначения, необходимых для точной рубрикации хранимых показателей (изображены овальными элементами), и информационных таблиц с первичными результатами наблюдений в период экспедиционных исследований (изображены прямоугольниками).

Рис. 1.9. Информационная модель специализированной базы гидробиологических данных по Самарской области
Для каждой пары таблицы устанавливался определенный тип отношений и технология реализации связи в виде первичных и вторичных ключей. Во всех случаях использовался тип связи "один-ко-многим", ориентированный на рис. 1.9 по направлению стрелки. Например, для каждого водного объекта (в частности, реки) определяется некоторое подмножество "дочерних элементов" – станций, соответствующих пунктам отбора экспедиционных проб или постоянно действующих постам ГМО, которые не могут принадлежать никакому другому "родительскому" объекту. В тоже время, каждая река принадлежит одному "родителю" – региону, объединяющему некоторое подмножество рек.
Таблицы содержательной части базы, включающие измеренные метеорологические, гидрологические гидрохимические и гидробиологические данные, кроме самого значения показателя содержат ссылки на записи справочных таблиц Станция, Измерение и Рубрикатор показателей (для гидробиологических данных – Список видов). В частности, раздел данных по макрозообентосу, который является предметом дальнейшего рассмотрения, включает данные мониторинга по 571 пробе, взятой на 247 станциях за период с 1987 по 2001 гг. Информационные описания гидробиологических объектов в точках наблюдения формируются из значений численности и биомассы 580 видов, принадлежащих к различным таксономическим группам зообентоса. Аналогичной является структура данных о представленности других биотических сообществ: фитопланктона, бактерий, зоопланктона, рыб и т.д.
На рис. 1.10 приведен пример представления гидробиологического блока данных на видеограмме информационной системы, сформированной по конкретному запросу пользователя: на экран дисплея выводится видовой состав, численность и биомасса зообентоса по результатам отбора одной из проб на р. Чапаевка.
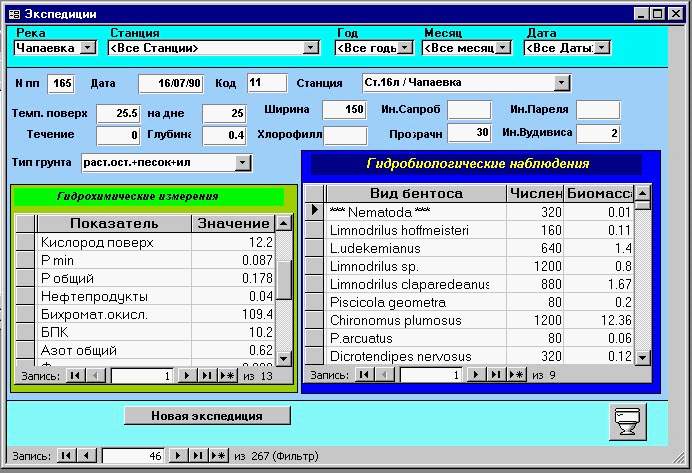
Рис. 1.10. Электронная форма фрагмента базы данных по одному наблюдению
Совокупности количественных гидробиологических показателей, определенных для каждого измерения, ставится в соответствие некоторое множество гидрометеорологических, гидрологических и гидрохимических данных, сопряженных по точке и времени взятия пробы. Приведем основные фрагменты рубрикатора по этим разделам:
Для работы с базой данных разработано программное обеспечение, реализующее традиционные в таких случаях функции:
Оперативная аналитическая обработка данных
Выборка показателей базы данных, предназначенная для математической или аналитической обработки почти всегда представляет собой прямоугольную таблицу. Если значения измеряемых переменных располагать в столбцах, то число таких столбцов может достигать нескольких сотен – по числу переменных. Каждая строка в такой матрице будет содержать измеренные значения упомянутых переменных в одной пробе, отобранной в определенный момент времени в определенном месте. Понятно, что число таких строк может также измеряться сотнями. Иначе говоря, исходные данные, полученные по программе мониторинга, представляют собой матрицу размерности тЧ n, где т – число строк, n – число столбцов, и размерность эта весьма велика (см. рис. 1.11).
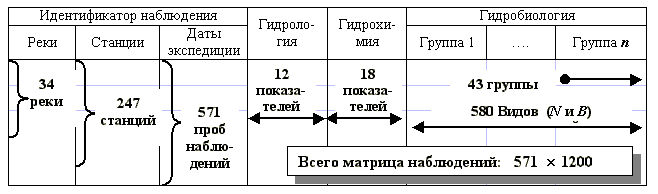
Рис. 1.11. Схема представления информации по разделу базы данных "Зообентос"в виде матрицы
Как было отмечено выше, созданию баз данных сопутствует разработка приложений и технологий, которые, в извечной борьбе математиков с "проклятием размерности", обеспечивают возможность манипулирования и анализа многомерной информации, т.е. то, что объединяется в настоящее время термином “Оперативная аналитическая обработка данных” (англ. – OnLine Analytical Processing или OLAP-технология). Анализируемая информация представляется в виде многомерных гиперкубов, где измерениями служат показатели исследуемого объекта, а в ячейках содержатся агрегированные данные (см. рис. 1.12).
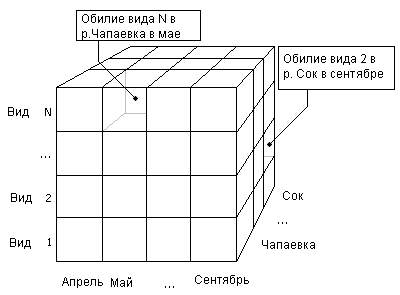
Рис. 1.12. Представление данных об обилии видов в OLAP-кубе в разрезе рек и с разбивкой по месяцам
Очевидно, что некорректные исходные данные приводят к некорректным выводам. Поэтому важнейшим этапом анализа данных является их комплексная предварительная обработка: сглаживание, удаление шумов, редактирование аномальных значений, заполнение пропусков и многое другое. При этом используются алгоритмы робастной фильтрации, спектрального и вейвлет-анализа, последовательной рекуррентной фильтрации, статистического анализа. Если при этом каждое поле анализируемого набора обрабатывается независимо от остальных, то такая предобработка получила название парциальной. Более широкая трактовка термина "препроцессинг" соответствует разведывательному анализу данных, в рамках которого осуществляется отбор информативных признаков и понижение размерности входных данных путем устранения незначащих факторов. Описание конкретных алгоритмов, используемых для этих целей, и примеры их использования представлены в части 3 настоящей книги.
На пути к межрегиональным информационным системам
Дальнейшее развитие информационных и Интернет-технологий неизбежно приведет к работам по созданию федеральных и всемирных систем, обеспечивающих доступ заинтересованных лиц и организаций к данным мониторинга окружающей среды любого уровня детализации. Более того, такие работы уже активно ведутся. В этой связи представляет безусловный интерес для широкого круга практических работников и научной общественности информационная система "ЭКОЛОГИЯ ПРЕСНЫХ ВОД РОССИИ" (http://www.ecograde.bio.msu.ru/index.htm), разработанная на кафедре общей экологии Московского государственного университета им. М.В. Ломоносова (руководители проекта В.Н. Максимов, В.А. Абакумов, А.П. Левич и Н.Г. Булгаков).
Информационная система включает в себя следующий набор данных:
В версии информационной системы за 2000 г. представлены:
Данные сопровождаются подробным набором картосхем с точной идентификацией точек отбора проб и маршрутов измерений.
В определенном смысле, "классикой жанра" являются работы по созданию гидробиологической информационной системы оз. Байкал, осуществляемые, начиная с 70-х годов, Иркутским государственным университетом совместно с институтами СО РАН [Кожова, Павлов, 1985; Методология оценки.., 2000]. Разработанная база данных характеризуется продуманной организацией компьютерной обработки результатов режимных наблюдений фитоценозов и зоопланктонных сообществ на протяжении длительного периода времени (динамические ряды более 50 лет). Гидробиологические измерения сочетаются в базе с данными наблюдений развитой системы гидрохимического мониторинга, охватывающей широкий диапазон ингредиентов и характеризующейся высоким уровнем точности. Композиционная целостность и репрезентативность базы данных явились основой для математического моделирования сезонной динамики экосистемы и процессов массопереноса в озере [Меншуткин с соавт., 1978, 1981; Приемы прогнозирования.., 1985].
| Дальше
|
Назад |
Начало |
Конец |
Список
|