| Дальше
|
Назад |
Начало |
Конец |
Список
|
Глава 5. Задачи о выборках: анализ распределений, сравнение, поиск зависимостей
5.1. Задача о законе распределения гидробиологических показателей
Мем № 28
: “Случайность существует объективно и не зависит от того, знаем ли мы причины явления или не знаем…” М.М. Розенталь Марксистский диалектический метод – М.: Госполитиздат, 1952.Формулировка задачи
Пусть имеется выборка из
n значений X1, X2, …, Xn некоторого измеренного гидробиологического показателя. Необходимо:Эта задача внешне кажется вспомогательной в ряду предлагаемых задач, поскольку само по себе оценивание закона распределения не имеет большого практического смысла. Однако этот подготовительный этап носит обязательный и важный характер для последующего корректного применения большинства методов математической статистики.
Рекомендуемая литература: [Урбах, 1963; Смирнов, Дунин-Барковский, 1963; Кендалл, Стьюарт, 1966; Гмурман, 1972; Крамер, 1975; Закс, 1976; Джонсон, Лион, 1980, 1981; Гнеденко, 1988; Вентцель,1999; Калинина, Панкин, 2001; С.А. Прохоров, 2001а,б, 2002; Прохоров с соавт., 2003].
Математический лист
Случайная величина и ее характеристики
Одним из центральных понятий теории вероятностей является случайная величина – любая количественная характеристика, которая в результате случайного эксперимента может принять одно из некоторого множества значений.
Каждая случайная величина x полностью определяется своей функцией
распределения:F
(x) = Fx (x) = P(x < x) , (5.1)
(5.1)
где
P(x < x) – вероятность того, что случайная величина x принимает значение, меньшее x. Функция F(x) монотонно возрастает на всей числовой оси, причем F(-¥ ) = 0, F(¥ ) = 1. Функция распределения является "паспортом" случайной величины: она содержит всю информация о x и поэтому изучение случайной величины заключается в исследовании ее функции распределения, которую часто называют просто распределением.Если функция распределения
Fx (x) непрерывна, то случайная величина x называется непрерывной случайной величиной. Если функция распределения непрерывной случайной величины дифференцируема, то более наглядное представление о случайной величине дает плотность вероятности случайной величины px (x), которая связана с функцией распределения Fx (x) формулами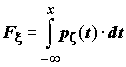 и
и 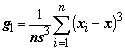 . (5.2)
. (5.2)
Отсюда, в частности, следует, что для любой случайной величины
: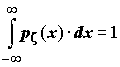 .
.
При решении практических задач часто требуется найти значение
x, при котором функция распределения Fx (x) случайной величины x принимает заданное значение p, т.е. требуется решить уравнение Fx (x) = p. Решения такого уравнения (т.е. соответствующие значения x) в теории вероятностей называются квантилями. Квантилью xp (p-квантилью, квантилью уровня p) случайной величины x , имеющей функцию распределения Fx (x), называют решение xp уравнения Fx (x) = p, p Î (0, 1). Для некоторых p уравнение Fx (x) = p может иметь несколько решений, для некоторых – ни одного. Это означает, что для соответствующей случайной величины некоторые квантили определены неоднозначно, а некоторые квантили не существуют.Квантили, наиболее часто встречающиеся в практических задачах, имеют свои названия: медиана (квантиль уровня
0,5); нижняя квартиль (квантиль уровня 0,25); верхняя квартиль (квантиль уровня 0,75); децили (квантили уровней 0,1, 0,2, …, 0,9); процентили – (квантили уровней 0,01, 0,02, …, 0,99).Вероятность того, что значение непрерывной случайной величины
Fx (x) попадает в интервал (a, b), равная P(a < x < b) = Fx (b) - Fx (a), вычисляется по формуле: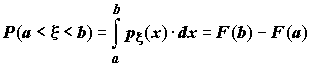 ,
,
причем
, если a = - ¥ , то P(a < x
< b) = P(x
< b) = Fx
(b) , P(a < x
< b) = P(a < x
) = 1 - P(x
< a) = 1 - Fx
(a) .
Наиболее часто применяемыми числовыми характеристиками случайной величины x являются начальные и центральные моменты различного порядка. Для непрерывной случайной величины моменты порядка
k определяются следующими формулами :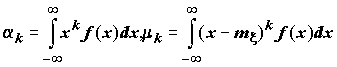 .(5.4)
.(5.4)
Чаще всего используется первый начальный момент
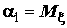 , называемый математическим ожиданием случайной величины
, называемый математическим ожиданием случайной величины 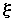 или центром распределения, и второй центральный момент
или центром распределения, и второй центральный момент 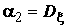 , называемый дисперсией, которая характеризует разброс случайной величины относительно центра распределения. Часто вместо дисперсии используют среднее квадратичное отклонение
, называемый дисперсией, которая характеризует разброс случайной величины относительно центра распределения. Часто вместо дисперсии используют среднее квадратичное отклонение 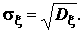
Основные законы распределения
Перечислим наиболее распространенные распределения непрерывных случайных величин.
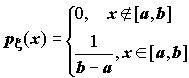
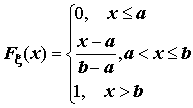 ;
; 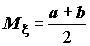 ;
; 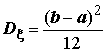 . (5.5)
. (5.5)
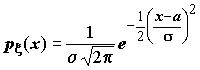 ;
; 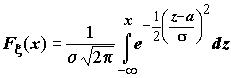 ; Mx
=a
; Mx
=a
Нормальное распределение играет исключительно важную роль в теории вероятностей и математической статистике.
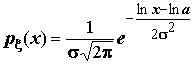 ;
; 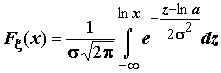 ;
;
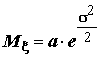 ;
; 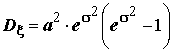 .
.
В ряде областей науки и техники нашли широкое применение такие одномерные распределения непрерывной случайной величины как экспоненциальное распределение, гамма-распределение, распределение Вейбулла и многие другие.
Основным предметом математической статистики является вычисление статистик (да простит нас читатель за тавтологию), являющихся критериями для оценки достоверности априорных предположений, гипотез или выводов по существу эмпирических данных. Другое определение - “Статистики – это предписания, по которым из выборки рассчитывается некоторое число – значение статистики для данной выборки” [Закс, 1976]. Выборочные среднее и дисперсия, отношение дисперсий двух выборок или любые другие функции от выборки могут рассматриваться как статистики
. Вычисление "статистик" - классический пример представления "одним числом" сложного стохастического процесса. Статистики также являются случайными переменными. Распределения статистик (тест-распределения) лежат в основе критериев, которые построены на этой статистике. Например, В.Госсет, работая на пивоварне Гиннеса и публикуясь под псевдонимом “Стьюдент”, в 1908 г. доказал очень полезные свойства распределения отношения разности между выборочным средним и средним значением генеральной совокупности (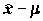 ) к стандартной ошибке среднего значения генеральной совокупности
) к стандартной ошибке среднего значения генеральной совокупности 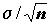 , или t –статистики (распределение Стьюдента):
, или t –статистики (распределение Стьюдента):
 . (5.7)
. (5.7)
Распределение Стьюдента по форме при некоторых условиях приближается к нормальному.
Другими двумя важными распределениями выборочных статистик является c
2-распределение и F-распределение, широко используемые в последующих разделах для проверки статистических гипотез. Основоположники математической статистики

Дадим определения и опишем основные свойства наиболее известных вероятностных распределений для дискретной случайной величины.
Случайная величина имеет распределение Бернулли с параметрами
P
{Х = 1} = p = 1 – P{Х = 0}В терминах плотности
f(x) это можно записать в следующем виде:f
(x) = f(x | p) = pxq1-x, x = {0,1}, q = 1 – p .Пусть {
X1, …, Xn} – бернуллиевская последовательность с параметром p. Тогда сумма X = X1 + …+ Xn имеет биномиальное распределение с параметрами n и p: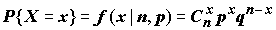 , x = 0, 1,…, (5.9)
, x = 0, 1,…, (5.9)
Термин "биномиальное распределение" связан с тем, что вероятности
P являются членами известного "бинома Ньютона":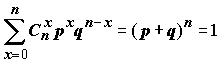
Таким образом, биномиальная модель
Bi(n, p) описывает распределение числа "успехов" в n испытаниях Бернулли с неизменной вероятностью "успеха" p.Среднее и дисперсия такой случайной величины есть
Mx = n× p и Dx = n× p× q .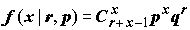 , x = 0, 1, 2,...(5.10)
, x = 0, 1, 2,...(5.10)
Заметим, что выражение
f(x | r, p) совпадает с х-м членом разложения функции qr(1 – p)-r в ряд по степеням р; т.е. отрицательного бинома (отсюда происходит и название распределения). Если случайная величина имеет распределение Bi(r, p), то первые два центральных момента равны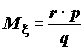 и
и 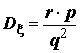 .
.
В частном случае при
r = 1 распределение Bi(1, p) называется геометрическим: это есть распределение числа частиц, предшествующих первому нулю в бернуллиевской последовательности: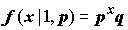 , x = 0, 1, 2,...(5.11)
, x = 0, 1, 2,...(5.11)
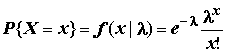 ,x = 0, 1, 2,… (5.12)
,x = 0, 1, 2,… (5.12)
При этом
Mx = Dx = l .Характер основных вероятностных распределений непрерывной и дискретной случайной величины представлен на рис. 5.1.
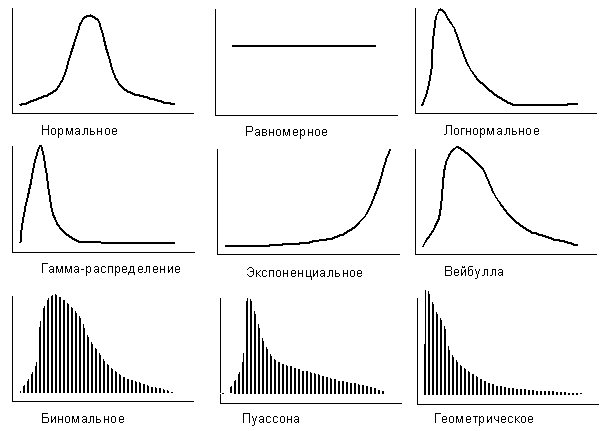
Рис. 5.1. Основные типы вероятностных распределений случайной величины
Проверка закона распределения эмпирического ряда
Обычно закон распределения случайной величины x неизвестен и его приближенно определяют (оценивают) опытным путем. С этой целью над величиной x
проводят ряд независимых испытаний. Вся мыслимая (т.е. бесконечная) совокупность этих измерений называется генеральной совокупностью. А каждый конкретный ряд измерений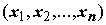 называют простой случайной выборкой.
называют простой случайной выборкой.
Если простую выборку упорядочить по возрастанию, то ее называют вариационным рядом. Если для каждого неповторяющегося элемента вариационного ряда
xi указать относительную частоту его появления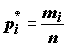 , то такой вариационный ряд называют статистическим рядом распределения случайной величины x
. Здесь mi –
число повторений xi (абсолютная частота появления элемента), а n –
общее число измерений, или объем выборки.
, то такой вариационный ряд называют статистическим рядом распределения случайной величины x
. Здесь mi –
число повторений xi (абсолютная частота появления элемента), а n –
общее число измерений, или объем выборки.
Имея вариационный ряд, легко построить эмпирическую (или статистическую) функцию распределения
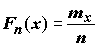 , где mX –
число членов вариационного ряда, лежащих левее от x, а mX/n –
частота попадания выборочного значения левее x. Fn(x) представляет собой ступенчатую неубывающую функцию, заданную на всей числовой оси, со скачками в точках xi, причем величина скачка равна частоте
, где mX –
число членов вариационного ряда, лежащих левее от x, а mX/n –
частота попадания выборочного значения левее x. Fn(x) представляет собой ступенчатую неубывающую функцию, заданную на всей числовой оси, со скачками в точках xi, причем величина скачка равна частоте 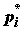 . Заметим, что поскольку сумма абсолютных частот
. Заметим, что поскольку сумма абсолютных частот 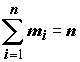 , то сумма относительных частот
, то сумма относительных частот 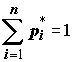 .
.
Согласно центральной теореме математической статистики – теоремы Гливенко - Кантелли о равномерной сходимости эмпирической функции распределения к истинной с ростом объема выборки, можно доказать, что
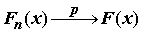 при n ®
¥
. Отсюда ясно, что эмпирическую функцию распределения можно использовать как оценку теоретической функции распределения F(x).
при n ®
¥
. Отсюда ясно, что эмпирическую функцию распределения можно использовать как оценку теоретической функции распределения F(x).
Совокупность разрядов и соответствующих частот статистического ряда геометрически изображают в виде гистограммы. По оси абсцисс откладывают интервалы и над каждым интервалом, как на основании, строят прямоугольник, высота которого равна значению плотности распределения для данного интервала
mi/n× h. Таким образом, площадь каждого прямоугольника гистограммы равна его частоте, а общая площадь равна единице.Большинство статистических вычислений сопровождается проверкой некоторых предположений или гипотез об источнике этих данных. Основное проверяемое предположение называется нулевой гипотезой и часто формулируется как отсутствие различий, незначительность влияния фактора, равенство нулю значений выборочных характеристик и т.п. Другое проверяемое предположение (не всегда строго противоположенное или обратное первому) называется конкурирующей или альтернативной гипотезой. Причина такого выделения нулевой гипотезы заключается в том, что она обычно рассматривается как утверждение, несостоятельность которого более бесспорно, чем истинность. Это основано на общем принципе, гласящем, что теория
должна быть отвергнута, если есть противоречащий пример, но не обязательно должна быть принята, если такого примера не удалось найти.Для проверки нулевой гипотезы задается статистический критерий
(от греч. kriterion - средство для суждения; мерило оценки), согласно которому вычисляется (по заданному правилу или формуле) значение соответствующей статистики и уровень значимости a , который представляет собой вероятность ошибочно отвергнуть нулевую гипотезу тогда, когда она на самом деле верна (так называемая, ошибка 1-го рода).Технически проверка нулевой гипотезы
H0 “нет статистически значимого различия” сводится к двум возможным операциям:Нулевая гипотеза
H0 не отклоняется, если вычисленное значение статистики критерия Крас не превышает порогового Кпор (первый случай), или если вычисленное значение a превышает критический уровень значимости a кр (второй случай). В противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза H1.При подборе распределений возникает вопрос: а верна ли гипотеза о том, что функция распределения именно
F(x), а не какая-либо другая? Выражаясь более точно, не противоречит ли гипотеза о законе распределения F(x) результатам эксперимента? Чтобы ответить на этот вопрос, пользуются критериями согласия. Под критерием согласия понимают некоторую величину D (Fn, F), которая отражает количественную меру расхождения гипотетического F(x) и эмпирического Fn(x) распределений. Величину разности между двумя распределениями можно выбрать многими способами и на ее основе имеются различные статистики для проверки интересующей нас гипотезы, например:статистика Колмогорова
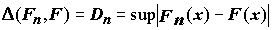 , (5.13)
, (5.13)
статистика омега-квадрат Мизеса
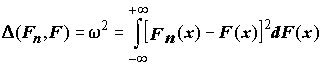 .(5.14)
.(5.14)
Схема применения критерия согласия следующая. Возьмем a
кр из a : (1 > a > 0) настолько малым, чтобы осуществление события с вероятностью, не превышающей a кр можно было считать практически невозможным в единичном опыте. Зная закон распределения случайной величины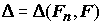 , найдем ее возможное значение D
0 из уравнения P(D
> D
0) = a
. По данной выборке вычислим значение критерия согласия
, найдем ее возможное значение D
0 из уравнения P(D
> D
0) = a
. По данной выборке вычислим значение критерия согласия 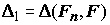 . Если окажется, что D
1 > D
0, то это значит, что произошло практически невероятное событие. Следовательно, эксперимент опровергает нашу гипотезу, и она отбрасывается. При этом вероятность того, что мы ошибочно отбросили верную гипотезу, не превышает принятый уровень значимости a
кр критерия и равна a
. Если D
1 < D
0, то гипотеза не противоречит эксперименту и должна быть принята.
. Если окажется, что D
1 > D
0, то это значит, что произошло практически невероятное событие. Следовательно, эксперимент опровергает нашу гипотезу, и она отбрасывается. При этом вероятность того, что мы ошибочно отбросили верную гипотезу, не превышает принятый уровень значимости a
кр критерия и равна a
. Если D
1 < D
0, то гипотеза не противоречит эксперименту и должна быть принята.
А.Н. Колмогоров в 1933 г. нашел предельную функцию распределения величины
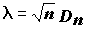 , которую для больших n можно вычислить по формуле:
, которую для больших n можно вычислить по формуле:
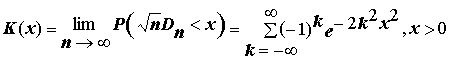 . (5.15)
. (5.15)
Функцию
K(x) стали называть критерием согласия Колмогорова. Затем Н.В.Смирнов исследовал супремум (sup) и инфимум (inf) этого эмпирического процесса, поэтому нередко встречается название "критерий Колмогорова-Смирнова".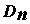 и вычислить величину
и вычислить величину 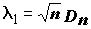 . Найти вероятность события
. Найти вероятность события 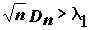 можно по формуле
можно по формуле
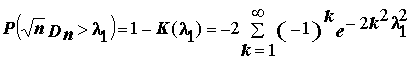 .(5.16)
.(5.16)
Если эта вероятность меньше a , то гипотеза отвергается, если больше, то признается не противоречащей эксперименту.
Предположим теперь, что из некоторых соображений мы можем высказать гипотезу только о виде закона распределения, а параметры, входящие в него, нам неизвестны. В таких случаях часто используют критерий согласия Пирсона
.Всю числовую ось разобьем на
r непересекающихся разрядов точками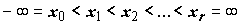 . Примем гипотезу о функции распределения, а неизвестные параметры, входящие в нее, заменим их оценками. Таким образом, гипотетическая функция распределения F(x) будет полностью известна и можно будет найти вероятности
. Примем гипотезу о функции распределения, а неизвестные параметры, входящие в нее, заменим их оценками. Таким образом, гипотетическая функция распределения F(x) будет полностью известна и можно будет найти вероятности 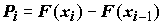 попадания случайной величины в i-й разряд. Возьмем статистику
попадания случайной величины в i-й разряд. Возьмем статистику
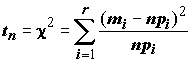 ,(5.17)
,(5.17)
где
n – объем выборки, r – число разрядов, mi – число значений в i-м разряде.За меру расхождения между гипотетической
F(x) и эмпирической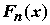 функциями распределения примем статистику
функциями распределения примем статистику 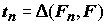 , определенную формулой (5.17). Р. Фишером с использованием метода максимального правдоподобия было доказано, что предельным законом распределения статистики
, определенную формулой (5.17). Р. Фишером с использованием метода максимального правдоподобия было доказано, что предельным законом распределения статистики 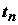 является распределение
является распределение 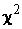 с
с 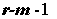 степенями свободы, где m –
число параметров, входящих в гипотетическую функцию распределения. Доказано также, что при объеме выборки n > 30 с достаточной точностью можно пользоваться предельным законом распределения, если
степенями свободы, где m –
число параметров, входящих в гипотетическую функцию распределения. Доказано также, что при объеме выборки n > 30 с достаточной точностью можно пользоваться предельным законом распределения, если 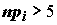 .
.
Схема применения критерия Пирсона следующая. По приведенным выше формулам вычисляют значение статистики
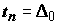 и вероятность
и вероятность
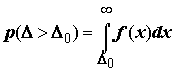 .(5.18)
.(5.18)
Если эта вероятность меньше уровня значимости a , то гипотезу следует отбросить.
Специально для проверки нормальности распределения малых выборок, численностью от 3 до 50 вариант, разработан
W критерий Шапиро и Уилка (Shapiro–Wilk), основанный на распределении порядковых статистик [Хан, Шапиро, 1969]. Этот критерий при наличии ограниченного объема данных является более мощным для проверки гипотезы нормальности, чем применяемые обычно критерии согласия [Лисенков, 1979].Вычисления производятся по формулам:
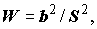
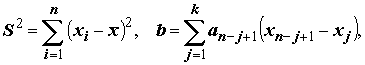 (5.19)
(5.19)
где
xi – ранжированный ряд, i = 1,2,…, n ;k = n / 2, если n – четное, или k = (n – 1) / 2, если n – нечетное;
an–j
+1 – константы (j = 1,2,…,k), протабулированные для n от 3 до 50.P
-значение вычисляется по формуле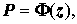 где Ф(.) – функция стандартного нормального распределения, а величина z = z(W) рассчитывается как
где Ф(.) – функция стандартного нормального распределения, а величина z = z(W) рассчитывается как 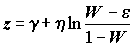 , где греческими буквами обозначены табулированные константы.
, где греческими буквами обозначены табулированные константы.
Применение критериев согласия связано с определенными теоретическими и вычислительными сложностями. Поэтому для решения вопроса о возможности применения тех или иных параметрических тестов и методов дисперсионного анализа иногда считается удобным использовать группу критериев, которые позволяют оценить отклонение некоторых широко известных характеристик эмпирического ряда от нормального закона распределения. Например, в литературе [Айвазян с соавт., 1983] описан
d-критерий Гири (Джири, Giri), вычисляемый по формулам: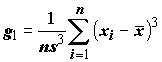 ;
; 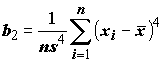 ;
; 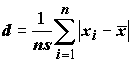 ,(5.20)
,(5.20)
использующим выборочную дисперсию
s2, асимметрию g1 и эксцесс b2.Результаты расчетов
Распределение численности и биомассы организмов в пробах характеризуется определенными статистическими законами, обусловленными как совокупностью абиотических факторов, так и влиянием внутрипопуляционых, межпопуляционных и межвидовых отношений. Оценку законов распределения гидробиологических показателей осуществим на основе данных из базы по малым рекам Самарской области (см. преамбулу к настоящей части книги). Для этого сформируем выборку из численности N экземпляров отдельных видов зообентоса, приходящихся на 1 м2 дна водоема, и биомассы В (г/м2). Отдельно рассчитаем суммарные численности Ns и биомассы Bs по каждой взятой пробе, а также индекс Шеннона H.
Из полученных выборок сформируем дополнительные выборки на основе некоторого подмножества функциональных преобразований (логарифмирование, возведение в различную степень и т.д.) исходных вариационных рядов [Тьюки, 1981; Шитиков с соавт., 1985; Цейтлин,
URL].Основные описательные статистики по полученным выборкам представлены в табл. 5.1. Гистограммы распределения некоторых показателей приведены на рис. 5.2.
Таблица 5.1
Основные описательные статистики по гидробиологическим показателям
|
Выборки |
Минимум |
Максимум |
Медиана |
Среднее |
Стандартное отклонение |
Асимметрия |
Эксцесс |
|
Численность по видам зообентоса ( N) – 5788 измерений |
|||||||
|
N |
1 |
71680 |
80.00 |
427.33 |
1724.90 |
19.3 |
617 |
|
N 1/2 |
1 |
267.73 |
8.94 |
13.57 |
15.58 |
4.1 |
30 |
|
N 1/3 |
1 |
41.54 |
4.308 |
5.19 |
3.47 |
2.34 |
8.9 |
|
ln(N) |
0 |
11.18 |
4.38 |
4.43 |
1.69 |
0.358 |
0.051 |
|
ln(N+1)1/2 |
1 |
3.48 |
2.31 |
2.3 |
.37 |
-0.177 |
0.392 |
|
Биомасса по видам зообентоса (В) – 5578 измерений |
|||||||
|
B |
0.01 |
6000 |
0.07 |
11.48 |
152.59 |
24.6 |
749 |
|
B 1/2 |
0.10 |
77.46 |
0.264 |
0.84 |
3.2818 |
12 |
186 |
|
B 1/3 |
0.215 |
18.17 |
0.412 |
0.669 |
1.052 |
7.69 |
79.2 |
|
ln(B) |
-4.6 |
8.7 |
-2.66 |
-2.29 |
2.160 |
1.2 |
2.08 |
|
ln(B+10)1/2 |
2.3 |
4.3 |
2.71 |
2.75 |
0.37 |
0.82 |
0.58 |
|
Индекс плотности населения ( N*B)1/2 - 5573 измерений |
|||||||
|
(N*B)1/2 |
0.1 |
4174 |
2.47 |
21.35 |
136.7 |
19.4 |
463 |
|
ln((N*B)1/2) |
-2.3 |
8.33 |
0.91 |
1.12 |
1.68 |
0.68 |
0.23 |
|
Суммарная численность Ns и биомасса Bs в пробе – 514 измерений |
|||||||
|
Ns |
20 |
216800 |
2000 |
5039 |
11736 |
12.17 |
208.2 |
|
ln(Ns) |
2.93 |
12.3 |
7.6 |
7.47 |
1.57 |
-0.303 |
-.1781 |
|
Bs |
0.01 |
12963.7 |
3.6 |
137.8 |
743 |
11.8 |
181 |
|
ln(Bs) |
-4.6 |
9.5 |
1.28 |
1.542 |
2.39 |
0.562 |
.5322 |
|
(Ns* Bs)1/2 |
0.63 |
10608 |
84.4 |
380.4 |
947.6 |
6.19 |
49.3230 |
|
ln(Ns*Bs)1/2 |
-0.46 |
9.3 |
4.43 |
4.5 |
1.78 |
-0.06 |
-0.226 |
|
Информационный индекс Шеннона H - 507 измерений |
|||||||
|
H |
0.115 |
4.193 |
2.32 |
2.244 |
0.796 |
-0.284 |
-0.153 |
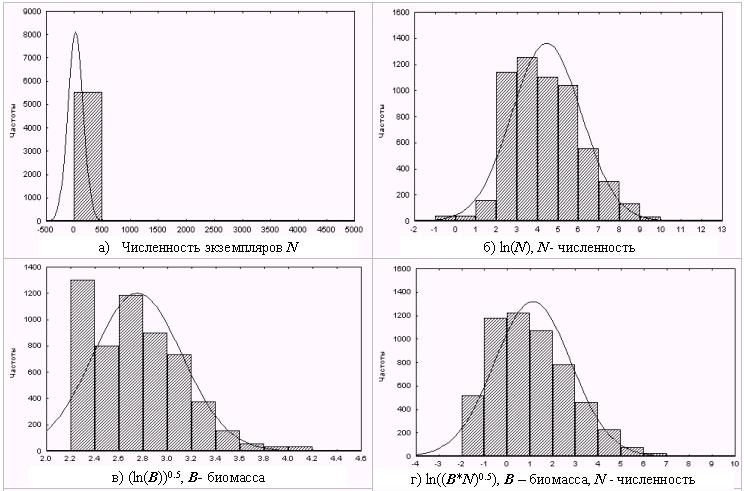
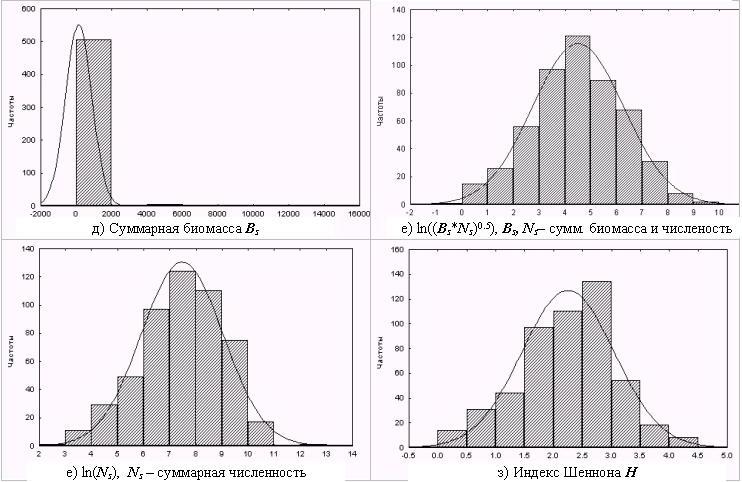
Рис. 5.2. Гистограммы распределения выборок из некоторых гидробиологических показателей и их функциональных преобразований
Представленные материалы позволяют сделать следующие выводы:
Выполним проверку простой статистической гипотезы о нормальном законе распределения представленных выборок с использованием критериев согласия Колмогорова и c 2 Пирсона, а также критерия эксцесса Гири d. Результаты расчетов для логарифмированных рядов суммарных численностей ln(Ns) и биомассы ln(Bs), индекса плотности населения ln((Ns*Bs)1/2) и индекса Шеннона H представлены в таб. 5.2.
Таблица 5.2
Результаты проверки гипотезы о нормальности распределения некоторых функций от численности
Ns и биомассы Bs зообентоса с помощью критериев согласия|
Выборка |
Dn |
l |
pl |
r |
c 2 |
c 2(0.05) |
pc |
pd |
|
ln(Ns) |
0.0367 |
0.833 |
0.492 |
8 |
15.32 |
15.5 |
0.053 |
0.48 |
|
ln(Bs) |
0.068 |
1.55 |
0.017 |
8 |
30.15 |
15.5 |
0.00019 |
~0 |
|
(Ns*Bs)1/2 |
0.344 |
7.8 |
~0 |
8 |
1046 |
15.5 |
~0 |
~0 |
|
ln((Ns*Bs)1/2) |
0.0215 |
0.487 |
0.989 |
8 |
4.64 |
15.5 |
0.794 |
0.219 |
|
Индекс Шеннона H |
0.0516 |
1.166 |
0.134 |
7 |
18.01 |
14.1 |
0.0119 |
0.202 |
Проверка нулевой гипотезы с помощью критериев согласия свидетельствует о том, что предположение о нормальном законе распределения может быть однозначно принято только для рядов ln((Ns*Bs)1/2) и ln(Ns). В разделе 4.3 было отмечено, что некоторые авторы ставят в заслугу информационной мере Шеннона именно нормальный характер распределения, что, в принципе, подтверждается и нашими расчетами: эта гипотеза отвергается только критерием c 2. Но, как видно из табл. 5.2, простое логарифмирование численностей часто приводит к лучшему результату (сравните на рис. 5.2 фиг. “е” и “ж” с “з”).
Для прочих рядов, не приведенных в табл. 5.2, гипотеза нормальности решительно отвергается, хотя тенденцию резкого снижения величин статистики Колмогорова l
= Dn× n1/2 при функциональном преобразовании численностей и биомассы отдельных видов бентоса легко проследить на рис. 5.3. Можно с большой уверенностью сказать, что эти ряды подчиняются логнормальному распределению: критерий Колмогорова для численности составляет Dn = 0.0048, для биомассы Dn = 0.0098, что позволяет с высоким уровнем значимости (р » 1) не отвергать гипотезу о логнормальном законе.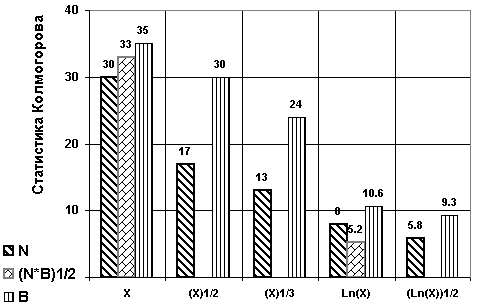
Рис. 5.3. Снижение статистики Колмогорова
Dn× n1/2 в результате функционального преобразования выборок численности N и биомассы B зообентосаПо литературным данным [Баканов, 2000а] для большинства видов бентосных организмов наиболее характерны отрицательное биномиальное или логнормальное распределения численности и биомассы, а при низком обилии – распределение Пуассона. Выполненные нами расчеты показали, что распределение численности и биомассы большинства видов с высоким уровнем значимости подчиняются логнормальному закону распределения (см. рис. 5.4 фиг. “а”). Проверка нулевой гипотезы при подборе остальных теоретических функций распределения дала однозначно отрицательные результаты. В частности, для численности
Dicrotendipes nervosus оказалась неудачной попытка аппроксимации геометрическим распределением (см. рис. 5.4 фиг. “б”), в то время, как верна гипотеза о логнормальном распределении (статистика Колмогорова равна 0.029, р » 0.85).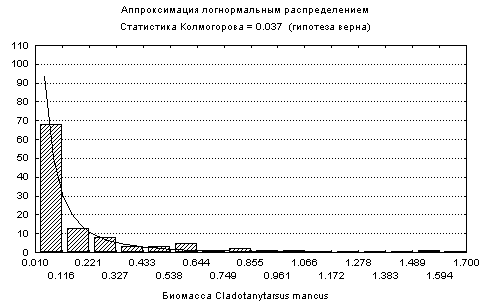
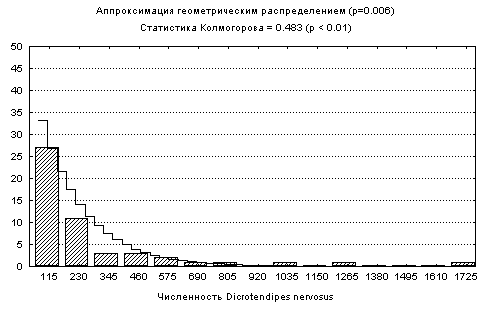
Рис 5.4. Подбор функции распределения показателей обилия некоторых видов бентоса
В некоторых работах [Gray, 1981; Мокеева, Межов, 1986] делаются выводы, о том что, параметры статистических распределений меняются при изменении условий обитания животных. Например, вследствие загрязнения или ином ухудшении условий, асимметрия увеличивается, а кривая распределения имеет несколько пиков, в то время как при улучшении условий обитания кривая имеет более ровный характер, а полимодальность отсутствует.
Нам не удалось ни подтвердить, ни опровергнуть эти суждения, поскольку осталось непонятным, относительно какого закона распределения следует оценивать коэффициент асимметрии, а надежных критериев оценки полимодальности найти не удалось. Действительно, визуально можно обнаружить на гистограммах рис. 5.5 некоторые проявления полимодальности, однако, насколько имеющиеся пики статистически значимы, еще следует доказать, используя механизм проверки гипотез.
В то же время, с характером распределения можно, при желании, связать ряд выводов об экологии вида, глубине "экологической ниши" и проч. Например, сравнивая закономерности распределения численностей на рис. 5.5а, можно усмотреть, что экологический "спектр"
Chironomus plumosus значительно шире, чем Prodiamesa olivacea, что объясняется широкой экологической валентностью первого вида и особенностями биологии хирономид [Зинченко, 2002].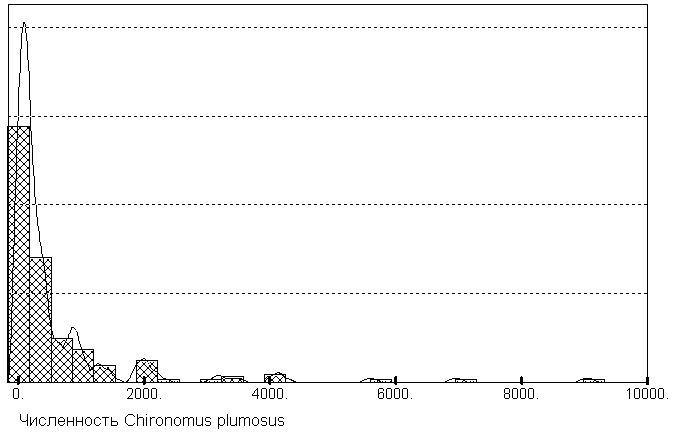
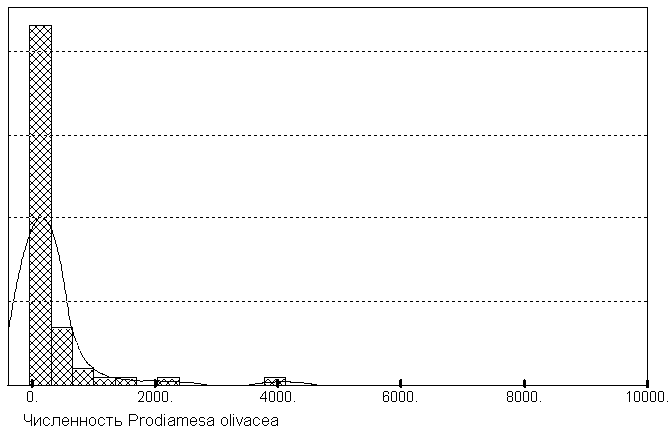
Рис 5.5а. Формы кривых распределения численностей некоторых видов бентоса
Аналогично, из гистограммы распределения биомассы личинок хирономид можно заметить различия, связанные с особенностями питания хищных
Cryptochironomus gr. defectus и факультативных фитофагов Procladius ferrugineus. Впрочем, кое-кому может показаться, что подобные упражнения сильно напоминают "гадания на кофейной гуще".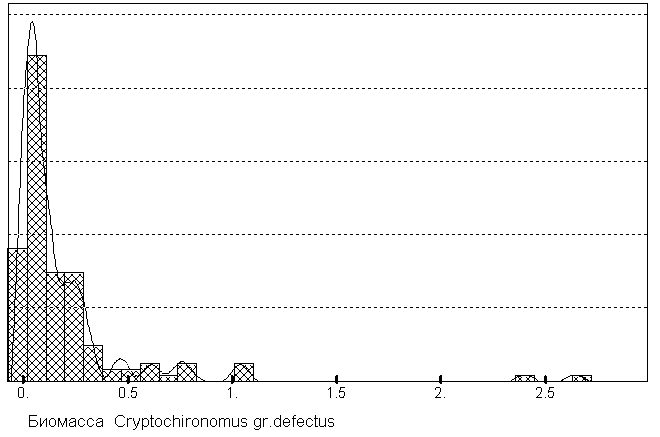

Рис 5.5б. Формы кривых распределения биомассы некоторых видов бентоса
| Дальше
|
Назад |
Начало |
Конец |
Список
|